|
http://www.spinellis.gr/pubs/conf/2008-SQM-SQOOSS/html/SGKL09.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
Department of Management Science and Technology
Athens University of Economics and Business
Athens, Greece
Research and Development
Sirius Corporation Ltd.
Weybridge, United Kingdom
Department of Informatics
Aristotle University of Thessaloniki
Thessaloniki, Greece
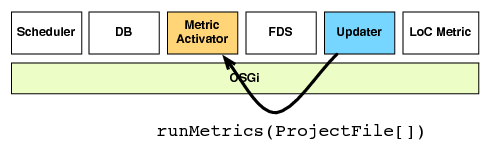 | 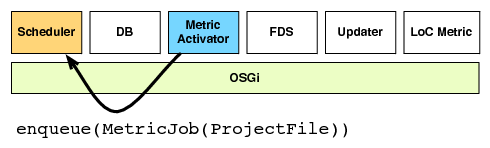 |
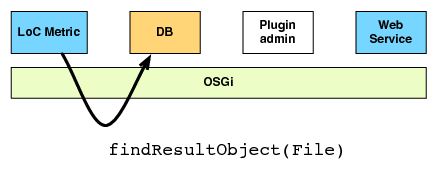
| (a) The updater notifies the metric activator | (b) The metric activator enqueues a calculation job |
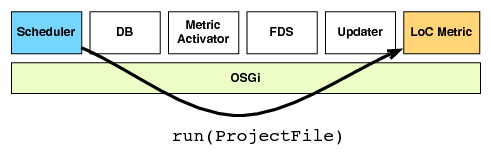 | 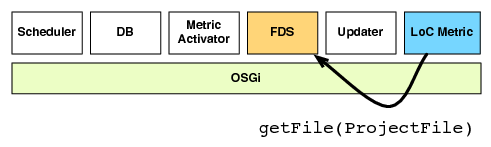 |
| (c) The job is executed | (d) The metric retrieves the file contents from the FDS |
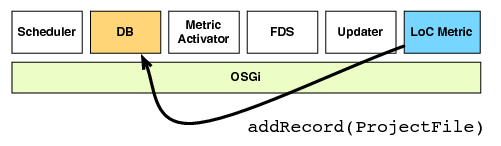 | |
| (f) The result is stored |
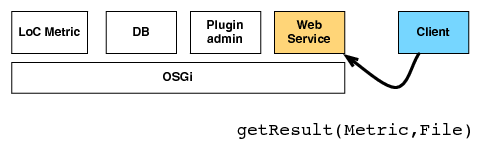 |  |
| (a) The client requests the result of metric on a file | (b) The web service acquires a metric interface |
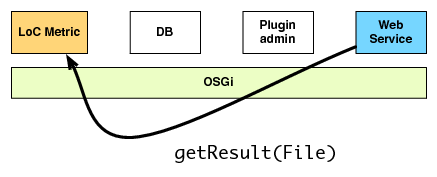 |  |
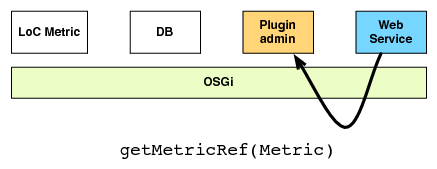
| (c) The web service asks the metric | (d) The metric retrieves the result |
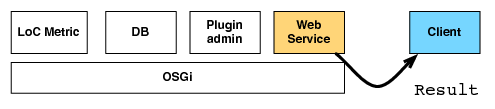 | |
| (e) The result is returned |
 Where:
Where:
| Metric Id | Metric Name | SQO-OSS v0.8 |
| NOPA | Number of Public Attributes | |
| NOC | Number of Children | |
| DIT | Depth of Inheritance Tree | |
| AC | Afferent Couplings | |
| NPM | Number of Public Methods | |
| RFC | Response for a Class | |
| LOC | Lines of Code | |
| COM | Lines of Comments | |
| LCOM | Lack of Cohesion in Methods | |
| NOPRM | Number of Protected Methods | |
| NOCL | Number of Classes | |
| CBO | Coupling between Object Classes | |
| WMC | Weighted Methods per Class |
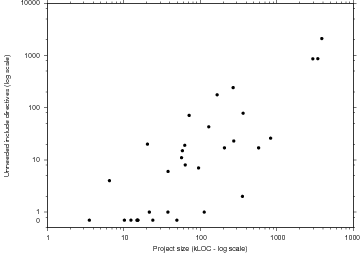
| Asset | Action | Type |
| Add lines of code of good/bad quality | P/N | |
| Commit new source file or directory | P | |
| Commit code that generates/closes a bug | N/P | |
| Add/Change code documentation | P | |
| Commit fixes to code style | P | |
| Commit more than X files in a single commit | N | |
| Commit documentation files | P | |
| Commit translation files | P | |
| Commit binary files | N | |
| Commit with empty commit comment | N | |
| Commit comment that awards a pointy hat | P | |
| Commit comment that includes a bug report num | P | |
| First reply to thread | P | |
| Start a new thread | P | |
| Participate in a flamewar | N | |
| Close a lingering thread | P | |
| Bug Database | Close a bug | P |
| Report a confirmed/invalid bug | P/N | |
| Close a bug that is then reopened | N | |
| Comment on a bug report | P | |
| Wiki | Start a new wiki page | P |
| Update a wiki page | P | |
| Link a wiki page from documentation/mail file | P | |
| IRC | Frequent participation to IRC | P |
