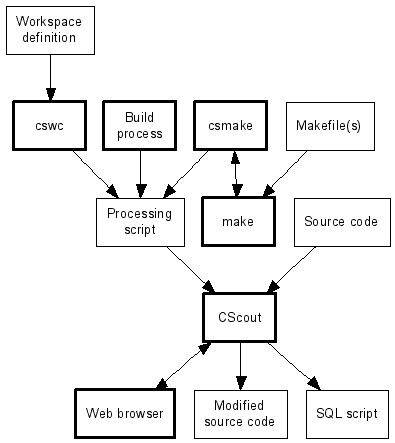
is a source code analyzer and refactoring browser for
collections of C programs.
It can process workspaces of multiple projects (we define a project
as a collection of C source files that are linked together)
mapping the complexity introduced
by the C preprocessor back into the original C source code files.
takes advantage of modern hardware advances (fast processors
and large memory capacities) to analyze C source code beyond the level
of detail and accuracy provided by current compilers, linkers, and
other source code analyzers.
The analysis CScout performs takes into account the identifier scopes
introduced by the C preprocessor and the C language proper scopes and
namespaces.
allows you to refactor the arguments
of functions and macros, introducing new arguments, deleting existing ones,
or changing their order.
).
Even though the file forms a contrived example, it will serve us to illustrate
the basic concepts behind
's operation.
Consider what would the correct renaming of one of the identifiers
named
entail.
will help us to automate this process.
Although, we are dealing with a single file we need to specify its processing
within the context of a workspace.
In a realistic concept a workspace will specify how numerous projects
consisting of multiple files will be processed; think of a workspace
as a collection of Makefiles.
CScout will operate across the many source files and related
executables in the same way as it operates on our example
file idtest.c.
.
Our first step will be to transform the declarative workspace definition file
into a processing script:
a file with imperative processing directives that CScout will
handle.
.
is quite verbose;
when processing a large source code collection, the messages will
serve to assure us that progress is being made.
In our first example we will only rename an identifier,
but as is evident from the page's links CScout provides us
with many powerfull tools.
(in the macro definition)
we are taken to a page specifying the identifier's details.
There we can specify the identifier's new name, e.g.
.
will show us again the corresponding source
code, but with only the identifiers
The marked identifiers will be all the ones and the only ones the replacement
we specified will affect.
Similarly we can specify the replacement of the
label, the static variable, or the local variable;
each one will only affect the relevant identifiers.
From this point onward we use the term Unix to refer to Unix-like systems
like GNU/Linux and FreeBSD, and Windows to refer to Microsoft Windows
systems.
file to see
what might be required.
If your programs are written in standard C and do not use any additional
include files, you can use the generic header files.
Each method has different advantages and disadvantages.
Therefore, you should probably select the method that better suits your needs,
and not bother with the others.
Workspace definition files offer by far the most readable and transparent
way to setup a CScout workspace.
They are declarative and express exactly the operations that CScout
will perform.
On the other hand, they can be difficult to specify for an existing large
project and they must be kept in sync with the project's build process.
with instructions for parsing
a set of C files;
the task that is typically accomplished when compiling programs
through the use of makefiles.
must always process all its source files in a single batch,
so running it for each file from a makefile is not possible.
Workspace definition files provide facilities for
specifying linkage units (typically executable files -
in the workspace definition file parlance)
grouping together similar files and specifying include paths,
read-only paths, and macros.
Workspace definition files are line-oriented and organized around C-like blocks.
Comments are introduced using the # character.
Consider the following simple example:
The above workspace definition consists of a single program (echo),
which in turn consists of a single source file (echo.c).
See how we could expand this for two more programs, all residing in
our system's /usr/src/bin directory:
workspace we have factored out the common
source directory at the workspace level
(
), so that each project only
specifies its directory relatively to the workspace directory
(e.g.
has permission to modify the system's include files.
Specifying one or more read-only prefixes allows
to
distinguish between application identifiers and files, which you can
modify, and system identifiers and files, which should not be changed.
workspaces in the
following BNF grammar.
The above grammar essentially specifies that a workspace consists of
projects, which consist of files or files in a directory.
At the workspace level you can specify files and directories that are
to be considered read-only using the
)
are used to specify macro definitions and the include path.
