|
http://www.spinellis.gr/pubs/jrnl/2004-ACMCS-p2p/html/AS04.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
© ACM, 2004. This is the author's version of the work. It is posted here by permission of ACM for your personal use. Not for redistribution. The definitive version was published in ACM Computing Surveys, 36(4):335-371, December 2004. http://doi.acm.org/10.1145/1041680.1041681
Categories and Subject Descriptors: C.2.1 [Computer-Communication Networks]: Network Architecture and Design-Network topology; C.2.2 [Computer- Communication Networks]: Network Protocols-Routing protocols; C.2.4 [Computer-Communication Networks]: Distributed Systems-Distributed databases; H.2.4 [Database Management]: Systems-Distributed databases; H.3.4 [Information Storage and Retrieval]: Systems and Software-Distributed systems General Terms: Algorithms, Design, Performance, Reliability, Security Additional Key Words and Phrases: Content distribution, DOLR, DHT, grid computing, p2p, peer-to-peer
Peer-to-peer systems are distributed systems consisting of interconnected nodes able to self-organize into network topologies with the purpose of sharing resources such as content, CPU cycles, storage and bandwidth, capable of adapting to failures and accommodating transient populations of nodes while maintaining acceptable connectivity and performance without requiring the intermediation or support of a global centralized server or authority.The above definition is meant to encompass "degrees of centralization" ranging from the pure, completely decentralized systems such as Gnutella, to "partially centralized" systems2 such as Kazaa. However, for the purposes of this survey, we shall not restrict our following presentation and discussion of architectures and systems to our own proposed definition, and we will take into