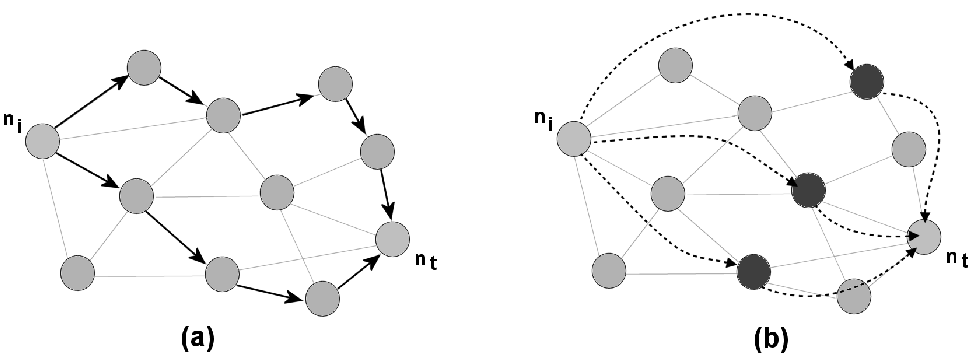
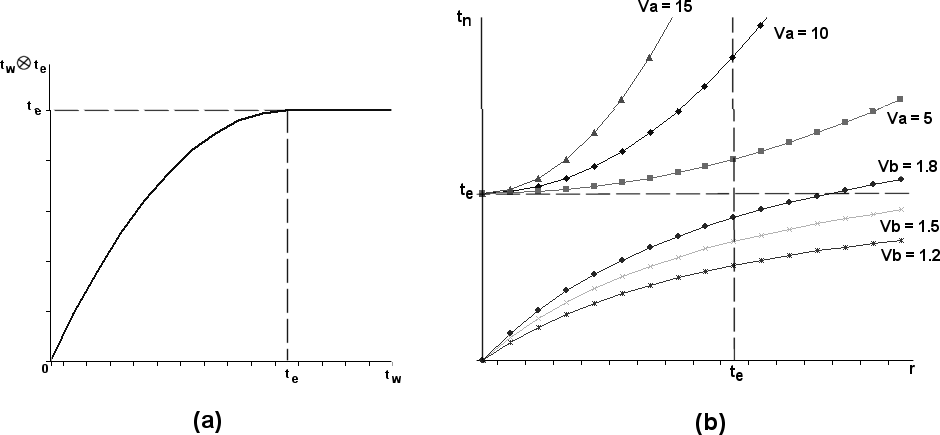
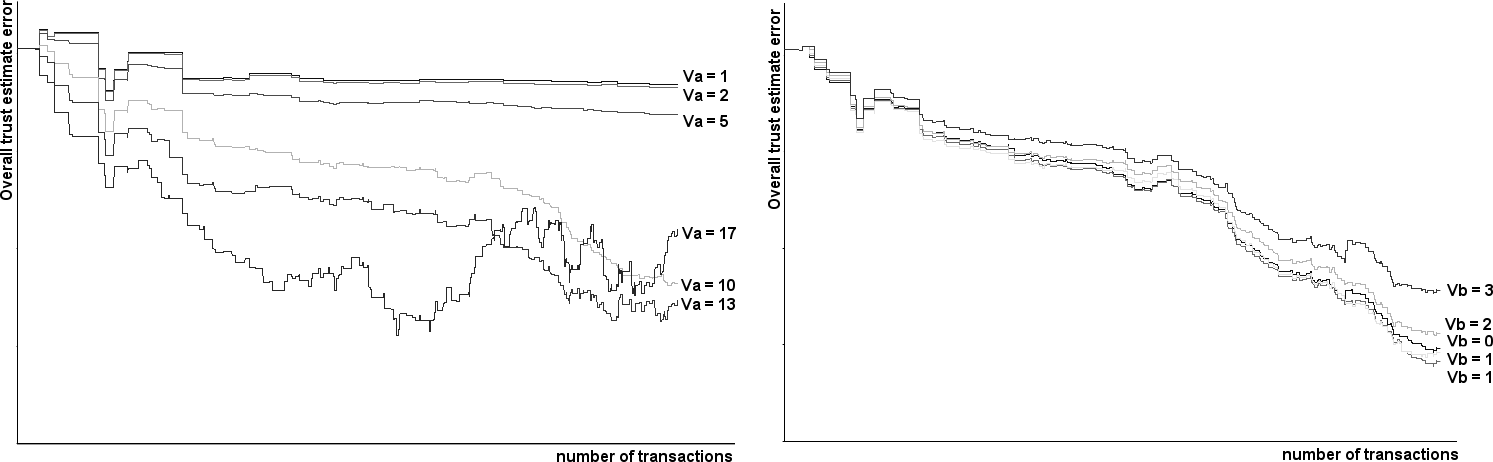
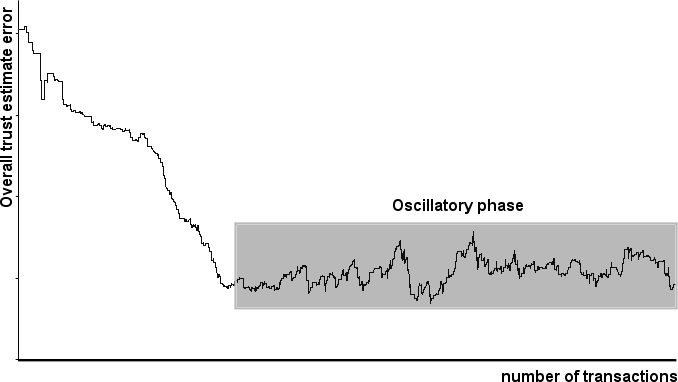
http://www.spinellis.gr/pubs/conf/2006-STM-MoR-Trust/html/ASV.html
This is an HTML rendering of a working paper draft that
led to a publication.
The publication should always be cited in preference to this
draft using the following reference:
- Stephanos
Androutsellis-Theotokis, Diomidis Spinellis, and
Vasileios Vlachos.
The
MoR-Trust distributed trust management system: Design and simulation
results.
In Sandro Etalle, Sara Foresti, and
Pierangela Samarati, editors, Proceedings of the Second
International Workshop on Security and Trust Management (STM'06),
pages 3–15, September 2006.
Electronic Notes in Theoretical Computer Science, Volume 179, July 2007.
(doi:10.1016/j.entcs.2006.11.032)
Citation(s): 11 (selected).This document is also available in
PDF format.The document's metadata is available in BibTeX format.
Find
the publication on Google Scholar
This material is presented to ensure timely dissemination of
scholarly and technical work. Copyright and all rights therein are
retained by authors or by other copyright holders. All persons
copying this information are expected to adhere to the terms and
constraints invoked by each author's copyright. In most cases, these
works may not be reposted without the explicit permission of the
copyright holder.
Diomidis Spinellis Publications
|