dgsh — directed graph shell
The directed graph shell, dgsh (pronounced /dæɡʃ/ — dagsh), provides an expressive way to construct sophisticated and efficient big data set and stream processing pipelines using existing Unix tools as well as custom-built components. It is a Unix-style shell (based on bash) allowing the specification of pipelines with non-linear non-uniform operations. These form a directed acyclic process graph, which is typically executed by multiple processor cores, thus increasing the operation's processing throughput.
If you want to get a feeling on how dgsh works in practice, skip right down to the examples section.
For a more formal introduction to dgsh or to cite it in your work,
see:
Diomidis Spinellis and Marios Fragkoulis.
Extending Unix Pipelines to DAGs.
IEEE Transactions on Computers, 2017.
doi: 10.1109/TC.2017.2695447
Inter-process communication
Dgsh provides two new ways for expressing inter-process communication.
- Multipipes
- are expressed as usual Unix pipelines,
but can connect commands with more than one output or input channel.
As an example, the
commcommand supplied with dgsh expects two input channels and produces on its output three output channels: the lines appearing only in first (sorted) channel, the lines appearing only in the second channel, and the lines appearing in both. Connecting the output of thecommcommand to thecatcommand supplied with dgsh will make the three outputs appear in sequence, while connecting it to thepastecommand supplied with dgsh will make the output appear in its customary format. - Multipipe blocks {{ ... }}
-
a) send (multiple) input streams
received on their input side to the asynchronously-running
processes that reside within the block, and,
b) pass the output produced by the processes within the block as
(multiple) streams on their output side.
Multipipe blocks typically receive input from more than one channel
and produce more than one output channel.
For example, a multipipe block that runs
md5sumandwc -creceives two inputs and produces two outputs: the MD5 hash of its input and the input's size. Data to multipipe blocks are typically provided with a dgsh-aware version ofteeand collected by dgsh-aware versions of programs such ascatandpaste. - Stored values
- offer a convenient way for communicating
computed values between arbitrary processes on the graph.
They allow the storage of a data stream's
last record into a named buffer.
This record can be later retrieved asynchronously by one or more readers.
Data in a stored value can be piped into a process or out of it, or it can be read
using the shell's command output substitution syntax.
Stored values are implemented internally through Unix-domain sockets,
a background-running store program,
dgsh-writeval, and a reader program,dgsh-readval. The behavior of a stored value's IO can be modified by adding flags todgsh-writevalanddgsh-readval.
Syntax
A dgsh script follows the syntax of a bash(1) shell script with the addition of multipipe blocks. A multipipe block contains one or more dgsh simple commands, other multipipe blocks, or pipelines of the previous two types of commands. The commands in a multipipe block are executed asynchronously (in parallel, in the background). Data may be redirected or piped into and out of a multipipe block. With multipipe blocks dgsh scripts form directed acyclic process graphs. It follows from the above description that multipipe blocks can be recursively composed.
As a simple example consider running the following command directly within dgsh
{{ echo hello & echo world & }} | paste
or by invoking dgsh with the command as an argument.
dgsh -c '{{ echo hello & echo world & }} | paste'
The command will run paste with input from the two
echo processes to output hello world.
This is equivalent to running the following bash command,
but with the flow of data appearing in the natural left-to-right order.
paste <(echo hello) <(echo world)
In the following larger example, which compares the performance of
different compression utilities, the script's standard input
is distributed to
three compression utilities (xz, bzip2, and gzip),
to assess their performance, and also to
file and wc to report the input data's type and size.
The printf commands label the data of each processing type.
All eight commands pass their output
to the cat command, which gathers their outputs
in order.
tee |
{{
printf 'File type:\t'
file -
printf 'Original size:\t'
wc -c
printf 'xz:\t\t'
xz -c | wc -c
printf 'bzip2:\t\t'
bzip2 -c | wc -c
printf 'gzip:\t\t'
gzip -c | wc -c
}} |
cat
Formally, dgsh extends the syntax of the (modified) Unix Bourne-shell
when bash provided with the --dgsh argument
as follows.
<dgsh_block> ::= '{{' <dgsh_list> '}}'
<dgsh_list> ::= <dgsh_list_item> '&'
<dgsh_list_item> <dgsh_list>
<dgsh_list_item> ::= <simple_command>
<dgsh_block>
<dgsh_list_item> '|' <dgsh_list_item>
Adapted tools
A number of Unix tools have been adapted to support multiple inputs and outputs to match their natural capabilities. This echoes a similar adaptation that was performed in the early 1970s when Unix and the shell got pipes and the pipeline syntax. Many programs that worked with files were adjusted to work as filters. The number of input and output channels of dgsh-compatible commands are as follows, based on the supplied command-line arguments.
| Tool | Inputs | Outputs | Notes |
|---|---|---|---|
| cat (dgsh-tee) | 0—N | 0—M | No options are supported |
| cmp | 0—2 | 0—1 | |
| comm | 0—2 | 0—3 | Output streams in order: lines only in first file, lines only in second one, and lines in both files |
| cut | 0—1 | 1—N | With --multistream output each range into a different stream |
| diff | 0—N | 1 | Typically two inputs. Compare an arbitrary number of input streams with the --from-file or --to-file options |
| diff3 | 0—3 | 1 | |
| grep | 0—2 | 0—4 | Available output streams (via arguments): matching files, non-matching files, matching lines, and non-matching lines |
| join | 0—2 | 1 | |
| paste | 0—N | 1 | Paste N input streams |
| perm | 1—N | 1—N | Rearrange the order of N input streams |
| sort | 0—N | 0—1 | With the -m option, merge sort N input streams |
| tee (dgsh-tee) | 0—N | 0—M | Only the -a option is supported |
| dgsh-readval | 0 | 1 | Read a value from a socket |
| dgsh-wrap | 0—N | 0—1 | Wrap non-dgsh commands and negotiate on their behalf |
| dgsh-writeval | 1 | 0 | Write a value to a socket |
In addition, POSIX user commands that receive no input
or only generate no output, when executed in a dgsh context
are wrapped to specify the corresponding input or output capability.
For example, an echo command in a multipipe block
will appear to receive no input, but will provide one output stream.
By default dgsh automatically wraps all other
commands as filters.
- Input-only
- read, write.
- Output-only
- alias, ar, basename, c99, cal, cflow, command, date, df, dirname, du, echo, expr, find, getopts, ipcrm, jobs, ls, make, man, printf, ps, pwd, tty, type, ulimit, umask, uname, what, who.
Finally, note that any dgsh script will accept and generate the number of inputs and outputs associated with the commands or multipipe blocks at its two endpoints.
Downloading and installation
The dgsh suite has been tested under Debian and Ubuntu Linux, FreeBSD, and Mac OS X. A Cygwin port is underway.
An installation of GraphViz will allow you to visualize the dgsh graphs that you specify in your programs.
Debian and Ubuntu GNU/Linux
Prerequisites
To compile and run dgsh you will need to have the following commands installed on your system:
make automake gcc libtool pkg-config texinfo help2man autopoint bison check gperf git xz-utils gettextTo test dgsh you will need to have the following commands installed in your system:
wbritish wamerican libfftw3-dev csh curl bzip2
Installation steps
Go through the following steps.
-
Recursively clone the project's source code through its
GitHub page.
git clone --recursive https://github.com/dspinellis/dgsh.git
-
Configure bash and the Unix tools adapted for dgsh.
make config
-
Compile all programs.
make
-
Install.
sudo make install
By default, the program and its documentation are installed under
/usr/local.
You can modify this by setting the PREFIX variable
in the `config` step, for example:
make PREFIX=$HOME config make make install
Testing
Issue the following command.
make test
FreeBSD
Prerequisites
To compile and run dgsh you will need to have the following packages installed in your system:
devel/automake devel/bison devel/check devel/git devel/gmake devel/gperf misc/help2man print/texinfo shells/bashTo test dgsh you will need to have the following ports installed on your system:
archivers/bzip2 ftp/curl
Installation steps
Go through the following steps.
