A substitution of a comma with a period in project Mercury's working Fortran code compromised the accuracy of the results, rendering them unsuitable for longer orbital missions. How probable are such events and how does a programming language's design affect their likelihood and severity? In a paper I recently presented at the 4th Annual International Workshop on Evaluation and Usability of Programming Languages and Tools I showed results obtained by randomly perturbing similar programs written in diverse languages to see whether the compiler or run-time system would detect those changes as errors, or whether these would end-up generating incorrect output.
In a study jointly conducted with my colleagues Vassilios Karakoidas and Panagiotis Louridas we first chose ten popular programming languages, and a corpus of programs written in all of them. We selected the languages to test based on a number of sources collated in an IEEE Spectrum article: an index created by TIOBE (a software research firm), the number of book titles listed on Powell's Books, references in online discussions on IRC, and the number of job posts on Craigslist. From the superset of the popular languages listed in those sources we excluded some languages for practical reasons. According to the source of the popularity index, the coverage of the languages we ended-up selecting over all languages ranges from 71% to 86%.
We then obtained fragments of source code executing the same task in all of our study's ten languages from the Rosetta Code wiki. In the words of its creators, the site aims to present code for the same task in as many languages as possible, thus demonstrating their similarities and differences and aiding persons with a grounding in one approach to a problem in learning another.
Our next step involved constructing a source code mutation fuzzer: a tool that systematically introduces diverse random perturbations into the program's source code. The fuzzer substitutes identifiers, perturbs integers by one, changes random characters, or substitutes tokens with similar or random ones. Finally, we applied the fuzzing tool on the source code corpus and examined whether the resultant code had errors that were detected at compile or run time, and whether it produced erroneous results.
In practice, the errors that we artificially introduced into the source code can crop up in a number of ways. Mistyping-the "fat fingers" syndrome-is one plausible source. Other scenarios include absent-mindedness, automated refactorings gone awry (especially in languages, like C and C++, where such tasks cannot be reliably implemented), unintended consequences from complex editor commands or search-and-replace operations, and even the odd cat walking over the keyboard.
In total we tested 136 task implementations attempting 280,000 fuzzing operations, of which 261,667 (93%) were successful. From the fuzzed programs 90,166 (32%) compiled or were syntax-checked without a problem. From those programs 60,126 (67%, or 23% of the fuzzed total) terminated successfully. Of those 18,256 produced output identical to the reference one, indicating that the fuzz was inconsequential to the program's operation. The rest, 41,870 programs (70% of those that run, 16% of the fuzzed total), compiled and run without a problem, but produced wrong output.
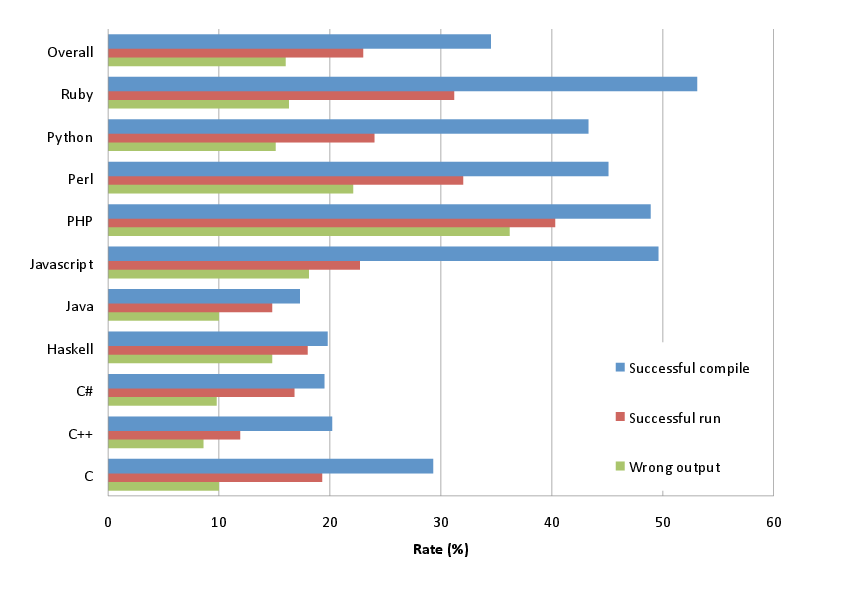
The figure above shows the aggregate results per language in the form of failure modes: successful compilations or executions, which consequently failed to catch an erroneous program and resulted in wrong results. The figure confirms a number of intuitive notions. Languages with strong static typing (Java, Haskell, C++) caught more errors at compile time than languages with weak or dynamic type systems (Ruby, Python, Perl, PHP, and JavaScript). Somewhat predictably, C fell somewhere in the middle, confirming a widely-held belief that its type system is not as strong as many of its adherents (including myself) think it is. However, C produced a higher number of run-time errors, which in the end resulted in a rate of incorrect output similar to that of the other strongly-typed languages.
A picture similar to that of compile-time errors is also apparent for run time behavior. Again, code written in weakly-typed languages is more probable to run without a problem (a crash or an exception) than code written in languages with a strong type system. As one would expect these two differences result in a higher rate of wrong output from programs written in languages with weak typing. With an error rate of 36% for PHP against one of 8% for C++ and 10% for C#, those writing safety-critical applications should carefully weight the usability advantages offered by a weakly-type language, like PHP, against the increased risk that a typo will slip undetected into production code. Overall, the figures for dynamic scripting languages show a far larger degree of variation compared to the figures of the strongly static typed ones. This is probably a result of a higher level of experimentation associated with scripting language features.
We also performed a statistical analysis of the results and found the following things.
- The different results in fuzz tests between statically compiled and dynamic languages are to a large extent statistically significant. This validates the finding in the Figure that less errors escape detection in static languages than dynamic.
- C# behaves more like C and C++ and less like Java, despite its surface similarities to the latter.
- Haskell behaves more similarly to Java than other languages.
- There are clusters of failures to show a significant difference between statically checked languages: C and C++, C++ and Java, Haskell and Java. However, we do not see a comparable pattern in dynamic languages. To paraphrase Tolstoy, it would seem that they are different in their own ways.
Reference: Diomidis Spinellis, Vassilios Karakoidas, and Panagiotis Louridas. Comparative language fuzz testing: Programming languages vs. fat fingers. In PLATEAU 2012: 4th Annual International Workshop on Evaluation and Usability of Programming Languages and Tools — Systems, Programming, Languages and Applications: Software for Humanity (SPLASH 2012). ACM, October 2012.
Comments Post Toot! Tweet


Why I Choose Email Over Messaging (2025-09-26)
Is it legal to use copyrighted works to train LLMs? (2025-06-26)
I'm removing the BSD advertising clause (2025-05-20)
The perils of GenAI student submissions (2025-04-11)
Unix make vs Apache Airflow (2024-10-15)
How (and how not) to present related work (2024-08-05)
An exception handling revelation (2024-02-05)
Extending the life of TomTom wearables (2023-09-01)
How AGI can conquer the world and what to do about it (2023-04-13)
Last modified: Wednesday, December 5, 2012 10:40 am
Unless otherwise expressly stated, all original material on this page created by Diomidis Spinellis is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.