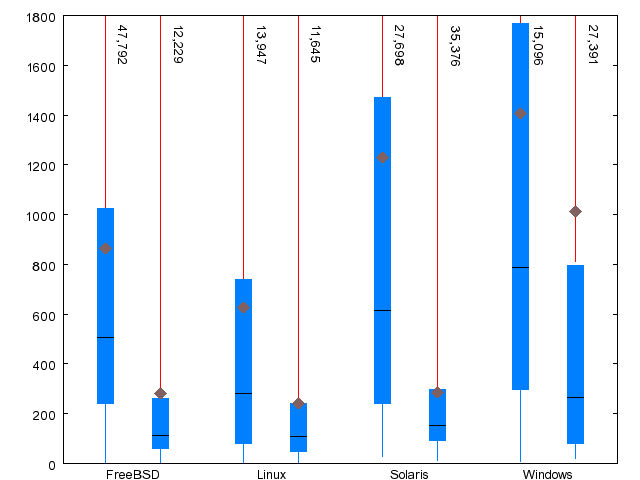
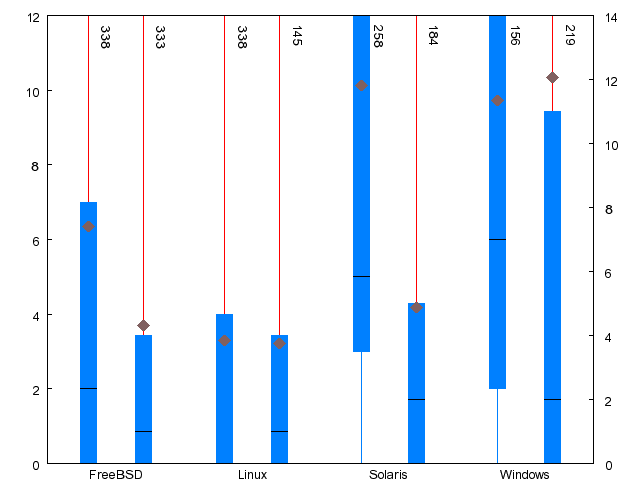
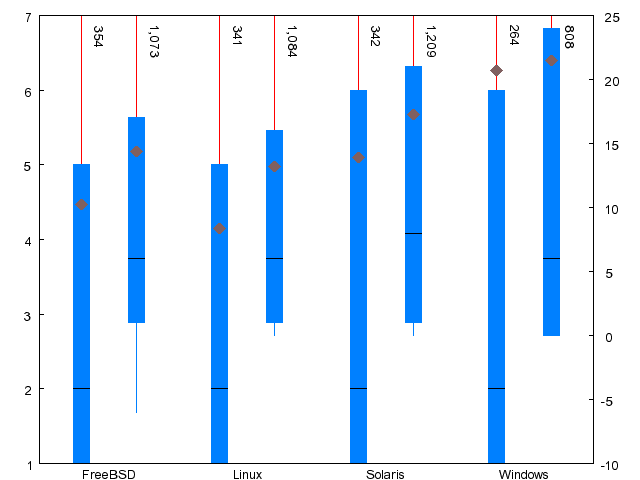
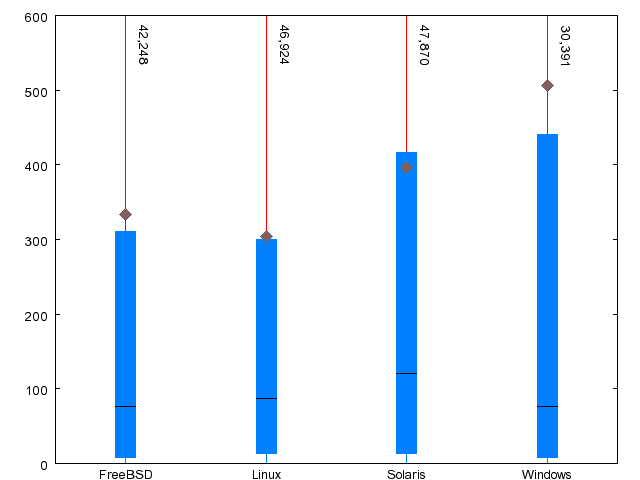
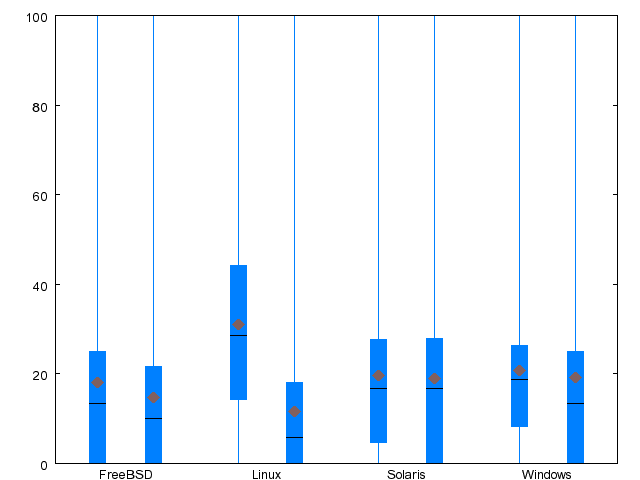
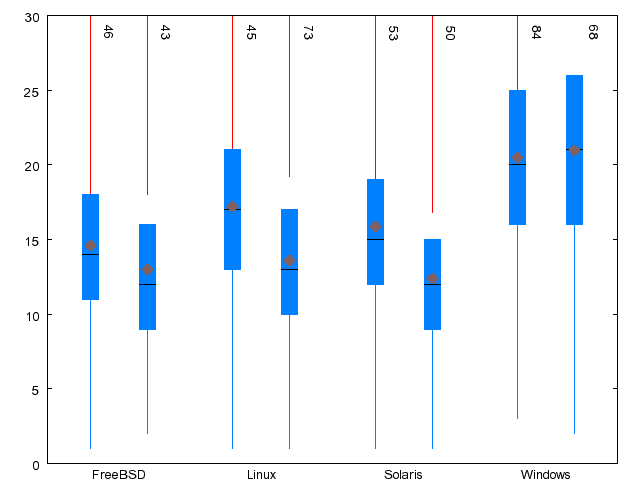
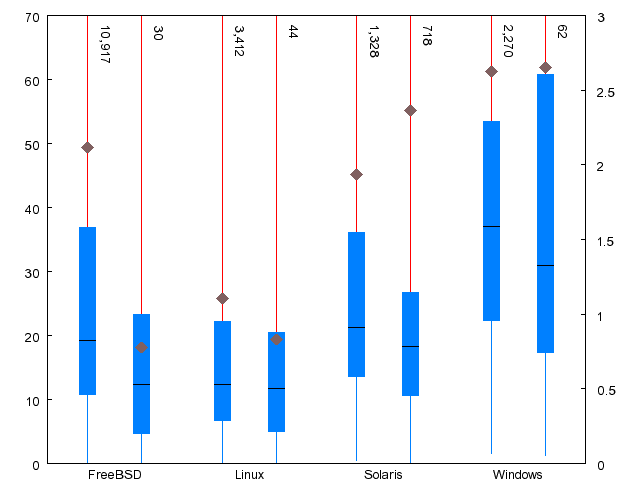
| Metric | FreeBSD | Linux | Solaris | WRK |
| File Organization |
| Length of C files | | | - | - |
| Length of header files | | + | | - |
| Defined global functions in C files | | | - | - |
| Defined structures in header files | | | | - |
| Files per directory | | - | | |
| Header files per C source file | | | | |
| Average structure complexity in files | - | | + | |
| Code Structure |
| Extended cyclomatic complexity | | + | | - |
| Statements per function | | + | | |
| Halstead complexity | | + | | - |
| Common coupling at file scope | | - | | |
| Common coupling at global scope | | + | | |
| % global functions | | + | | - |
| % strictly structured functions | - | | | + |
| % labeled statements | | - | | + |
| Average number of parameters to functions | | | | |
| Average depth of maximum nesting | | | - | - |
| Tokens per statement | | | | |
| % of tokens in replicated code | - | - | + | |
| Average structure complexity in functions | + | - | | |
| Code Style |
| Length of global identifiers | | | | + |
| Length of aggregate identifiers | | | | + |
| % style conforming lines | | | + | - |