-
Recursively clone the project's source code through its
GitHub page.
git clone --recursive https://github.com/dspinellis/dgsh.git
-
Configure bash and the Unix tools adapted for dgsh.
gmake config
-
Compile all programs.
gmake
-
Install.
sudo gmake install
By default, the program and its documentation are installed under
/usr/local.
You can modify this by setting the PREFIX variable
in the `config` step, for example:
gmake PREFIX=$HOME config gmake gmake install
Testing
Issue the following command.
gmake test
Reference documentation
These are the manual pages for dgsh, the associated helper programs and the API in formats suitable for browsing and printing. The commands are listed in the order of usefulness in everyday scenarios.
- dgsh
- directed graph shell HTML, PDF
- dgsh-tee
- buffer and copy or scatter standard input to one or more sinks HTML, PDF
- dgsh-wrap
- allow any filter program to participate in an dgsh pipeline HTML, PDF
- dgsh-writeval
- write values to a data store HTML, PDF
- dgsh-readval
- data store client HTML, PDF
- dgsh-monitor
- monitor data on a pipe HTML, PDF
- dgsh-parallel
- create a semi-homongeneous dgsh parallel processing block HTML, PDF
- perm
- permute inputs to outputs HTML, PDF
- dgsh-httpval
- provide data store values through HTTP HTML, PDF
- dgsh-merge-sum
- merge key value pairs, summing the values HTML, PDF
- dgsh-conc
- input or output pipe concentrator for dgsh negotiation (used internally) HTML, PDF
- dgsh-enumerate
- enumerate an arbitrary number of output channels (demonstration and debugging tool) HTML, PDF
- dgsh_negotiate
- API for dgsh-compatible programs to specify and obtain dgsh I/O file descriptors HTML, PDF
Examples
Compression benchmark
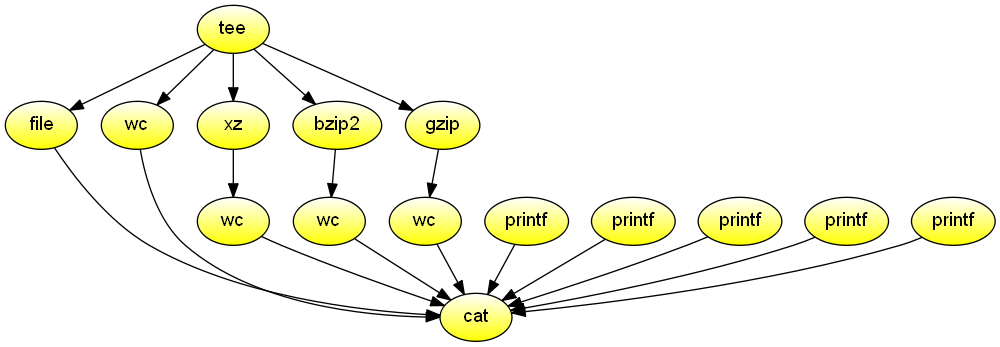
Report file type, length, and compression performance for data received from the standard input. The data never touches the disk. Demonstrates the use of an output multipipe to source many commands from one followed by an input multipipe to sink to one command the output of many and the use of dgsh-tee that is used both to propagate the same input to many commands and collect output from many commands orderly in a way that is transparent to users.
#!/usr/bin/env dgsh
tee |
{{
printf 'File type:\t'
file -
printf 'Original size:\t'
wc -c
printf 'xz:\t\t'
xz -c | wc -c
printf 'bzip2:\t\t'
bzip2 -c | wc -c
printf 'gzip:\t\t'
gzip -c | wc -c
}} |
cat
Git commit statistics
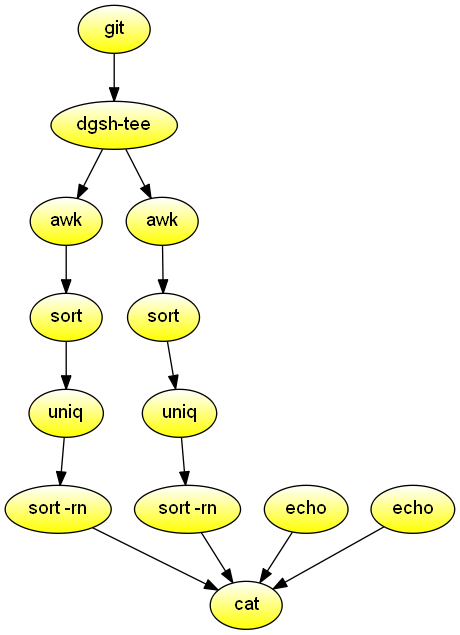
Process the Git history, and list the authors and days of the week ordered by the number of their commits. Demonstrates streams and piping through a function.
#!/usr/bin/env dgsh
forder()
{
sort |
uniq -c |
sort -rn
}
git log --format="%an:%ad" --date=default "$@" |
tee |
{{
echo "Authors ordered by number of commits"
# Order by frequency
awk -F: '{print $1}' |
forder
echo "Days ordered by number of commits"
# Order by frequency
awk -F: '{print substr($2, 1, 3)}' |
forder
}} |
cat
C code metrics
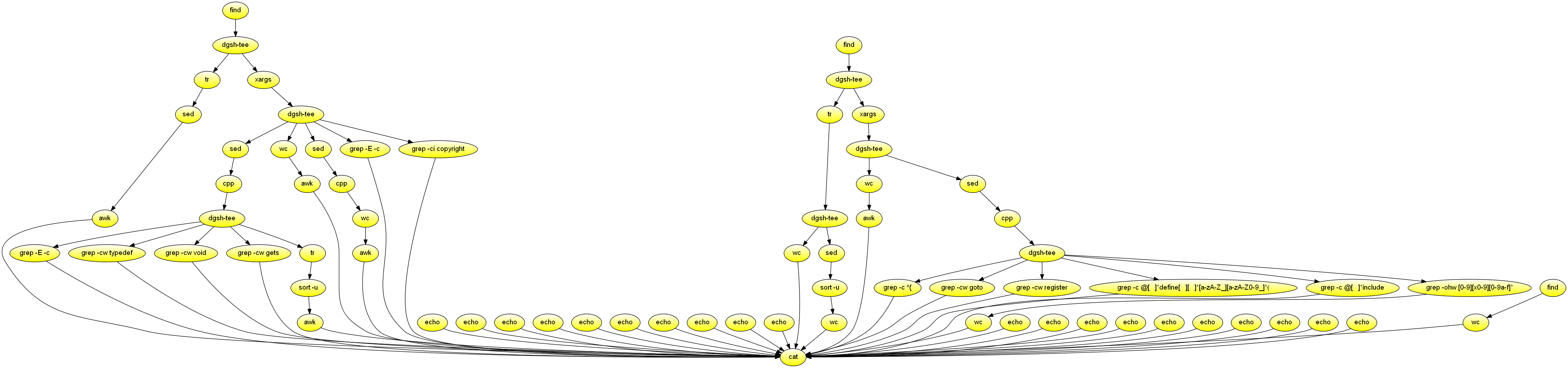
Process a directory containing C source code, and produce a summary of various metrics. Demonstrates nesting, commands without input.
