Computers allow us to measure objectively the properties of text. I applied some established text and sentiment analysis algorithms on Donald Trump’s inaugural address and compared the results with the same metrics of past well-known presidents. Presidential speeches are nowadays typically a team effort. Nevertheless, I thought that the speech writing team’s output reflects the president’s choices regarding staffing, policy, and style. Moreover, as luck would have it, in this case it was reported that Donald Trump wrote the inaugural address himself. The findings of this exercise surprised me.
Number of words
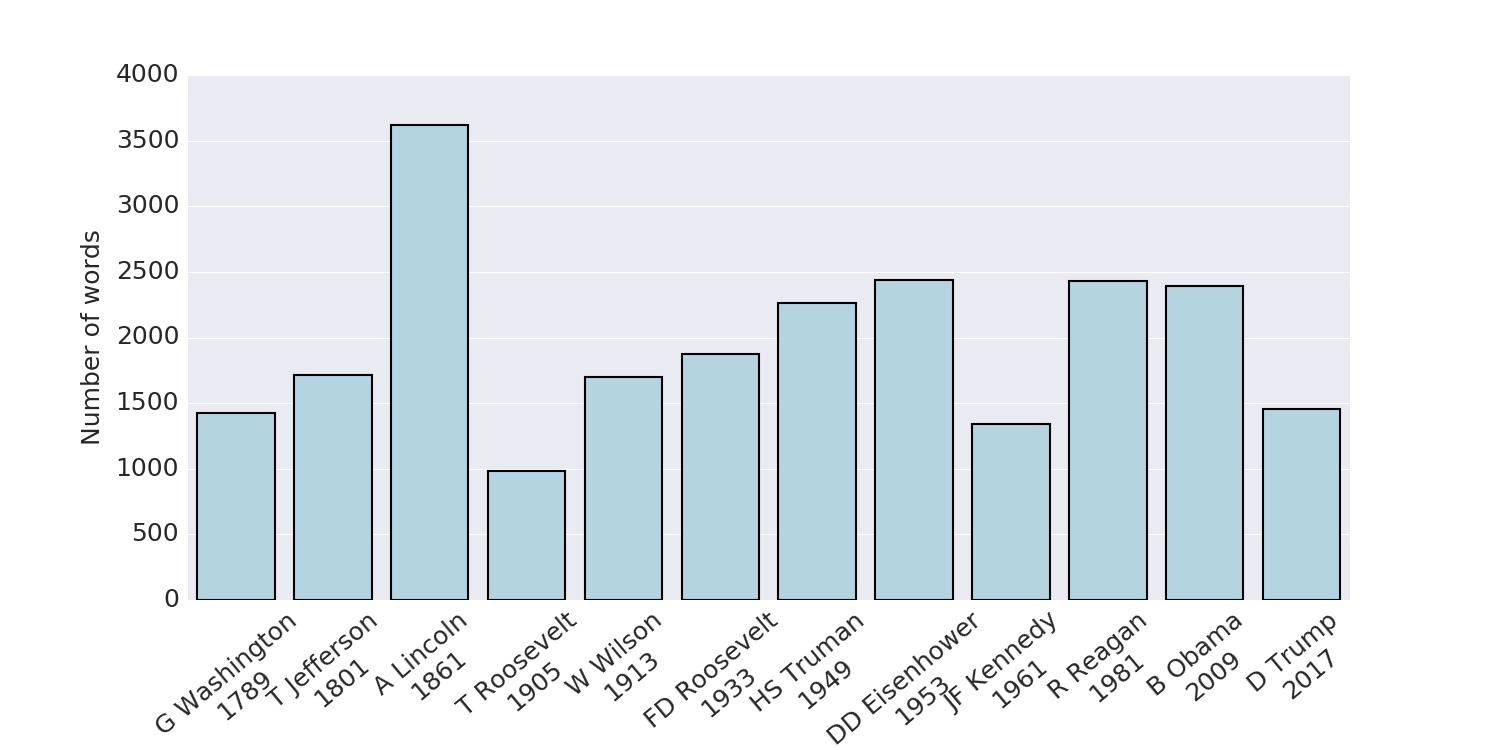 Presidential inaugural addresses have
varied considerably in length.
The longest one was William Henry Harrison’s 1841 address at 8460
words, while the shortest one was George Washington’s 1793 second
inaugural address at just 135 words.
Fittingly for a habitually tweeting president,
at 1500 words Trump’s address is shorter than most of the other
speeches I used in my comparison.