Their scope is the block they appear in; when you exit the block
(project, directory, or file) their definition is lost.
You can therefore define a macro or an include path for the complete workspace,
a specific project, files within a directory, or a single file.
The syntax of the
command is also scoped; once you exit the block
you return to the directory that was in effect in the outside block.
Within a project you can either specify individual files using
the
command's name is the directory where a
group of files resides and serves as an implicit
command for the files it contains.
Finally, files can be either specified directly as arguments to the
is the file name
to process; the block can contain additional specifications
(scoped commands or the
command without an
argument) for processing that file.
Finally, for processing a couple of C files, you can create a
project file by invoking the cscc tool with the
arguments you would pass to the C compiler.
) or to provide an alternative method
for specifying workspaces by directly creating a processing script
from existing Makefiles.
A processing script (what results from compiling a workspace file)
is a C file containing a number of
preprocessor directives.
processing
script.
command.
The run of the above specification (2 million unique lines)
took 330 CPU minutes on a
Rioworks HDAMA (AMD64) machine
(2x1.8GHz Opteron 244 (in UP mode) - AMD 8111/8131 chipset, 8192MB mem)
and required 1474MB of RAM.
These are the complete metrics:
.
It will serially process each project and directory parsing the
corresponding files specified in the workspace definition file,
and then process once more each one of the files examined to establish
the location of the identifiers.
Note that the bulk of the work is performed in the first pass.
During the first pass
may report warnings, errors,
and fatal errors.
Fatal errors will terminate processing, all other errors may result in an
incorrect analysis of the particular code fragment.
will hapily process many illegal constructs.
will start operating as a
Web server.
At that point you must open a Web browser and connect to the location
printed on its output.
From that point onward your
contact is the Web browser
interface;
only fatal errors and progress indicators will appear on
's
standard output.
Depending on the access control list specified, you may also be
able to perform some operations over the network.
However, since
operates as a single-threaded process,
you may experience delays when another user sends a complex query.
to act as
a simple C preprocessor for the file(s) specified through a regular
expression as the option's argument.
(Typically the name of the file, and in some cases a few distinguishing
elements of its path should be enough.)
The corresponding output of
reports an error in a place where a macro is invoked,
you can examine the preprocessed output to see the result of the macro
execution.
During the
trials, this feature often located the use
of nonstandard compiler extensions, that were hidden inside header files.
To search for the corresponding error location in the postprocessed file use the
name of a nearby identifier as a bookmark, since the line numbers will not
match and
as part of your daily
build cycle to verify that the source code can always be parsed by
to
immediately exit after processing the specified file.
directives for the
directly included files.
The files that are indirectly included and unused are a lot more tricky.
They are brought into your file's compilation by the inclusion of another
file.
Even if you have control over the header file that included them
and even if your file has no use for their contents, another file
may require them, so in most cases it is best not to mess with those
files.
Finally note that it is possible to construct pathological examples of
include files that
will not detect as being required.
These will contain just parts of a statement or declaration that can not
be related to the file including them (e.g. a single operator, or a comma):
Although such a construct is legal C it is not used in practice.
's operation
it is important to define the basic concepts we will encounter:
identifiers, functions, and files.
Although you may think you know what these elements stand for,
in the
universe they have meanings sligthly different
from what you may be used to.
identifier is the longest character sequence that can
be correctly modified (e.g. renamed) in isolation.
Identifiers that will have to be renamed in unison to obtain a correct program
are grouped together and are treated as a single entity.
Although you may think that, according to our definition,
identifiers are the same as C identifiers,
this is the case only in the absence of the C preprocessor.
First of all,
the preprocessor token concatenation feature can result in
C identifiers that are composed of multiple CScout identifiers.
Consider the following example, which uses a macro to define a number
of different functions.
(Yes, I am familiar with the C++ templates, this is just an example.)
.
In addition, preprocessor macro definitions can confuse the notion of the
C scope, bringing together scopes that would be considered
separate in the context of the C language-proper.
Consider the following (slightly contrived) example:
Yet, the preprocessor macros and their use bring all the scopes together.
If we decide to change one instance of the
will change all the instances marked below,
in order to obtain a program that has the same meaning as the original
one.
, with its integrated C preprocessor, considers as functions
both the normal C functions and the function-like macros.