#!/usr/bin/env dgsh
{{
# C and header code
find "$@" \( -name \*.c -or -name \*.h \) -type f -print0 |
tee |
{{
# Average file name length
# Convert to newline separation for counting
echo -n 'FNAMELEN: '
tr \\0 \\n |
# Remove path
sed 's|^.*/||' |
# Maintain average
awk '{s += length($1); n++} END {
if (n>0)
print s / n;
else
print 0; }'
xargs -0 /bin/cat |
tee |
{{
# Remove strings and comments
sed 's/#/@/g;s/\\[\\"'\'']/@/g;s/"[^"]*"/""/g;'"s/'[^']*'/''/g" |
cpp -P |
tee |
{{
# Structure definitions
echo -n 'NSTRUCT: '
egrep -c 'struct[ ]*{|struct[ ]*[a-zA-Z_][a-zA-Z0-9_]*[ ]*{'
#}} (match preceding openings)
# Type definitions
echo -n 'NTYPEDEF: '
grep -cw typedef
# Use of void
echo -n 'NVOID: '
grep -cw void
# Use of gets
echo -n 'NGETS: '
grep -cw gets
# Average identifier length
echo -n 'IDLEN: '
tr -cs 'A-Za-z0-9_' '\n' |
sort -u |
awk '/^[A-Za-z]/ { len += length($1); n++ } END {
if (n>0)
print len / n;
else
print 0; }'
}}
# Lines and characters
echo -n 'CHLINESCHAR: '
wc -lc |
awk '{OFS=":"; print $1, $2}'
# Non-comment characters (rounded thousands)
# -traditional avoids expansion of tabs
# We round it to avoid failing due to minor
# differences between preprocessors in regression
# testing
echo -n 'NCCHAR: '
sed 's/#/@/g' |
cpp -traditional -P |
wc -c |
awk '{OFMT = "%.0f"; print $1/1000}'
# Number of comments
echo -n 'NCOMMENT: '
egrep -c '/\*|//'
# Occurences of the word Copyright
echo -n 'NCOPYRIGHT: '
grep -ci copyright
}}
}}
# C files
find "$@" -name \*.c -type f -print0 |
tee |
{{
# Convert to newline separation for counting
tr \\0 \\n |
tee |
{{
# Number of C files
echo -n 'NCFILE: '
wc -l
# Number of directories containing C files
echo -n 'NCDIR: '
sed 's,/[^/]*$,,;s,^.*/,,' |
sort -u |
wc -l
}}
# C code
xargs -0 /bin/cat |
tee |
{{
# Lines and characters
echo -n 'CLINESCHAR: '
wc -lc |
awk '{OFS=":"; print $1, $2}'
# C code without comments and strings
sed 's/#/@/g;s/\\[\\"'\'']/@/g;s/"[^"]*"/""/g;'"s/'[^']*'/''/g" |
cpp -P |
tee |
{{
# Number of functions
echo -n 'NFUNCTION: '
grep -c '^{'
# Number of gotos
echo -n 'NGOTO: '
grep -cw goto
# Occurrences of the register keyword
echo -n 'NREGISTER: '
grep -cw register
# Number of macro definitions
echo -n 'NMACRO: '
grep -c '@[ ]*define[ ][ ]*[a-zA-Z_][a-zA-Z0-9_]*('
# Number of include directives
echo -n 'NINCLUDE: '
grep -c '@[ ]*include'
# Number of constants
echo -n 'NCONST: '
grep -ohw '[0-9][x0-9][0-9a-f]*' | wc -l
}}
}}
}}
# Header files
echo -n 'NHFILE: '
find "$@" -name \*.h -type f |
wc -l
}} |
# Gather and print the results
cat
Find duplicate files
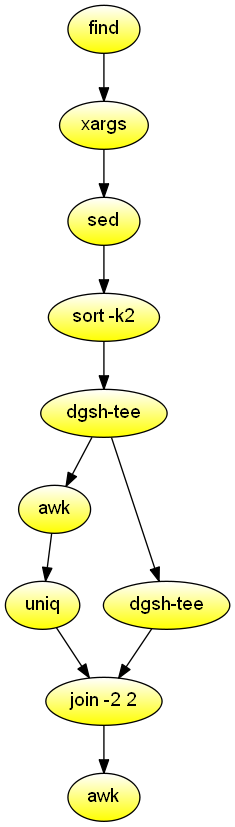
List the names of duplicate files in the specified directory. Demonstrates the combination of streams with a relational join.
#!/usr/bin/env dgsh
# Create list of files
find "$@" -type f |
# Produce lines of the form
# MD5(filename)= 811bfd4b5974f39e986ddc037e1899e7
xargs openssl md5 |
# Convert each line into a "filename md5sum" pair
sed 's/^MD5(//;s/)= / /' |
# Sort by MD5 sum
sort -k2 |
tee |
{{
# Print an MD5 sum for each file that appears more than once
awk '{print $2}' | uniq -d
# Promote the stream to gather it
cat
}} |
# Join the repeated MD5 sums with the corresponding file names
# Join expects two inputs, second will come from scatter
# XXX make streaming input identifiers transparent to users
join -2 2 |
# Output same files on a single line
awk '
BEGIN {ORS=""}
$1 != prev && prev {print "\n"}
END {if (prev) print "\n"}
{if (prev) print " "; prev = $1; print $2}'
Highlight misspelled words
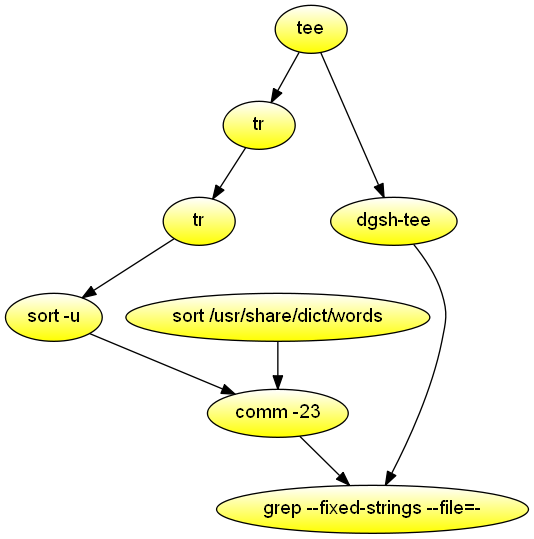
Highlight the words that are misspelled in the command's first argument. Demonstrates stream processing with multipipes and the avoidance of pass-through constructs to avoid deadlocks.
#!/usr/bin/env dgsh
export LC_ALL=C
tee |
{{
# Find errors
{{
# Obtain list of words in text
tr -cs A-Za-z \\n |
tr A-Z a-z |
sort -u
# Ensure dictionary is compatibly sorted
sort /usr/share/dict/words
}} |
# List errors as a set difference
comm -23
# Pass through text
cat
}} |
grep --fixed-strings --file=- --ignore-case --color --word-regex --context=2
Word properties
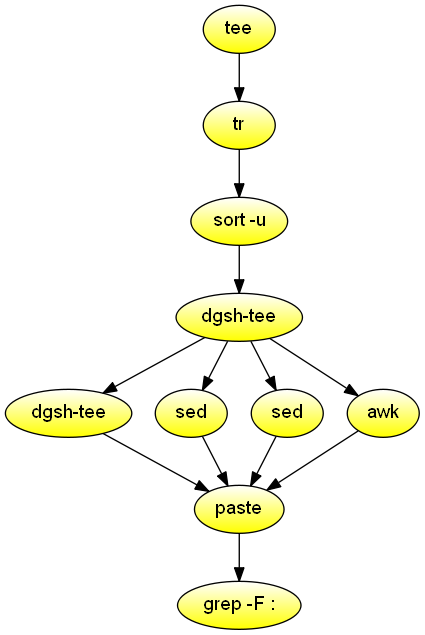
Read text from the standard input and list words containing a two-letter palindrome, words containing four consonants, and words longer than 12 characters.