Presidential inaugural addresses have
varied considerably in length.
The longest one was William Henry Harrison’s 1841 address at 8460
words, while the shortest one was George Washington’s 1793 second
inaugural address at just 135 words.
Fittingly for a habitually tweeting president,
at 1500 words Trump’s address is shorter than most of the other
speeches I used in my comparison.
SMOG index
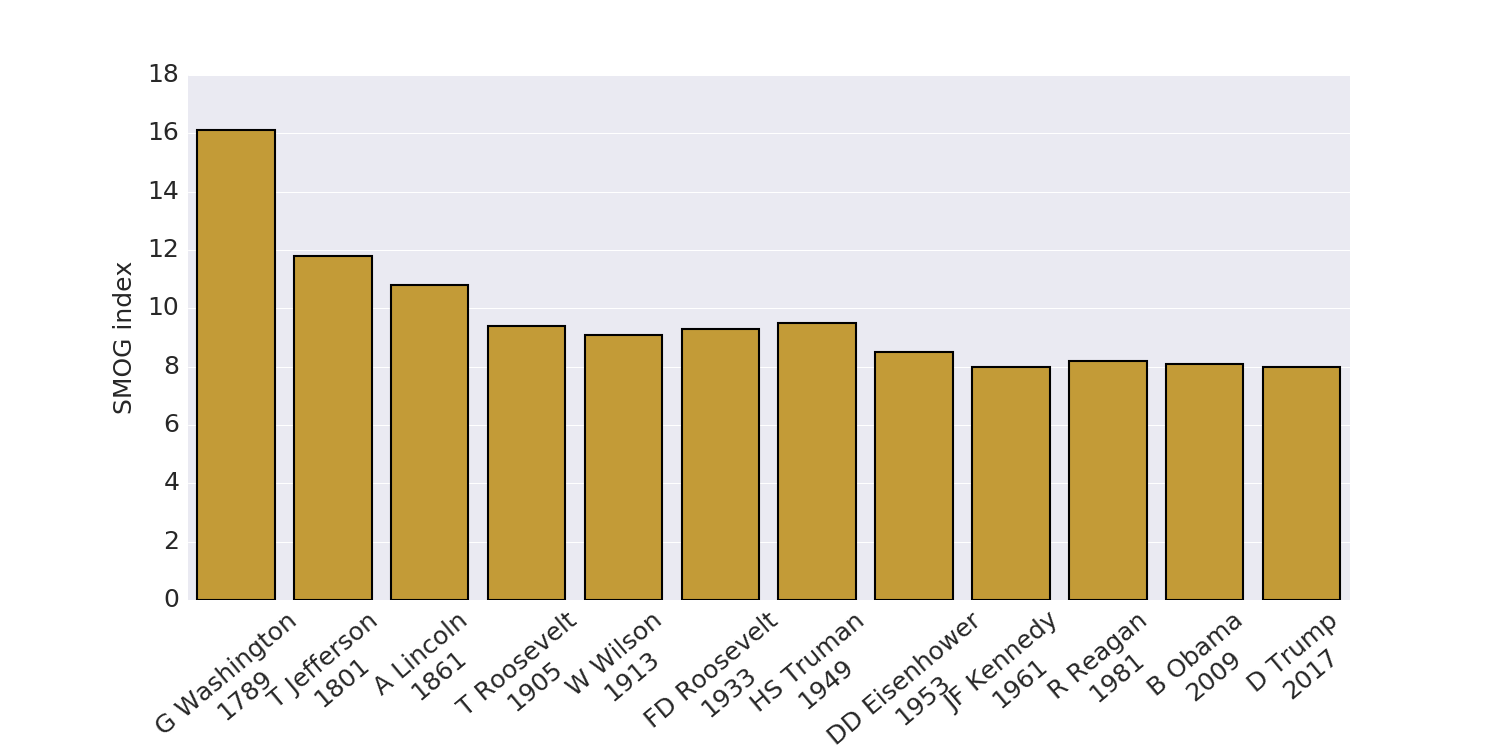 The SMOG
(Simple Measure of Gobbledygook) grade of a text measures its
readability as an estimate of the years of education needed
to understand it.
It is based on the ratio between the number of polysyllable words
(those of three or more syllables) and the number of sentences.
The SMOG grade is often used to evaluate consumer-oriented health material,
such as text written for patients.
We see that this measure decreases over the years.
Based on an analysis of Trump’s victory speech, I expected the readability
index of his inaugural address to be dramatically lower than the inaugural
speeches of previous presidents.