It can therefore identify:
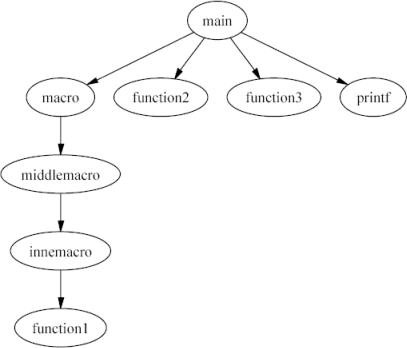
The following example illustrates all the above cases.
Note how each function name is composed of three separate parts,
and that this instance of the _ identifier occurs in
8 different function names.
files are more or less equivalent to the notion
of file you are familiar with.
The important thing to keep in mind is that
will consider
all references to the same underlying file as equivalent, no matter
how the file was named.
Thus, different paths to the same file,
or references to the same file via different symbolic links
will end-up appearing as the same file in
.
definitions
provided in workspace definition files)
to determine which elements of the compiled source code are under
your control and which elements are part of the development system.
Often the
user-interface allows you to specify whether you are
interested in writable (i.e. your project's), read-only (i.e. the system's)
or all elements.
Therefore,
all of the files that belong to your project
be writable.
Any other files used by your project but not belonging to it
(e.g. header files of third-party libraries or auto-generated code)
workspace definition commands.
is not just a browser, but a refactoring browser,
you are expected to ensure that every file in your project is
writable.
This is how
figures out which files are part
of your project and which are system files (for instance the standard
library header files).
System files
should not be writable; if any system files happen to be writable,
use the
to treat them as if
they are not writable.
sends to your browser are dynamically
generated and may contain elements that can vary from one
invocation to the next.
Therefore you should not bookmark source listings, or file or identifier
detail pages, and expect them to be available on another
invocation.
On the other hand, the pages containing results of identifier, function, or
file queries can be freely bookmarked and are identified with a comment
specifying the fact and a corresponding link.
You can therefore use your browser's bookmark facility to ``store'' such
queries for future use, or pass the URL around so that others can reproduce
your results.
Also note that often a query's results are split into pages.
The program's options allow you to specify how many elements you want to
see on each page.
Keep in mind that some browsers may choke on huge pages, so keep this
number down to a reasonable number (say below 1000).
You can navigate between result pages using the links at the bottom of
each result page page.
The link titled all will present all the query's results.
It is most useful as a way to save all the query's results into a file,
using a browser command like Save Link Target As ...
Although some of the file queries operate on identifier properties,
all file queries produce file-list data as their result.
Clicking on an element of a file list leads you to a page
with a summary of the file.
The page starts with
the projects using this file,
whether the file also exists as an exact duplicate in other locations,
and a link to browse within
the directory where the file
is located.
Four subsequent sections provide links for
exploring the file's include relationships.
The page ends with representative metrics for the given file.
Source Code Views
You can view a file's source code in five different forms:
- The plain source code, will only provide you the file's code text
- The source code with unprocessed regions marked, will enable you
to see which parts of the file was not processed due to conditional compilation
instructions.
You may want to use the marked parts as a guide to construct a
more inclusive workspace definition (perhaps by processing the
project multiple times, with different preprocessor options).
360 #if defined(__GNUC__) && defined(__STDC__)
361 static __inline int __sputc(int _c, FILE *_p) {
362 if (--_p->_w >= 0 || (_p->_w >= _p->_lbfsize && (char)_c != '\n'))
363 return (*_p->_p++ = _c);
364 else
365 return (__swbuf(_c, _p));
366 }
367 #else
368 /*
369 * This has been tuned to generate reasonable code on the vax using pcc.
370 */
371 #define __sputc(c, p) \
372 (--(p)->_w < 0 ? \
373 (p)->_w >= (p)->_lbfsize ? \
374 (*(p)->_p = (c)), *(p)->_p != '\n' ? \
375 (int)*(p)->_p++ : \
376 __swbuf('\n', p) : \
377 __swbuf((int)(c), p) : \
378 (*(p)->_p = (c), (int)*(p)->_p++))
379 #endif
380
|
- Source code with identifier hyperlinks, will provide you with
a page of the file's code text where each identifier is represented as
a hyperlink leading to the identifier's page.
The following is a representative example.