#!/usr/bin/env dgsh
# Consistent sorting across machines
export LC_ALL=C
# Stream input from file
cat $1 |
# Split input one word per line
tr -cs a-zA-Z \\n |
# Create list of unique words
sort -u |
tee |
{{
# Pass through the original words
cat
# List two-letter palindromes
sed 's/.*\(.\)\(.\)\2\1.*/p: \1\2-\2\1/;t
g'
# List four consecutive consonants
sed -E 's/.*([^aeiouyAEIOUY]{4}).*/c: \1/;t
g'
# List length of words longer than 12 characters
awk '{if (length($1) > 12) print "l:", length($1);
else print ""}'
}} |
# Paste the four streams side-by-side
paste |
# List only words satisfying one or more properties
fgrep :
Web log reporting
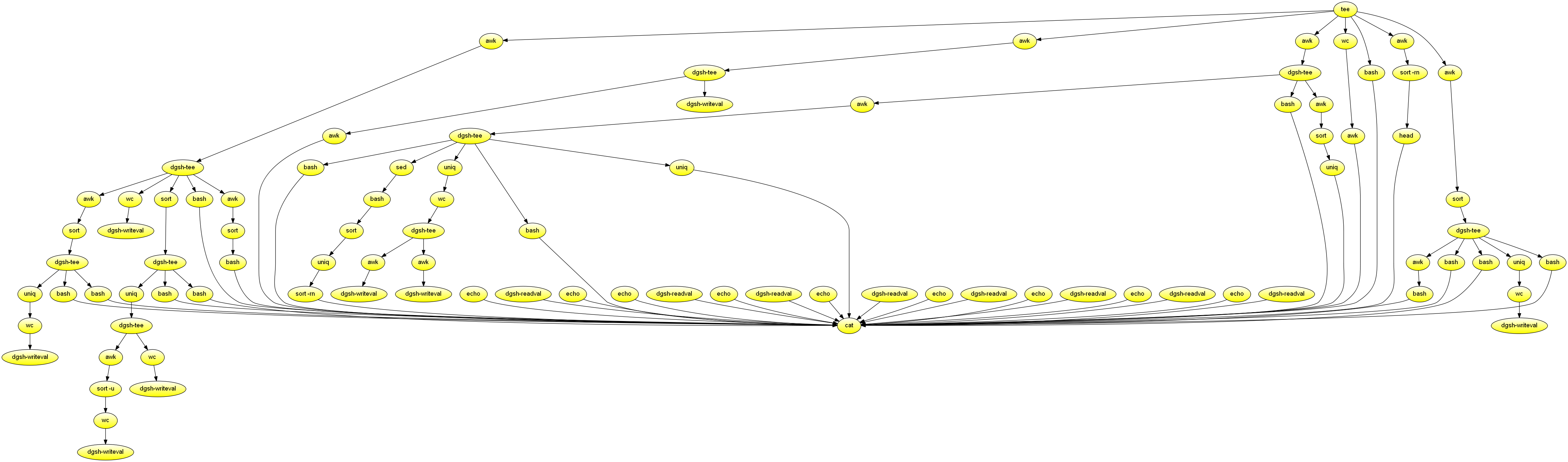
Creates a report for a fixed-size web log file read from the standard input. Demonstrates the combined use of multipipe blocks, writeval and readval to store and retrieve values, and functions in the scatter block. Used to measure throughput increase achieved through parallelism.
#!/usr/bin/env dgsh
# Output the top X elements of the input by the number of their occurrences
# X is the first argument
toplist()
{
uniq -c | sort -rn | head -$1
echo
}
# Output the argument as a section header
header()
{
echo
echo "$1"
echo "$1" | sed 's/./-/g'
}
# Consistent sorting
export LC_ALL=C
export -f toplist
export -f header
if [ -z "${DGSH_DRAW_EXIT}" ]
then
cat <<EOF
WWW server statistics
=====================
Summary
-------
EOF
fi
tee |
{{
# Number of accesses
echo -n 'Number of accesses: '
dgsh-readval -l -s nAccess
# Number of transferred bytes
awk '{s += $NF} END {print s}' |
tee |
{{
echo -n 'Number of Gbytes transferred: '
awk '{print $1 / 1024 / 1024 / 1024}'
dgsh-writeval -s nXBytes
}}
echo -n 'Number of hosts: '
dgsh-readval -l -q -s nHosts
echo -n 'Number of domains: '
dgsh-readval -l -q -s nDomains
echo -n 'Number of top level domains: '
dgsh-readval -l -q -s nTLDs
echo -n 'Number of different pages: '
dgsh-readval -l -q -s nUniqPages
echo -n 'Accesses per day: '
dgsh-readval -l -q -s nDayAccess
echo -n 'MBytes per day: '
dgsh-readval -l -q -s nDayMB
# Number of log file bytes
echo -n 'MBytes log file size: '
wc -c |
awk '{print $1 / 1024 / 1024}'
# Host names
awk '{print $1}' |
tee |
{{
# Number of accesses
wc -l | dgsh-writeval -s nAccess
# Sorted hosts
sort |
tee |
{{
# Unique hosts
uniq |
tee |
{{
# Number of hosts
wc -l | dgsh-writeval -s nHosts
# Number of TLDs
awk -F. '$NF !~ /[0-9]/ {print $NF}' |
sort -u |
wc -l |
dgsh-writeval -s nTLDs
}}
# Top 10 hosts
{{
call 'header "Top 10 Hosts"'
call 'toplist 10'
}}
}}
# Top 20 TLDs
{{
call 'header "Top 20 Level Domain Accesses"'
awk -F. '$NF !~ /^[0-9]/ {print $NF}' |
sort |
call 'toplist 20'
}}
# Domains
awk -F. 'BEGIN {OFS = "."}
$NF !~ /^[0-9]/ {$1 = ""; print}' |
sort |
tee |
{{
# Number of domains
uniq |
wc -l |
dgsh-writeval -s nDomains
# Top 10 domains
{{
call 'header "Top 10 Domains"'
call 'toplist 10'
}}
}}
}}
# Hosts by volume
{{
call 'header "Top 10 Hosts by Transfer"'
awk ' {bytes[$1] += $NF}
END {for (h in bytes) print bytes[h], h}' |
sort -rn |
head -10
}}
# Sorted page name requests
awk '{print $7}' |
sort |
tee |
{{
# Top 20 area requests (input is already sorted)
{{
call 'header "Top 20 Area Requests"'
awk -F/ '{print $2}' |
call 'toplist 20'
}}
# Number of different pages
uniq |
wc -l |
dgsh-writeval -s nUniqPages
# Top 20 requests
{{
call 'header "Top 20 Requests"'
call 'toplist 20'
}}
}}
# Access time: dd/mmm/yyyy:hh:mm:ss
awk '{print substr($4, 2)}' |
tee |
{{
# Just dates
awk -F: '{print $1}' |
tee |
{{
# Number of days
uniq |
wc -l |
tee |
{{
awk '
BEGIN {
"dgsh-readval -l -x -s nAccess" | getline NACCESS;}
{print NACCESS / $1}' |
dgsh-writeval -s nDayAccess
awk '
BEGIN {
"dgsh-readval -l -x -q -s nXBytes" | getline NXBYTES;}
{print NXBYTES / $1 / 1024 / 1024}' |
dgsh-writeval -s nDayMB
}}
{{
call 'header "Accesses by Date"'
uniq -c
}}
# Accesses by day of week
{{
call 'header "Accesses by Day of Week"'
sed 's|/|-|g' |
call '(date -f - +%a 2>/dev/null || gdate -f - +%a)' |
sort |
uniq -c |
sort -rn
}}
}}
# Hour
{{
call 'header "Accesses by Local Hour"'
awk -F: '{print $2}' |
sort |
uniq -c
}}
}}
dgsh-readval -q -s nAccess
}} |
cat
Text properties
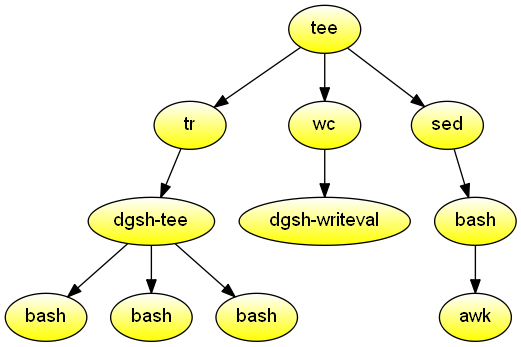
Read text from the standard input and create files containing word, character, digram, and trigram frequencies.