It isn’t.
It seems that Trump has employed an expressive style
compatible with the occasion.
The SMOG
(Simple Measure of Gobbledygook) grade of a text measures its
readability as an estimate of the years of education needed
to understand it.
It is based on the ratio between the number of polysyllable words
(those of three or more syllables) and the number of sentences.
The SMOG grade is often used to evaluate consumer-oriented health material,
such as text written for patients.
We see that this measure decreases over the years.
Based on an analysis of Trump’s victory speech, I expected the readability
index of his inaugural address to be dramatically lower than the inaugural
speeches of previous presidents.
It isn’t.
It seems that Trump has employed an expressive style
compatible with the occasion.
Subjectivity
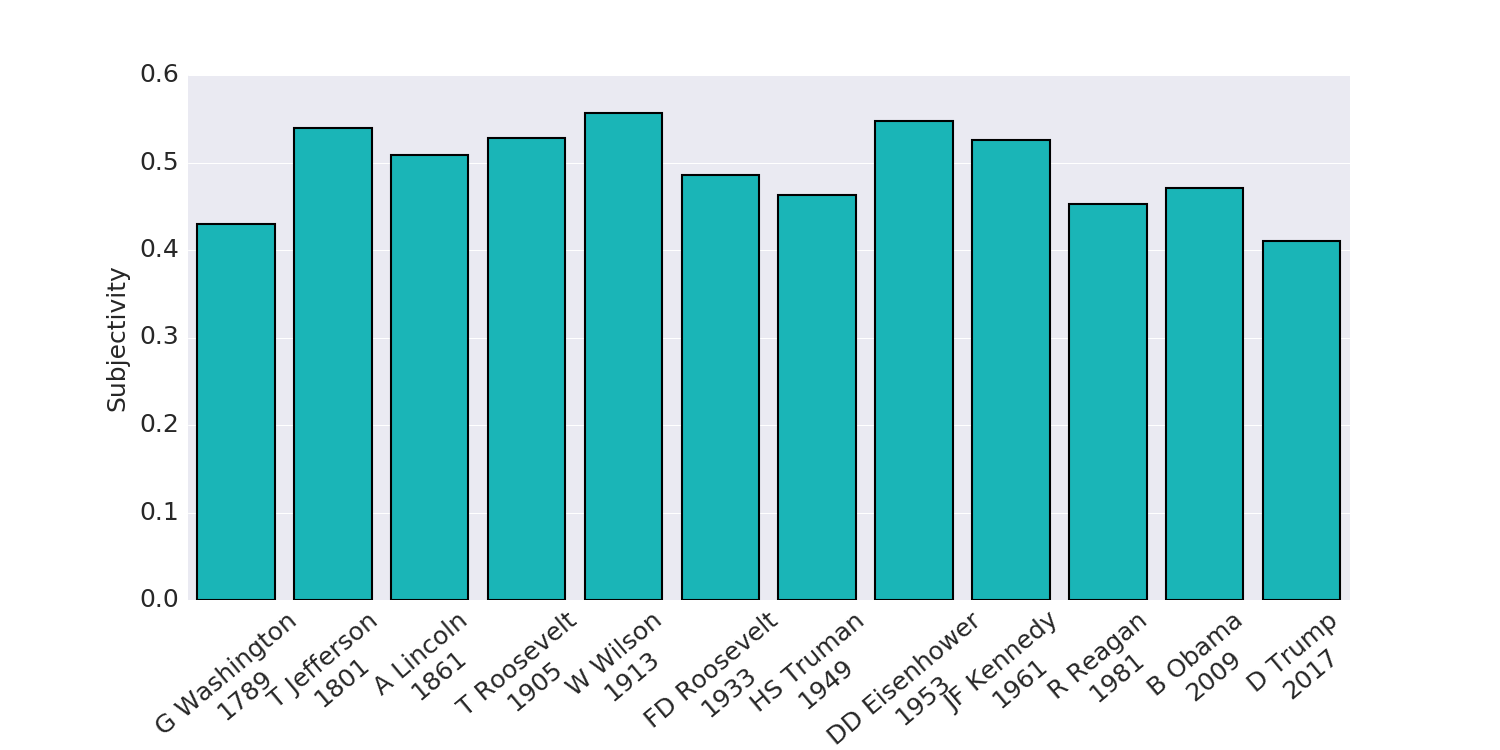 The subjectivity text sentiment index
is based on classifying each sentence
as objective or subjective.