| % style conforming typedef identifiers | - | - | | + |
| % style conforming aggregate tags | - | - | - | + |
| Characters per line | | | | |
| % of numeric constants in operands | | - | + | + |
| % unsafe function-like macros | | | - | |
| Comment density in C files | | - | | + |
| Comment density in header files | | - | | + |
| % misspelled comment words | | | | + |
| % unique misspelled comment words | | | | + |
| Preprocessing |
| Preprocessing expansion in functions | - | | + | |
| Preprocessing expansion in files | | | | + |
| % of preprocessor directives in header files | | - | - | + |
| % of non-#include directives in C files | - | | + | |
| % of preprocessor directives in functions | - | | + | |
| % of preprocessor conditionals in functions | - | + | + | |
| % of function-like macros in defined functions | | + | | - |
| % of macros in unique identifiers | - | | + | + |
| % of macros in identifiers | - | | + | |
| Data Organization |
| Average level of namespace pollution in C files | + | | | - |
| % of variable declarations with global scope | | + | | - |
| % of variable operands with global scope | - | + | | |
| % of identifiers with wrongly global scope | | + | | - |
| % of variable declarations with file scope | + | | | - |
| % of variable operands with file scope | | + | | - |
| Variables per typedef or aggregate | | - | | + |
| Data elements per aggregate or enumeration | | - | | + |