| Prompt replies to directed questions | P |

| (2) |
| Dataset | size | k | r2 |
| in/out | in/out | ||
| J2SE SDK | 13,055 | 2.09/3.12 | .99/.86 |
| Eclipse | 22,001 | 2.02/3.15 | .99/.87 |
| OpenOffice | 3,019 | 1.93/2.87 | .99/.94 |
| BEA WebLogic | 80,095 | 2.01/3.52 | .99/.86 |
| CPAN packages | 27,895 | 1.93/3.70 | .98/.95 |
| Linux libraries | 4,047 | 1.68/2.56 | .92/.62 |
| Free BSD libraries | 2,682 | 1.68/2.56 | .91/.58 |
| MS-Windows binaries | 1,355 | 1.66/3.14 | .98/.76 |
| Free BSD ports, libraries deps | 5,104 | 1.75/2.97 | .94/.76 |
| Free BSD ports, build deps | 8,494 | 1.82/3.50 | .99/.98 |
| Free BSD ports, runtime deps | 7,816 | 1.96/3.18 | .99/.99 |
| TEX | 1,364 | 2.00/2.84 | .91/.85 |
| META-FONT | 1,189 | 1.94/2.85 | .96/.85 |
| Ruby | 603 | 2.62/3.14 | .97/.95 |
| The errors of TEX | 1,229 | 3.36 | .94 |
| Linux system calls (242) | 3,908 | 1.40 | .89 |
| Linux C libraries functions (135) | 3,908 | 1.37 | .84 |
| Free BSD system calls (295) | 3,103 | 1.59 | .81 |
| Free BSD C libraries functions (135) | 3,103 | 1.22 | .80 |
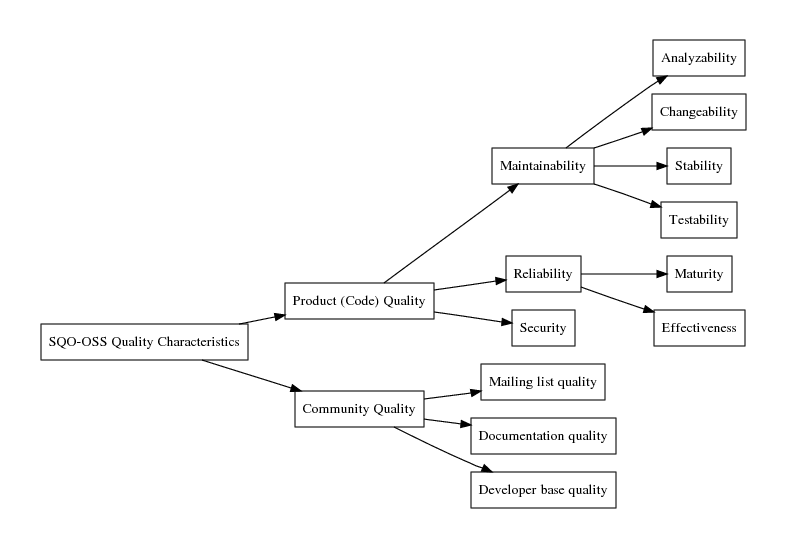
| Attribute | Metric |
| Analyzability | Cyclomatic number |
| Number of statements | |
| Comments frequency | |
| Average size of statements | |
| Weighted methods per class ( WMC) | |
| Number of base classes | |
| Class comments frequency | |
| Changeability | Average size of statements |
| Vocabulary frequency | |
| Number of unconditional jumps | |
| Number of nested levels | |
| Coupling between objects ( CBO) | |
| Lack of cohesion ( LCOM) | |
| Depth of inheritance tree ( DIT) | |
| Stability | Number of unconditional jumps |
| Number of entry nodes | |
| Number of exit nodes | |
| Directly called components | |
| Number of children ( NOC) | |
| Coupling between objects ( CBO) | |
| Depth of inheritance tree ( DIT) | |
| Testability | Number of exits of conditional structs |
| Cyclomatic number | |
| Number of nested levels | |
| Number of unconditional jumps | |
| Response for a class ( RFC) | |
| Average cyclomatic complexity per method | |
| Number of children ( NOC) | |
| Maturity | Number of open critical bugs in the last 6 months |
| Number of open bugs in the last six months | |
| Effectiveness | Number of critical bugs fixed in the last 6 months |
| Number of bugs fixed in the last 6 months | |
| Security | Null dereferences |
| Undefined values | |
| Mailing list | Number of unique subscribers |
| Number of messages in user/support list per month | |
| Number of messages in developers list per month | |
| Average thread depth | |
| Documentation | Available documentation documents |
| Update frequency | |
| Developer base | Rate of developer intake |
| Rate of developer turnover | |
| Growth in active developers | |
| Quality of individual developers |