It ranges from 0 (completely objective, think of Star Trek’s Dr. Spock)
to 1 (fully subjective).
Surprisingly for a candidate whose campaign slogan was
Make America Great Again, Trump’s address scores as more “objective” than any of the other
addresses in the set I used.
Keep in mind that this is an automatically generated metric,
rather than a reasoned analysis of the speech’s argumentation.
The subjectivity text sentiment index
is based on classifying each sentence
as objective or subjective.
It ranges from 0 (completely objective, think of Star Trek’s Dr. Spock)
to 1 (fully subjective).
Surprisingly for a candidate whose campaign slogan was
Make America Great Again, Trump’s address scores as more “objective” than any of the other
addresses in the set I used.
Keep in mind that this is an automatically generated metric,
rather than a reasoned analysis of the speech’s argumentation.
Sentimental polarity
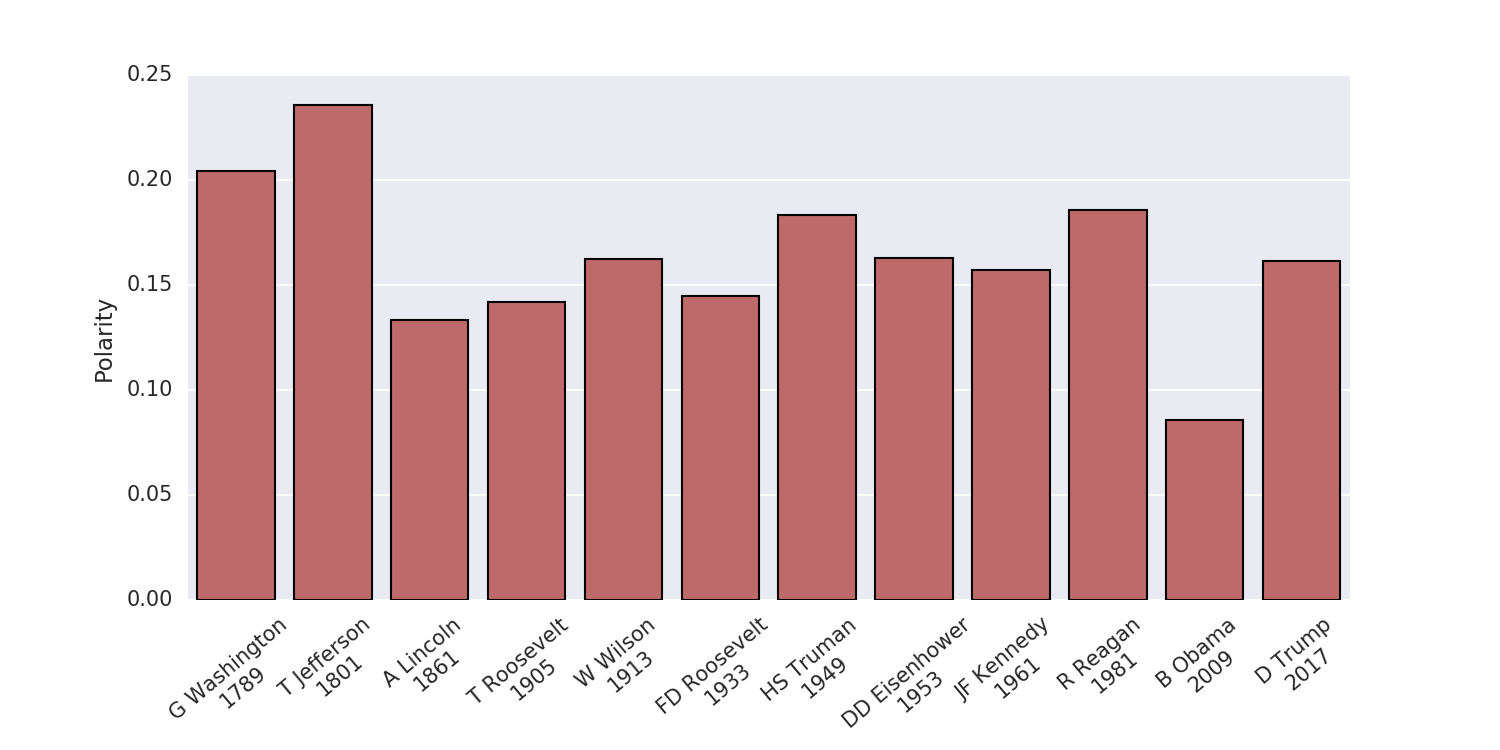 The polarity text sentiment index
classifies the text between negative
(less than zero) and positive (greater than zero) sentiments.
