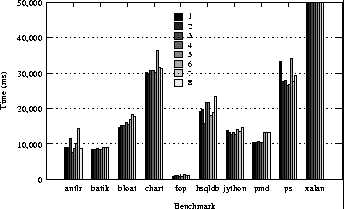
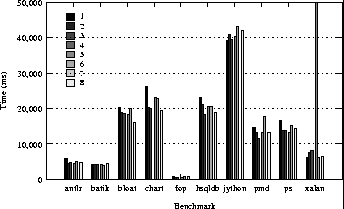
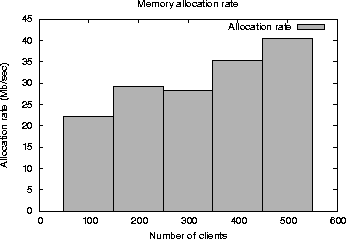
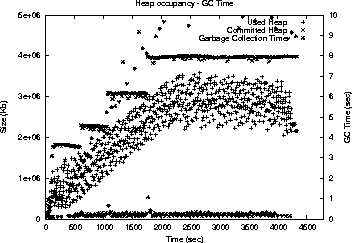
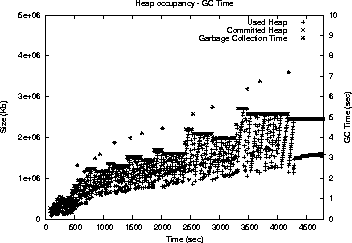
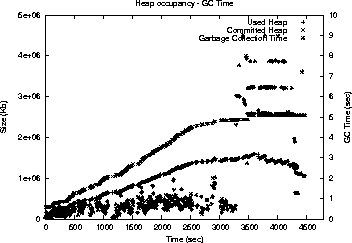
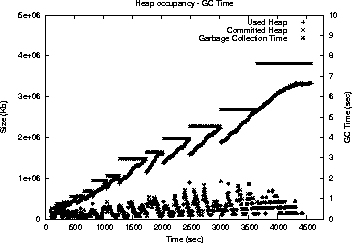
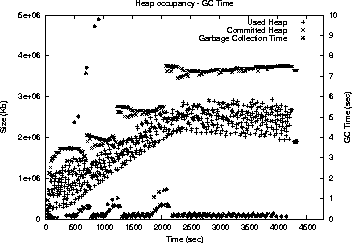
This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
- Giorgos Gousios,
Vassilios Karakoidas, and Diomidis Spinellis.
Tuning
Java's memory manager for high performance server applications.
In Alexios Zavras, editor, Proceedings of the 5th
International System Administration and Network Engineering Conference SANE
06, pages 69–83. NLUUG, Stichting SANE, May 2006.