#!/usr/bin/env dgsh
# Consistent sorting across machines
export LC_ALL=C
# Convert input into a ranked frequency list
ranked_frequency()
{
awk '{count[$1]++} END {for (i in count) print count[i], i}' |
# We want the standard sort here
sort -rn
}
# Convert standard input to a ranked frequency list of specified n-grams
ngram()
{
local N=$1
perl -ne 'for ($i = 0; $i < length($_) - '$N'; $i++) {
print substr($_, $i, '$N'), "\n";
}' |
ranked_frequency
}
export -f ranked_frequency
export -f ngram
tee |
{{
# Split input one word per line
tr -cs a-zA-Z \\n |
tee |
{{
# Digram frequency
call 'ngram 2 >digram.txt'
# Trigram frequency
call 'ngram 3 >trigram.txt'
# Word frequency
call 'ranked_frequency >words.txt'
}}
# Store number of characters to use in awk below
wc -c |
dgsh-writeval -s nchars
# Character frequency
sed 's/./&\
/g' |
# Print absolute
call 'ranked_frequency' |
awk 'BEGIN {
"dgsh-readval -l -x -q -s nchars" | getline NCHARS
OFMT = "%.2g%%"}
{print $1, $2, $1 / NCHARS * 100}' > character.txt
}}
C/C++ symbols that should be static
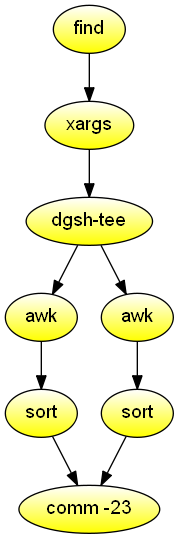
Given as an argument a directory containing object files, show which symbols are declared with global visibility, but should have been declared with file-local (static) visibility instead. Demonstrates the use of dgsh-capable comm (1) to combine data from two sources.
#!/usr/bin/env dgsh
# Find object files
find "$1" -name \*.o |
# Print defined symbols
xargs nm |
tee |
{{
# List all defined (exported) symbols
awk 'NF == 3 && $2 ~ /[A-Z]/ {print $3}' | sort
# List all undefined (imported) symbols
awk '$1 == "U" {print $2}' | sort
}} |
# Print exports that are not imported
comm -23
Hierarchy map
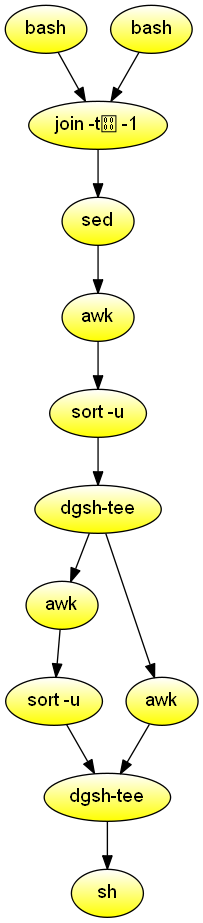
Given two directory hierarchies A and B passed as input arguments (where these represent a project at different parts of its lifetime) copy the files of hierarchy A to a new directory, passed as a third argument, corresponding to the structure of directories in B. Demonstrates the use of join to process results from two inputs and the use of gather to order asynchronously produced results.
#!/usr/bin/env dgsh
if [ -z "${DGSH_DRAW_EXIT}" -a \( ! -d "$1" -o ! -d "$2" -o -z "$3" \) ]
then
echo "Usage: $0 dir-1 dir-2 new-dir-name" 1>&2
exit 1
fi
NEWDIR="$3"
export LC_ALL=C
line_signatures()
{
find $1 -type f -name '*.[chly]' -print |
# Split path name into directory and file
sed 's|\(.*\)/\([^/]*\)|\1 \2|' |
while read dir file
do
# Print "directory filename content" of lines with
# at least one alphabetic character
# The fields are separated by and
sed -n "/[a-z]/s|^|$dir$file|p" "$dir/$file"
done |
# Error: multi-character tab '\001\001'
sort -T `pwd` -t -k 2
}
export -f line_signatures
{{
# Generate the signatures for the two hierarchies
call 'line_signatures "$1"' -- "$1"
call 'line_signatures "$1"' -- "$2"
}} |
# Join signatures on file name and content
join -t -1 2 -2 2 |
# Print filename dir1 dir2
sed 's///g' |
awk -F 'BEGIN{OFS=" "}{print $1, $3, $4}' |
# Unique occurrences
sort -u |
tee |
{{
# Commands to copy
awk '{print "mkdir -p '$NEWDIR'/" $3 ""}' |
sort -u
awk '{print "cp " $2 "/" $1 " '$NEWDIR'/" $3 "/" $1 ""}'
}} |
# Order: first make directories, then copy files
# TODO: dgsh-tee does not pass along first incoming stream
cat |
sh
Plot Git committer activity over time
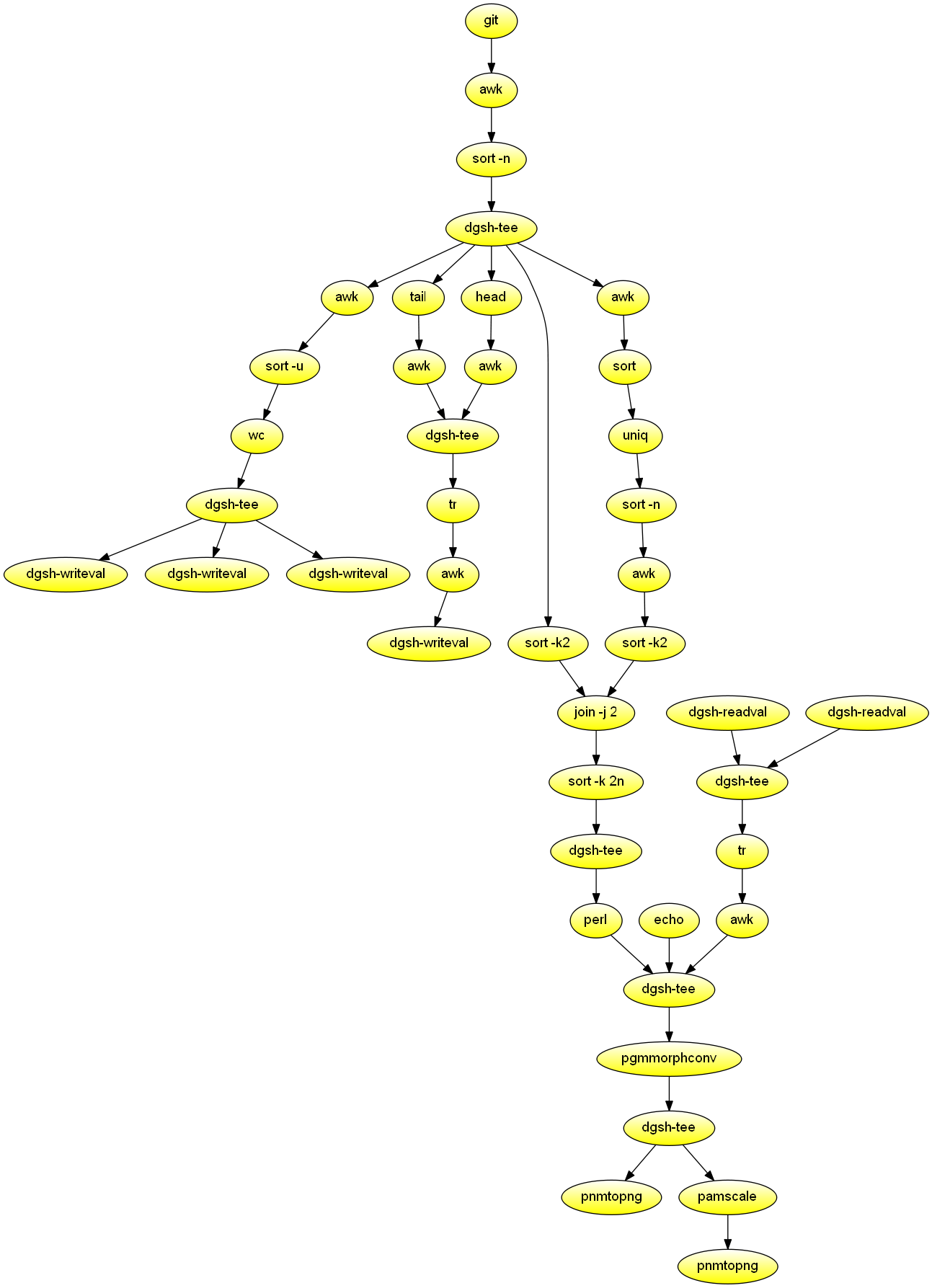
Process the Git history, and create two PNG diagrams depicting committer activity over time. The most active committers appear at the center vertical of the diagram. Demonstrates image processing, mixining of synchronous and asynchronous processing in a scatter block, and the use of an dgsh-compliant join command.