account systems that are considered peer-to-peer by other definitions as well, including systems that employ a centralized server (such as Napster, instant messaging applications, and others). The focus of our study is content distribution, a significant area of peer-to-peer systems that has received considerable research attention.
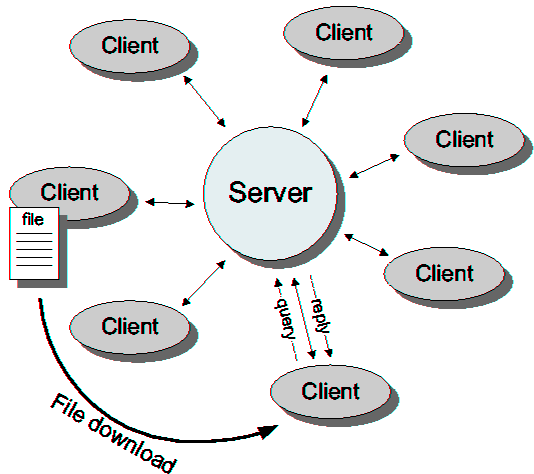
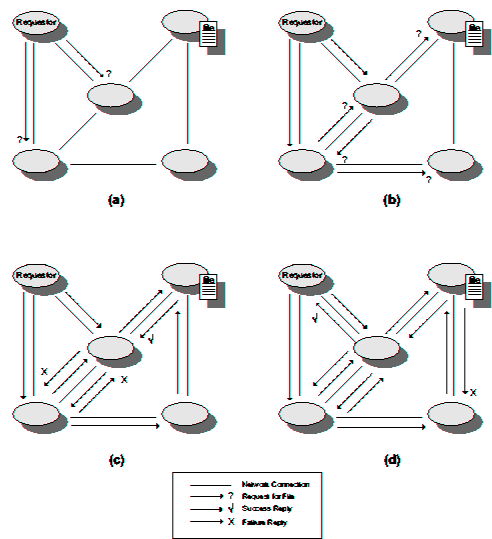
| Peer-to-Peer File Exchange Systems | |||
|
| ||
|
| ||
|
| ||
|
| ||
| Peer-to-Peer Content Publishing and Storage Systems | |||||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
|
|
| |||
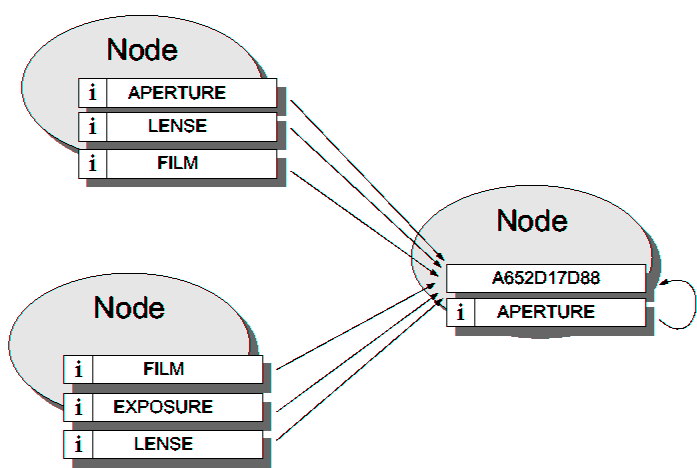
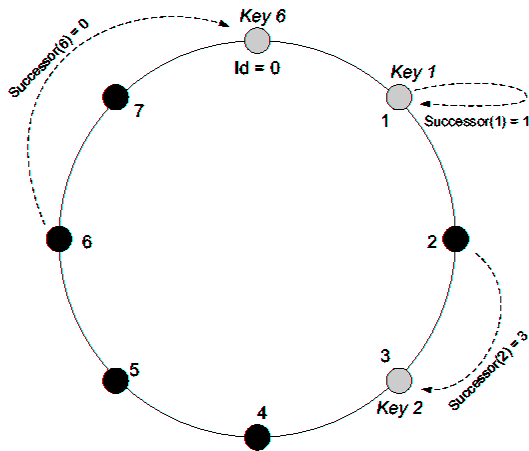
| Infrastructures for routing and location | |||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
| Infrastructures for anonymity | |||
|
| ||
|
| ||
|
| ||
|
| ||
| Infrastructures for reputation management | |||
|
| ||
|
| ||
|
| ||
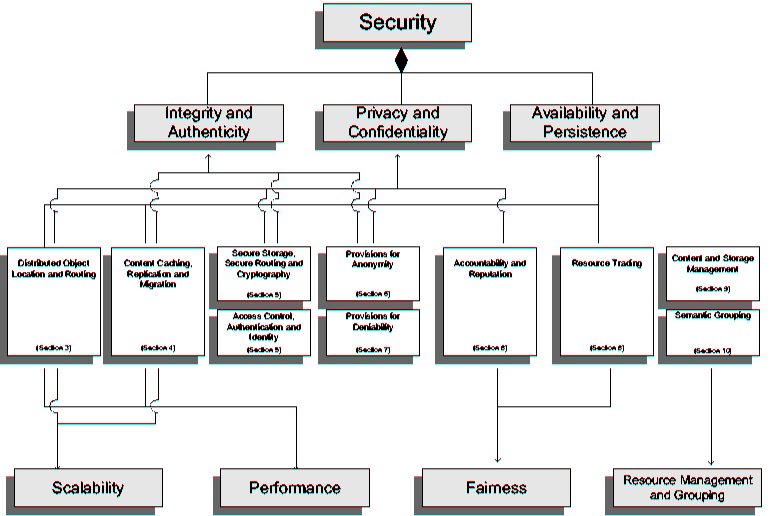
| Centralization | |||||||
| Hybrid | Partial | None | |||||
|
|
|
| ||||
|
| ||||||
|
| ||||||
![CAN: (a) Example 2-d [0,1]×[0,1] coordinate space partitioned between 5 CAN nodes; (b) Example 2-d space after node F joins](can1a.png)
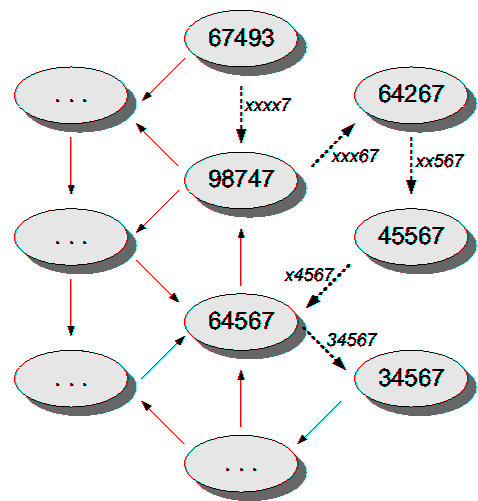
| Level 5 | Level 4 | Level 3 | Level 2 | Level 1 | |
| Entry 0 | 07493 | x0493 | xx093 | xxx03 | xxxx0 |
| Entry 1 | 17493 | x1493 | xx193 | xxx13 | xxxx1 |
| Entry 2 | 27493 | x2493 | xx293 | xxx23 | xxxx2 |
| Entry 3 | 37493 | x3493 | xx393 | xxx33 | xxxx3 |
| Entry 4 | 47493 | x4493 | xx493 | xxx43 | xxxx4 |
| Entry 5 | 57493 | x5493 | xx593 | xxx53 | xxxx5 |
| Entry 6 | 67493 | x6493 | xx693 | xxx63 | xxxx6 |
| Entry 7 | 77493 | x7493 | xx793 | xxx73 | xxxx7 |
| Entry 8 | 87493 | x8493 | xx893 | xxx83 | xxxx8 |
| Entry 9 | 97493 | x9493 | xx993 | xxx93 | xxxx9 |
|
|