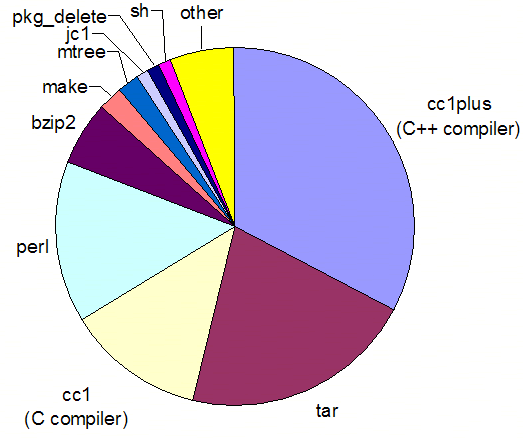
|
http://www.spinellis.gr/pubs/jrnl/2005-IEEESW-TotT/html/v24n4.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
It is impossible to sharpen a pencil with a blunt ax. It is equally vain to try to do it with ten blunt axes instead.
— Edsger W. Dijkstra
What’s the state of the art in the tools we use to build software? To answer this question I let over a period of a month a powerful server build from source code about seven thousand open-source packages. The packages I built form a subset of the FreeBSD ports collection, comprising a wide spectrum of application domains: from desktop utilities and biology applications to databases and development tools. The collection is representative of modern software, because, unlike say a random sample of sourceforge.net projects, these are programs that developers have found useful enough to spend effort to port to FreeBSD. The build process involves fetching each application’s source code bundle from the internet, patching it for FreeBSD, and compiling the source code into executable programs or libraries. Over the monthly period I also setup the operating system to write an accounting record for each one of the commands it executed. I then tallied up the CPU times of the 144 million records corresponding to the work in order to get a picture of how our software builds exploit the power of modern GHz processors.
The figure above contains the time breakup of the commands that took more than 1% of the 18 days of accumulated CPU time. The picture isn’t pretty. First of all, variety in our tools ecosystem appears to be extremely limited. A full 94% of the CPU time is taken by only 10 commands, half of which six drive the unpackaging process and are not directly part of each package’s compilation. This would not be so bad, if the remaining commands, which apparently represent the state of the art in the tools we use for building software, were based on shiny modern ideas. But this is not the case. Three of the tools have their roots in the 1970s and 80s: C (1978), make (1979), and C++ (1983). As you can see, the compilation of C and C++ code takes up the lion’s share of the building effort.
I hear you arguing that studying the tools used at build time is disingenuous, because most of the improvements have happened in the environment where the software is written, not in the tools that compile it. Nowadays, many developers code using advanced IDEs (Integrated Development Environments) that integrate design, coding, debugging, performance analysis, and testing. This is surely a mark of progress. I beg to differ. Using a shiny IDE on top of 1970’s technologies is equivalent to wearing an iPod while ox-ploughing: the work becomes less burdensome, but we’re unlikely to reap substantial productivity improvements from such a change.
The most important (and some claim the only important) artifact of software development is the source code. This is where we store all the knowledge that we acquire during a system’s design, development, and subsequent evolution. Specifications and design documents (when they exist) quickly become out of date, knowledgeable developers switch jobs or retire, many teams don’t document or enforce development processes. This is the reason why organizations often stumble when they try to replace a legacy system. All they have is code, and the legacy code is (as we saw in the previous column) a mess. Therefore, by looking at the tools we use to convert source code into executable format, we get an accurate picture of the abstraction level that programmers will face during construction and maintenance—the activities representing the largest chunk of the software development effort. We’ll see order-of-magnitude productivity improvements, only when we raise our code’s level of abstraction.
Some of you may also argue that, because programs written in Java, C#, and scripting languages don’t require the operating system–specific compilation step that I measured, I haven’t taken into account the large amount of software written in these languages. This is true, but Java and C# still use the same data types and flow-control constructs as C++. They are also still niche players in some important markets: system software, desktop applications, and embedded systems. Where scripting languages are used (think of Ruby on Rails for web site building) they do offer big productivity gains by raising the level of abstraction and offering domain-specific functionality. However, it’s not yet clear how we can apply these gains to other fields.
So what would make me happy? For a start, I’d like to see the ox-plough replaced by a tractor. I’d like to see large chunks of a build’s CPU time going to compilers for languages with at least an order of magnitude more expressive power than C and C++. Some candidates that can offer us higher levels of abstraction are domain-specific languages, general purpose declarative languages like Haskell, and executable UML. These will allow us to have our computers work harder to understand our higher-level programs, thus letting us trade CPU power for human intellect. For instance, the data I collected reflects the higher level of abstraction of C++ over C. Each invocation of the C++ compiler consumes on average 1.6s of CPU time—many times more than the 0.17s of each C compiler run. Accumulated over more than a million executions this is a lot of processor time. However, nowadays CPU power is a resource a) we can afford to use and b) we can’t afford not to use.
I’d also like to see the use of higher-yield grains, fertilizer, and high-tech irrigation; in our case, ancillary tools that help us build reliable, secure, efficient, usable, and maintainable software. These could ensure, for example, that the locks in my software are correctly paired, or that the implementation satisfies a formally described specification. I’d also like to see in the top places of the build effort breakup a single testing framework, a style checker, and a bug finder. Although one could argue that all these tools will only be used during development, I think that a clean bill of health from them during each build would help us concentrate out minds. After all, we don’t disable the compiler’s type checking functionality when performing the release build. In an ideal world one or two tools dominating each category would allow developers to learn one of them and apply it in all their work.
Two success stories of the 1970s that raised the level of abstraction for a specific domain were Stephen Johnson’s parser generator yacc, and Michael Lesk’s lexical analyzer generator lex. Together these two tools and the theory behind them transformed the task of writing a compiler from wizardry into a standard rite of passage for computer science undergraduates. It’s been a long time since these two appeared, and it’s high time to come up with their peers. So, next time you design a system’s architecture think which tools can give you the highest expressive power. Look around, ask your tool vendors, experiment, invent. Just don’t settle for the bland comfort of re-polished 1970’s technologies.