#!/usr/bin/env dgsh
# Commit history in the form of ascending Unix timestamps, emails
git log --pretty=tformat:'%at %ae' |
# Filter records according to timestamp: keep (100000, now) seconds
awk 'NF == 2& $1 > 100000& $1 < '`date +%s` |
sort -n |
tee |
{{
{{
# Calculate number of committers
awk '{print $2}' |
sort -u |
wc -l |
tee |
{{
dgsh-writeval -s committers1
dgsh-writeval -s committers2
dgsh-writeval -s committers3
}}
# Calculate last commit timestamp in seconds
tail -1 |
awk '{print $1}'
# Calculate first commit timestamp in seconds
head -1 |
awk '{print $1}'
}} |
# Gather last and first commit timestamp
cat |
# Make one space-delimeted record
tr '\n' ' ' |
# Compute the difference in days
awk '{print int(($1 - $2) / 60 / 60 / 24)}' |
# Store number of days
dgsh-writeval -s days
sort -k2 # <timestamp, email>
# Place committers left/right of the median
# according to the number of their commits
awk '{print $2}' |
sort |
uniq -c |
sort -n |
awk '
BEGIN {
"dgsh-readval -l -x -q -s committers1" | getline NCOMMITTERS
l = 0; r = NCOMMITTERS;}
{print NR % 2 ? l++ : --r, $2}' |
sort -k2 # <left/right, email>
}} |
# Join committer positions with commit time stamps
# based on committer email
join -j 2 | # <email, timestamp, left/right>
# Order by timestamp
sort -k 2n |
tee |
{{
# Create portable bitmap
echo 'P1'
{{
dgsh-readval -l -q -s committers2
dgsh-readval -l -q -s days
}} |
cat |
tr '\n' ' ' |
awk '{print $1, $2}'
perl -na -e '
BEGIN {
open(my $ncf, "-|", "dgsh-readval -l -x -q -s committers3");
$ncommitters = <$ncf>;
@empty[$ncommitters - 1] = 0; @committers = @empty;
}
sub out {
print join("", map($_ ? "1" : "0", @committers)), "\n";
}
$day = int($F[1] / 60 / 60 / 24);
$pday = $day if (!defined($pday));
while ($day != $pday) {
out();
@committers = @empty;
$pday++;
}
$committers[$F[2]] = 1;
END { out(); }
'
}} |
cat |
# Enlarge points into discs through morphological convolution
pgmmorphconv -erode <(
cat <<EOF
P1
7 7
1 1 1 0 1 1 1
1 1 0 0 0 1 1
1 0 0 0 0 0 1
0 0 0 0 0 0 0
1 0 0 0 0 0 1
1 1 0 0 0 1 1
1 1 1 0 1 1 1
EOF
) |
tee |
{{
# Full-scale image
pnmtopng >large.png
# A smaller image
pamscale -width 640 |
pnmtopng >small.png
}}
Parallel word count
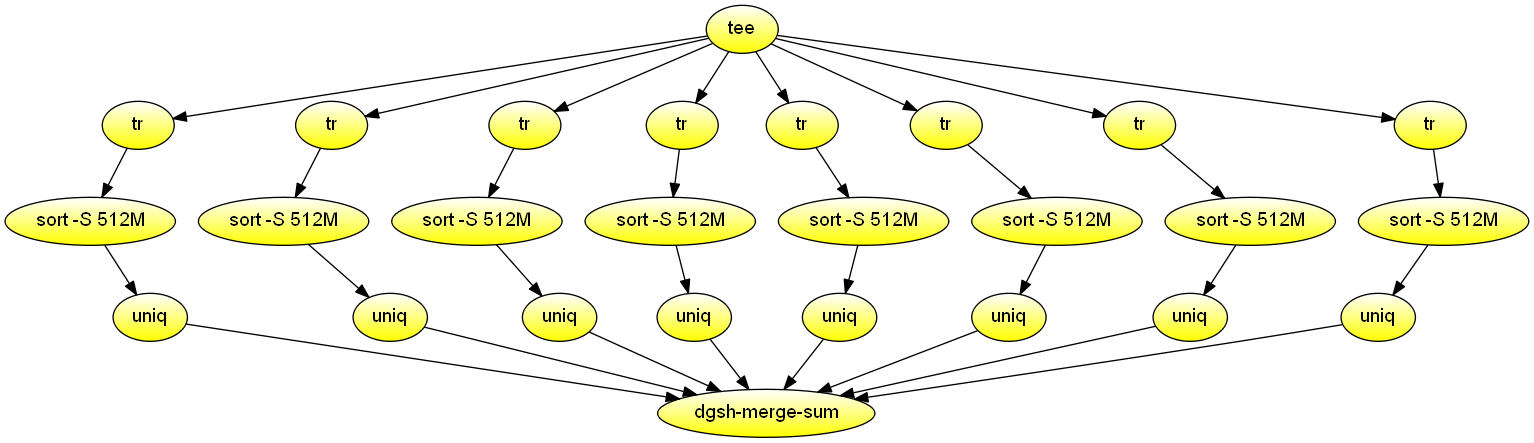
Count number of times each word appears in the specified input file(s) Demonstrates parallel execution mirroring the Hadoop WordCount example via the dgsh-parallel command. In contrast to GNU parallel, the block generated by dgsh-parallel has N input and output streams, which can be combined by any dgsh-compatible tool, such as dgsh-merge-sum or sort -m.