- As the above display can be overwhelming, you may prefer
to browse the source code with hyperlinks only to project-global writable
identifiers, which are typically the most important identifiers.
Consider again how the above example would be displayed:
int
copy_fifo(from_stat, exists)
struct stat *from_stat;
int exists;
{
if (exists && unlink(to.p_path)) {
warn("unlink: %s", to.p_path);
return (1);
}
if (mkfifo(to.p_path, from_stat->st_mode)) {
warn("mkfifo: %s", to.p_path);
return (1);
}
return (pflag ? setfile(from_stat, 0) : 0);
}
|
- Source code with hyperlinks to function and macro declarations
provides you hyperlinks to the function pages for each
function declaration (implicit or explict) and macro definition.
Again, here is an example:
#if !defined(_ANSI_SOURCE) && !defined(_POSIX_SOURCE)
int digittoint __P((int));
int isascii __P((int));
int isblank __P((int));
int ishexnumber __P((int));
int isideogram __P((int));
int isnumber __P((int));
int isphonogram __P((int));
int isrune __P((int));
int isspecial __P((int));
int toascii __P((int));
#endif
__END_DECLS
#define __istype(c,f) (!!__maskrune((c),(f)))
#define isalnum(c) __istype((c), _CTYPE_A|_CTYPE_D)
#define isalpha(c) __istype((c), _CTYPE_A)
#define iscntrl(c) __istype((c), _CTYPE_C)
#define isdigit(c) __isctype((c), _CTYPE_D) /* ANSI -- locale independent */
#define isgraph(c) __istype((c), _CTYPE_G)
#define islower(c) __istype((c), _CTYPE_L)
#define isprint(c) __istype((c), _CTYPE_R)
#define ispunct(c) __istype((c), _CTYPE_P)
#define isspace(c) __istype((c), _CTYPE_S)
#define isupper(c) __istype((c), _CTYPE_U)
#define isxdigit(c) __isctype((c), _CTYPE_X) /* ANSI -- locale independent */
#define tolower(c) __tolower(c)
#define toupper(c) __toupper(c)
|
Finally, you can also choose to launch your editor on the file.
The way the editor is launched is specified in CScout's
options page.
File Metrics
File metrics produces a summary of the workspace's file-based
metrics like the following:
File Metrics
Writable Files
Number of elements: 13
| Metric | Total | Min | Max | Avg |
|---|
| Number of characters | 157268 | 1923 | 43297 | 12097.5 |
| Number of comment characters | 30152 | 0 | 6307 | 2319.38 |
| Number of space characters | 28707 | 298 | 8735 | 2208.23 |
| Number of line comments | 0 | 0 | 0 | 0 |
| Number of block comments | 760 | 0 | 190 | 58.4615 |
| Number of lines | 6432 | 100 | 1913 | 494.769 |
| Maximum number of characters in a line | 1054 | 24 | 107 | 81.0769 |
| Number of character strings | 684 | 0 | 154 | 52.6154 |
| Number of unprocessed lines | 12 | 0 | 8 | 0.923077 |
| Number of C preprocessor directives | 274 | 0 | 92 | 21.0769 |
| Number of processed C preprocessor conditionals (ifdef, if, elif) | 6 | 0 | 3 | 0.461538 |
| Number of defined C preprocessor function-like macros | 30 | 0 | 22 | 2.30769 |
| Number of defined C preprocessor object-like macros | 161 | 0 | 92 | 12.3846 |
| Number of preprocessed tokens | 39529 | 393 | 12189 | 3040.69 |
| Number of compiled tokens | 44119 | 25 | 14020 | 3393.77 |
| Number of copies of the file | 13 | 1 | 1 | 1 |
| Number of statements | 4293 | 0 | 1589 | 330.231 |
| Number of defined project-scope functions | 168 | 0 | 51 | 12.9231 |
| Number of defined file-scope (static) functions | 2 | 0 | 1 | 0.153846 |
| Number of defined project-scope variables | 149 | 1 | 36 | 11.4615 |
| Number of defined file-scope (static) variables | 109 | 0 | 92 | 8.38462 |
| Number of complete aggregate (struct/union) declarations | 12 | 0 | 6 | 0.923077 |
| Number of declared aggregate (struct/union) members | 56 | 0 | 32 | 4.30769 |
| Number of complete enumeration declarations | 0 | 0 | 0 | 0 |
| Number of declared enumeration elements | 0 | 0 | 0 | 0 |
| Number of directly included files | 62 | 0 | 9 | 4.76923 |
Read-only Files
Number of elements: 15
| Metric | Total | Min | Max | Avg |
|---|
| Number of characters | 43094 | 227 | 9876 | 2872.93 |