As one might expect, inaugural addresses are more or less positive.
Compared to the other ones I selected, Trump’s is on the high
side, but not excessively so.
What is remarkable, is the big difference between Trump’s 2017 address
and Barack Obama’s 2009 one.
It seems that Trump correctly sensed the US public’s desire for
a positive outlook and a corresponding message.
It remains to be seen whether he can deliver on those promises.
The polarity text sentiment index
classifies the text between negative
(less than zero) and positive (greater than zero) sentiments.
As one might expect, inaugural addresses are more or less positive.
Compared to the other ones I selected, Trump’s is on the high
side, but not excessively so.
What is remarkable, is the big difference between Trump’s 2017 address
and Barack Obama’s 2009 one.
It seems that Trump correctly sensed the US public’s desire for
a positive outlook and a corresponding message.
It remains to be seen whether he can deliver on those promises.
Lexical variety
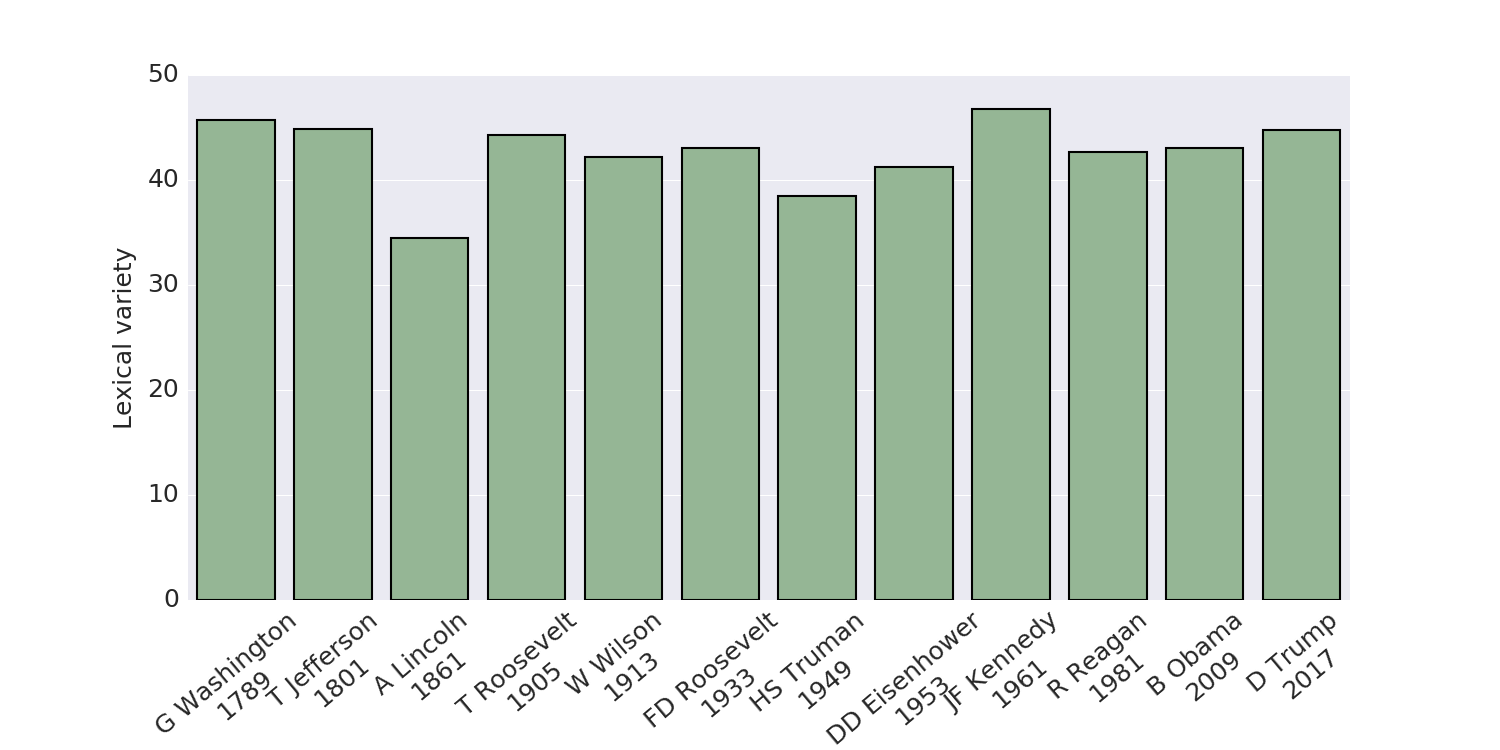 The lexical variety metric
measures the word richness of a text as
the percentage ratio between the text’s unique words and all the words
in the text.