#!/usr/bin/env dgsh # Number of processes N=8 # Collation order for sorting export LC_ALL=C # Scatter input dgsh-tee -s | # Emulate Java's default StringTokenizer, sort, count dgsh-parallel -n $N "tr -s ' \t\n\r\f' '\n' | sort -S 512M | uniq -c" | # Merge sorted counts by providing N input channels dgsh-merge-sum $(for i in $(seq $N) ; do printf '<| ' ; done)
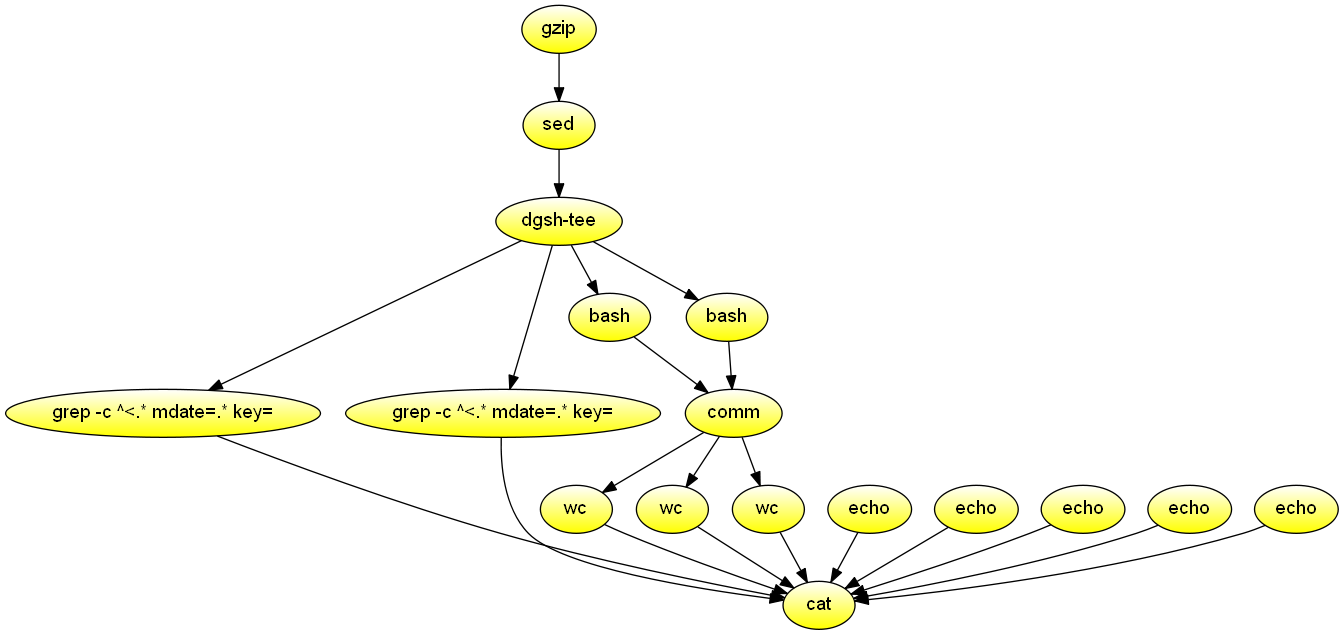
Given the specification of two publication venues, read a compressed DBLP computer science bibliography from the standard input (e.g. piped from curl -s http://dblp.uni-trier.de/xml/dblp.xml.gz or from a locally cached copy) and output the number of papers published in each of the two venues as well as the number of authors who have published only in the first venue, the number who have published only in the second one, and authors who have published in both. The venues are specified through the script's first two command-line arguments as a DBLP key prefix, e.g. journals/acta/, conf/icse/, journals/software/, conf/iwpc/, or conf/msr/. Demonstrates the use of dgsh-wrap -e to have sed(1) create two output streams and the use of tee to copy a pair of streams into four ones.
#!/usr/bin/env dgsh
# Extract and sort author names
sorted_authors()
{
sed -n 's/<author>\([^<]*\)<\/author>/\1/p' |
sort
}
# Escape a string to make it a valid sed(1) pattern
escape()
{
echo "$1" | sed 's/\([/\\]\)/\\\1/g'
}
export -f sorted_authors
if [ ! "$2" -a ! "$DGSH_DOT_DRAW"] ; then
echo "Usage: $0 key1 key2" 1>&2
echo "Example: $0 conf/icse/ journals/software/" 1>&2
exit 1
fi
gzip -dc |
# Output the two venue authors as two output streams
dgsh-wrap -e sed -n "
/^<.*key=\"$(escape $1)/,/<title>/ w >|
/^<.*key=\"$(escape $2)/,/<title>/ w >|" |
# 2 streams in 4 streams out: venue1, venue2, venue1, venue2
tee |
{{
{{
echo -n "$1 papers: "
grep -c '^<.* mdate=.* key='
echo -n "$2 papers: "
grep -c '^<.* mdate=.* key='
}}
{{
call sorted_authors
call sorted_authors
}} |
comm |
{{
echo -n "Authors only in $1: "
wc -l
echo -n "Authors only in $2: "
wc -l
echo -n 'Authors common in both venues: '
wc -l
}}
}} |
cat
Waves: 2D Fourier transforms
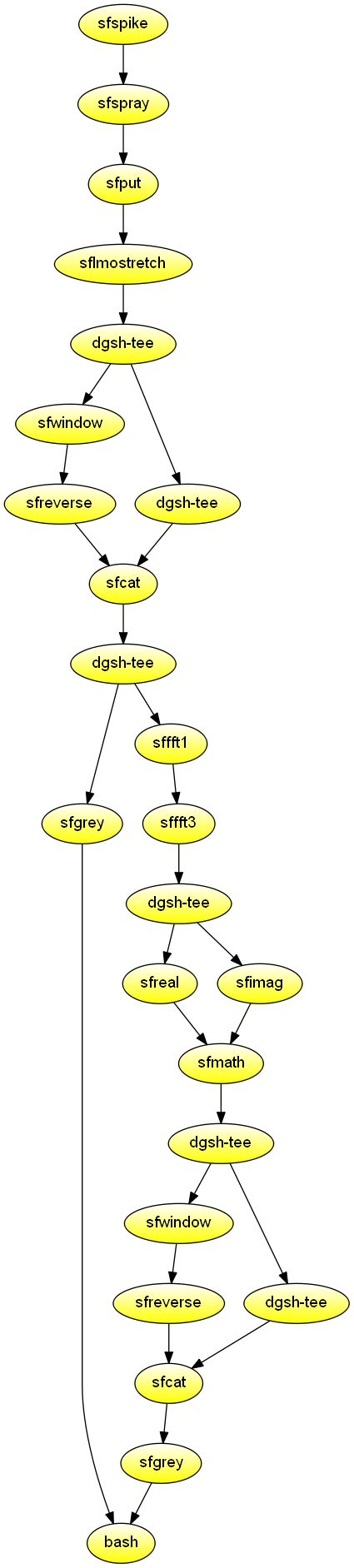
Create two graphs: 1) a broadened pulse and the real part of its 2D Fourier transform, and 2) a simulated air wave and the amplitude of its 2D Fourier transform. Demonstrates using the tools of the Madagascar shared research environment for computational data analysis in geophysics and related fields. Also demonstrates the use of two scatter blocks in the same script, and the used of named streams.
#!/usr/bin/env dgsh
mkdir -p Fig
# The SConstruct SideBySideIso "Result" method
side_by_side_iso()
{
vppen size=r vpstyle=n gridnum=2,1 /dev/stdin $*
}
export -f side_by_side_iso
# A broadened pulse and the real part of its 2D Fourier transform
sfspike n1=64 n2=64 d1=1 d2=1 nsp=2 k1=16,17 k2=5,5 mag=16,16 \
label1='time' label2='space' unit1= unit2= |
sfsmooth rect2=2 |
sfsmooth rect2=2 |
tee |
{{
sfgrey pclip=100 wanttitle=n
sffft1 |
sffft3 axis=2 pad=1 |
sfreal |
tee |
{{
sfwindow f1=1 | sfreverse which=3
cat
}} |
sfcat axis=1 "<|" |
sfgrey pclip=100 wanttitle=n label1="1/time" label2="1/space"
}} |
call_with_stdin side_by_side_iso '<|' yscale=1.25 >Fig/ft2dofpulse.vpl
# A simulated air wave and the amplitude of its 2D Fourier transform
sfspike n1=64 d1=1 o1=32 nsp=4 k1=1,2,3,4 mag=1,3,3,1 \
label1='time' unit1= |
sfspray n=32 d=1 o=0 |
sfput label2=space |
sflmostretch delay=0 v0=-1 |
tee |
{{
sfwindow f2=1 | sfreverse which=2
cat
}} |
sfcat axis=2 "<|" |
tee |
{{
sfgrey pclip=100 wanttitle=n
sffft1 |
sffft3 sign=1 |
tee |
{{
sfreal
sfimag
}} |
dgsh-wrap -e sfmath nostdin=y re="<|" im="<|" \
output="sqrt(re*re+im*im)" |
tee |
{{
sfwindow f1=1 | sfreverse which=3
cat
}} |
sfcat axis=1 "<|" |
sfgrey pclip=100 wanttitle=n label1="1/time" label2="1/space"
}} |
call_with_stdin side_by_side_iso '<|' yscale=1.25 >Fig/airwave.vpl
wait
Nuclear magnetic resonance processing

Nuclear magnetic resonance in-phase/anti-phase channel conversion and processing in heteronuclear single quantum coherence spectroscopy. Demonstrate processing of NMR data using the NMRPipe family of programs.
