If the code and the comments disagree, then both are probably wrong.
— Norm Schryer
I can still remember the first time I laid my eyes on production-quality source code. This was in the early 1980s and the code was the BIOS listing of the original IBM PC. The 5940 lines of code spanned 80 neatly typeset pages in a three-ring slip-covered binder. Two things made a lasting impression on me. The first was the elation of being able to read, understand and learn from the code that made a real machine tick. This may have sparked my current practical and research interests in open source software. The second, was the way the code was commented. The BIOS was written in 8086 assembly language, and almost every line had a comment on its right hand side. By poring over the code and its comments I learned 8086 assembly, programming style, and understood the PC’s hardware architecture.
Comments, identifiers, and whitespace
Figure 1. A program as a code blob: a BASIC Interpreter
So how important are comments in the programs we write? To answer this question I set out to measure the percentage of source code size occupied by comments in a few programs. It then occurred to me that comments are only one of the mechanisms we developers use to communicate with our colleagues through the source code. Other mechanisms are the creation of meaningful identifiers, the laying out of the program with whitespace, the use of language-provided high-level abstractions, and the development of our own abstractions. To get a feeling of how important these mechanisms are, have a look at Figure 1 listing a BASIC interpreter implemented in 1536 bytes. I wrote that program with the express goal to communicate as little information as possible, in order to submit it to the 1990 International Obfuscated C Code Contest. The code uses single-letter identifiers, employs minimal whitespace, and doesn’t contain any pesky comments. This is the type of code that can keep us awake at night; a literal and metaphorical nightmare.
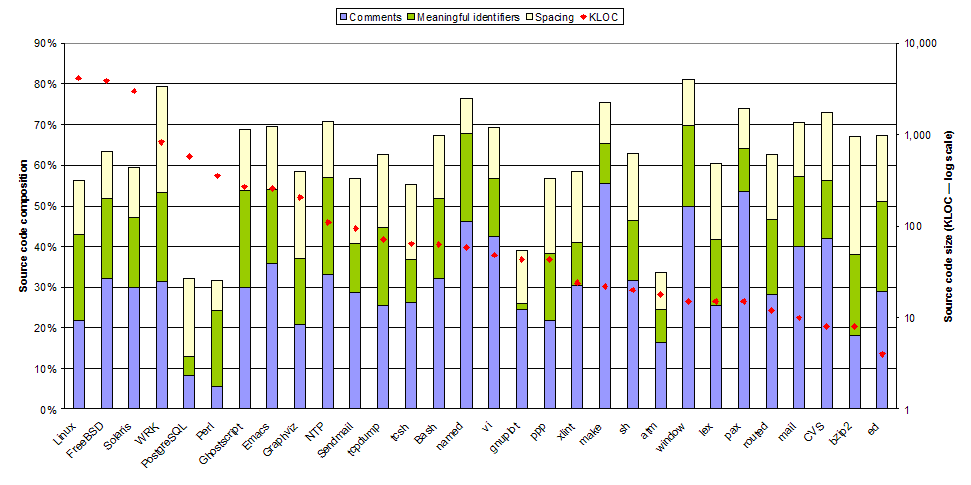
Figure 2. Developer-oriented elements in the composition of source code
To see how we use these three mechanisms in practice, I took 30 programs of various sizes and measured what percentage of their source code consisted of comments and whitespace. I also calculated the percentage of source code size devoted to meaningful identifiers by counting the number of (non-library) unique identifiers, then deriving the minimum number of characters required for expressing them, and finally obtaining the corresponding source code size savings we could obtain by using the smallest possible identifier names. (It turns out that for programs up to 15 thousand lines of code (KLOC) you can get away with two-character identifiers, and for all but the three largest systems I measured—the Linux, Solaris, and FreeBSD kernels—three-character identifiers are perfectly adequate. And this calculation is conservative, because I ignored the savings one can obtain by reusing identifiers in different scopes. Malfeasant programmers and language designers take note.) You can see a graphical summary of this small study in Figure 2.
I found the results surprising: in the source code of a typical system more than 50% of the code serves not as instructions to the computer, but as a communications vehicle targeting developers. Furthermore, although we often discuss the importance of comments (this was my original idea for this column), it seems that programmers devote to meaningful identifiers and even the humble whitespace almost the same area of screen real estate. Therefore presumably, all three mechanisms are equally important. In addition, although I was expecting that the measured composition of a program’s elements would differ according to a program’s size, my data didn’t show such a variation for programs spanning a range from millions to thousands of code lines. It seems that for any non-trivial program each of these three mechanisms carries equal weight; one could well posit that this reflects a stylistic equilibrium we reached through evolution. Finally, although the ratio of code serving the developers rather than the compiler seems high, note that it doesn’t even include the overhead of code employed for building and using various abstractions, such as method definitions and calls. Although some abstractions can result in more compact code, my feeling is that on balance abstractions (deservedly) contribute positively to a system’s source code size.
Implications
I don’t think that anybody in their right mind would ever dream of writing or even representing the Linux kernel as a blob similar to that in Figure 1 (at least not before reading this column). Nevertheless, I find the large part of the source code that is explicitly targeting developers profoundly significant, because it confirms my belief that source code is the most important artifact of the software development process. Programming is not coding. Programming is not the mechanical transfer of a software design into a form the computer can execute. As many others have observed, programming is an art, and the three elements I’ve measured are separate identifiable artistic expressions. The writing of comments is prose literature, aiming to tell the story behind the code. The formation of layout through whitespace is sculpture, seeking to show the code’s hidden structure. Finally, the choice of meaningful identifiers is almost stylized poetry: a type of creative communication through a few words adhering to a specific form. Our overarching goal is to communicate effectively: plainly, succinctly, and unambiguously.
The large amount of creativity that goes into the software source code has several practical implications. It means that we can get great code by hiring talented developers, and compensating them in the form we would pay a great artist (ideally not the archetypal starving one). It also means that we should take care of code, treating it as a prized possession. We should learn, respect, apply, and preserve style guidelines and naming conventions; we should treat each comment as part of an essay that will be marked by the most exacting English teacher we’ve ever had.
To paraphrase William Ward: The mediocre code compiles. The good code runs. The superior code passes tests and inspections. The great code inspires.
* This piece has been published in the IEEE Software magazine Tools of the Trade column, and should be cited as follows: Diomidis Spinellis. The Way We Program. IEEE Software, 25(4):89–91, July/August 2008. (doi:10.1109/MS.2008.101) Comments Post Toot! Tweet


Unix make vs Apache Airflow (2024-10-15)
How (and how not) to present related work (2024-08-05)
An exception handling revelation (2024-02-05)
Extending the life of TomTom wearables (2023-09-01)
How AGI can conquer the world and what to do about it (2023-04-13)
Twitter's overrated dissemination capacity (2023-04-02)
The hypocritical call to pause giant AI (2023-03-30)
AI deforests the knowledge’s ecosystem (2023-03-16)
How I fixed git-grep macOS UTF-8 support (2022-10-12)
Last modified: Thursday, June 26, 2008 12:40 am
This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.