In this, so-called Type-to-Token Ratio (TTR),
lower values mean lower lexical variety.
During his campaign Trump
was criticised for his lack of gravitas,
even by media that traditionally favors the GOP.
The figures here paint a different picture.
His inaugural address used a (slightly) larger variety of words
than those of many others, including A Lincoln, W Wilson, FD Roosevelt,
HS Truman, DD Eisenhower, R Reagan, and B Obama.
The lexical variety metric
measures the word richness of a text as
the percentage ratio between the text’s unique words and all the words
in the text.
In this, so-called Type-to-Token Ratio (TTR),
lower values mean lower lexical variety.
During his campaign Trump
was criticised for his lack of gravitas,
even by media that traditionally favors the GOP.
The figures here paint a different picture.
His inaugural address used a (slightly) larger variety of words
than those of many others, including A Lincoln, W Wilson, FD Roosevelt,
HS Truman, DD Eisenhower, R Reagan, and B Obama.
Conclusion
When I embarked on this exercise, I was expecting to find big differences in the metrics associated with Trump’s inaugural address compared to those of his famous predecessors. I based this idea both on the public perception of Donald Trump as a populist and on my preliminary findings from an analysis of Trump’s victory speech compared to that of Barack Obama. Trump’s victory speech had a lower by 1.1 SMOG index (6.7 vs 7.8) and used 300 polysyllabic words compared to Obama’s 390.
Given Trump’s famous public lashings against anyone who criticizes him,
at times I even considered the possibility of finding myself as the
subject of one of his infamous tweets:
Spinellis's code that analysed my speech IS FULL OF BUGS. VERY UNFAIR.
The results surprised me: apart from the sentimental polarity,
which was remarkably higher than that of Obama’s address,
the speech’s metrics appeared quite close to those of Trump’s predecessors.
The text analysis metrics by themselves point to a more
measured and humdrum inaugural speech than what one would expect
from Trump’s flamboyant and at times divisive election campaign.
It would be foolish to read too much from these findings. Donald Trump in his inaugural address painted an isolationist, protectionist, and transactional view of global relations. His transition and first actions as president are worrying. If anything, the findings show the limits of textual and sentiment analysis. As Andreas Kouloukoulis commented, this post is “another great example of why quantitative analyses are useless without qualitative backgrounds explaining the stats. What matters is not only the text of the speech but the context under which it is given. […] In the era of the quantified self, the quantified society and the quantified everything, it’s easy to lose focus on how complex reality actually is.”
Method
I selected the presidents used for the comparison from a composite list of previous presidential rankings by scholars, which New York Times journalist and statistician Nate Silver of FiveThirtyEight created in January 2013. To the list I added Barack Obama, as the preceding president. I obtained the inaugural addresses from Yale Law School’s Avalon Project. For presidents who gave more than one inaugural address, I selected their first one.
I hand-edited the downloaded files to remove headers and footers, and then used Unix shell commands to convert the files into plain text.
# Remove HTML markup
sed -i 's/<[^>]*>//g' *
# Change file name suffix to that of text files
ls | sed 's/\(.*\)\.asp.htm/git mv "\1.asp.htm" "\1.txt"/' | shFinally, I wrote a program in Python to obtain the metrics and draw the diagrams. You can find the source code and the text of the inaugural addresses on GitHub, distributed under an open source software license.
I’m grateful to Panos Louridas and Alexios Zavras for helpful suggestions and comments.
Comments Post Toot! Tweet


Why I Choose Email Over Messaging (2025-09-26)
Is it legal to use copyrighted works to train LLMs? (2025-06-26)
I'm removing the BSD advertising clause (2025-05-20)
The perils of GenAI student submissions (2025-04-11)
Unix make vs Apache Airflow (2024-10-15)
How (and how not) to present related work (2024-08-05)
An exception handling revelation (2024-02-05)
Extending the life of TomTom wearables (2023-09-01)
How AGI can conquer the world and what to do about it (2023-04-13)
Last modified: Saturday, January 21, 2017 8:49 am
Unless otherwise expressly stated, all original material on this page created by Diomidis Spinellis is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.