#!/usr/bin/env dgsh
# The conversion is configured for the following file:
# http://www.bmrb.wisc.edu/ftp/pub/bmrb/timedomain/bmr6443/timedomain_data/c13-hsqc/june11-se-6426-CA.fid/fid
var2pipe -in $1 \
-xN 1280 -yN 256 \
-xT 640 -yT 128 \
-xMODE Complex -yMODE Complex \
-xSW 8000 -ySW 6000 \
-xOBS 599.4489584 -yOBS 60.7485301 \
-xCAR 4.73 -yCAR 118.000 \
-xLAB 1H -yLAB 15N \
-ndim 2 -aq2D States \
-verb |
tee |
{{
# IP/AP channel conversion
# See http://tech.groups.yahoo.com/group/nmrpipe/message/389
nmrPipe |
nmrPipe -fn SOL |
nmrPipe -fn SP -off 0.5 -end 0.98 -pow 2 -c 0.5 |
nmrPipe -fn ZF -auto |
nmrPipe -fn FT |
nmrPipe -fn PS -p0 177 -p1 0.0 -di |
nmrPipe -fn EXT -left -sw -verb |
nmrPipe -fn TP |
nmrPipe -fn COADD -cList 1 0 -time |
nmrPipe -fn SP -off 0.5 -end 0.98 -pow 1 -c 0.5 |
nmrPipe -fn ZF -auto |
nmrPipe -fn FT |
nmrPipe -fn PS -p0 0 -p1 0 -di |
nmrPipe -fn TP |
nmrPipe -fn POLY -auto -verb >A
nmrPipe |
nmrPipe -fn SOL |
nmrPipe -fn SP -off 0.5 -end 0.98 -pow 2 -c 0.5 |
nmrPipe -fn ZF -auto |
nmrPipe -fn FT |
nmrPipe -fn PS -p0 177 -p1 0.0 -di |
nmrPipe -fn EXT -left -sw -verb |
nmrPipe -fn TP |
nmrPipe -fn COADD -cList 0 1 -time |
nmrPipe -fn SP -off 0.5 -end 0.98 -pow 1 -c 0.5 |
nmrPipe -fn ZF -auto |
nmrPipe -fn FT |
nmrPipe -fn PS -p0 -90 -p1 0 -di |
nmrPipe -fn TP |
nmrPipe -fn POLY -auto -verb >B
}}
# We use temporary files rather than streams, because
# addNMR mmaps its input files. The diagram displayed in the
# example shows the notional data flow.
if [ -z "${DGSH_DRAW_EXIT}" ]
then
addNMR -in1 A -in2 B -out A+B.dgsh.ft2 -c1 1.0 -c2 1.25 -add
addNMR -in1 A -in2 B -out A-B.dgsh.ft2 -c1 1.0 -c2 1.25 -sub
fi
FFT calculation
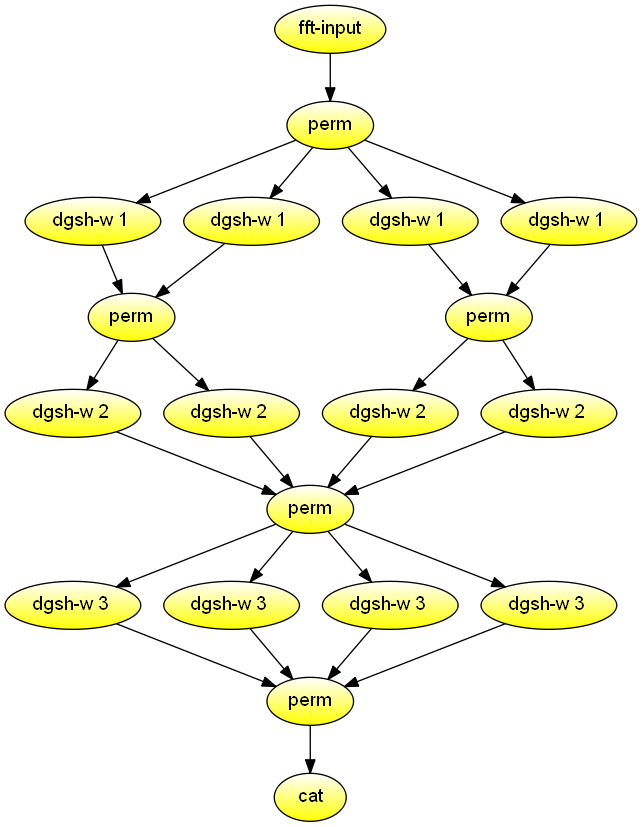
Calculate the iterative FFT for n = 8 in parallel. Demonstrates combined use of permute and multipipe blocks.
#!/usr/bin/env dgsh
dgsh-fft-input $1 |
perm 1,5,3,7,2,6,4,8 |
{{
{{
dgsh-w 1 0
dgsh-w 1 0
}} |
perm 1,3,2,4 |
{{
dgsh-w 2 0
dgsh-w 2 1
}}
{{
dgsh-w 1 0
dgsh-w 1 0
}} |
perm 1,3,2,4 |
{{
dgsh-w 2 0
dgsh-w 2 1
}}
}} |
perm 1,5,3,7,2,6,4,8 |
{{
dgsh-w 3 0
dgsh-w 3 1
dgsh-w 3 2
dgsh-w 3 3
}} |
perm 1,5,2,6,3,7,4,8 |
cat
Reorder columns
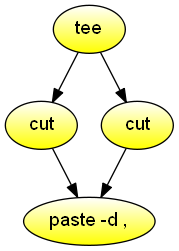
Reorder columns in a CSV document. Demonstrates the combined use of tee, cut, and paste.
#!/usr/bin/env dgsh
tee |
{{
cut -d , -f 5-6 -
cut -d , -f 2-4 -
}} |
paste -d ,
Directory listing
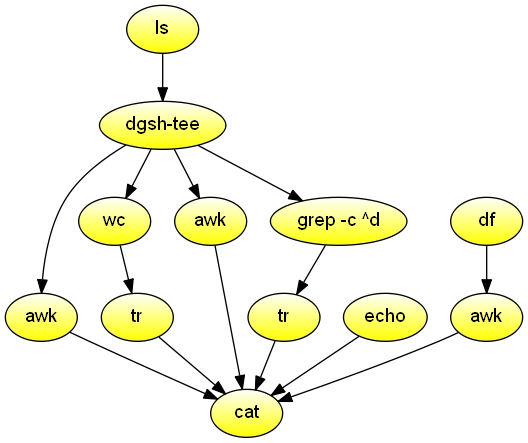
Windows-like DIR command for the current directory.
Nothing that couldn't be done with ls -l | awk.
Demonstrates use of wrapped commands with no input (df, echo).
#!/usr/bin/env dgsh
ls -n |
tee |
{{
# Reorder fields in DIR-like way
awk '!/^total/ {print $6, $7, $8, $1, sprintf("%8d", $5), $9}'
# Count number of files
wc -l | tr -d \\n
# Print label for number of files
echo -n ' File(s) '
# Tally number of bytes
awk '{s += $5} END {printf("%d bytes\n", s)}'
# Count number of directories
grep -c '^d' | tr -d \\n
# Print label for number of dirs and calculate free bytes
df -h . | awk '!/Use%/{print " Dir(s) " $4 " bytes free"}'
}} |
cat