| Number of comment characters | 26967 | 107 | 5695 | 1797.8 |
| Number of space characters | 3179 | 13 | 948 | 211.933 |
| Number of line comments | 12 | 0 | 12 | 0.8 |
| Number of block comments | 128 | 0 | 60 | 8.53333 |
| Number of lines | 1198 | 13 | 275 | 79.8667 |
| Maximum number of characters in a line | 1073 | 48 | 85 | 71.5333 |
| Number of character strings | 62 | 0 | 58 | 4.13333 |
| Number of unprocessed lines | 17 | 0 | 5 | 1.13333 |
| Number of C preprocessor directives | 288 | 1 | 102 | 19.2 |
| Number of processed C preprocessor conditionals (ifdef, if, elif) | 27 | 0 | 6 | 1.8 |
| Number of defined C preprocessor function-like macros | 30 | 0 | 13 | 2 |
| Number of defined C preprocessor object-like macros | 87 | 0 | 31 | 5.8 |
| Number of preprocessed tokens | 3461 | 16 | 1068 | 230.733 |
| Number of compiled tokens | 1779 | 0 | 602 | 118.6 |
| Number of copies of the file | 15 | 1 | 1 | 1 |
| Number of statements | 0 | 0 | 0 | 0 |
| Number of defined project-scope functions | 0 | 0 | 0 | 0 |
| Number of defined file-scope (static) functions | 0 | 0 | 0 | 0 |
| Number of defined project-scope variables | 6 | 0 | 3 | 0.4 |
| Number of defined file-scope (static) variables | 0 | 0 | 0 | 0 |
| Number of complete aggregate (struct/union) declarations | 7 | 0 | 3 | 0.466667 |
| Number of declared aggregate (struct/union) members | 56 | 0 | 23 | 3.73333 |
| Number of complete enumeration declarations | 0 | 0 | 0 | 0 |
| Number of declared enumeration elements | 0 | 0 | 0 | 0 |
| Number of directly included files | 24 | 0 | 20 | 1.6 |
Main page
— Web: Home
Manual
|
All files
The "All files" link will list all the project's files, including
source files, and directly and indirectly included files.
You can use this list to create a "bill of materials" for the files your
workspace requires to compile.
The following is an example of the output:
All Files
You can bookmark this page to save the respective query Main page
CScout 1.6 - 2003/06/04 15:14:51
|
Read-only files
The "Read-only files" link will typically show you the system files your
project used.
The following output was generated using the "Show file lists with file name in context" option.
Read-only Files
You can bookmark this page to save the respective query Main page
- Web: Home
Manual
CScout 2.0 - 2004/07/31 12:37:12
|
Writable files
Correspondingly the "Writable files" link will only show you all your
workspace's source files:
Writable Files
You can bookmark this page to save the respective query Main page
CScout 1.6 - 2003/06/04 15:14:51
|
Files containing unused project-scoped writable identifiers
The link
``files containing unused project-scoped writable identifiers''
performs an identifier query, but lists as output files containing
matching identifiers.
Specifically, the link will produce a list of files containing
global (project-scoped) unused writable identifiers.
Modern compilers can detect unused block-local or even file-local
(static) identifiers, but
detecting global identifiers is more tricky, since it requires
processing of all files that will be linked together.
The restriction to writable identifiers will filter-out noise
generated through the use of the system's library functions.
In our example, the following list is generated:
Files Containing Unused Project-scoped Writable Identifiers
Matching Files
You can bookmark this page to save the respective query Main page
- Web: Home
Manual
CScout 2.0 - 2004/07/31 12:37:12
|
The output contains the path to each file, and a link that will
generate the file's source code with the offending identifiers
marked as hyperlinks.
You can use the ``marked source'' link to inspect the identifiers in the
context of their source code;
simply follow the link with your browser and press tab
to go to each hyperlink.
In our example the identifier will appear as follows:
void
setthetime(fmt, p, jflag, nflag)
const char *fmt;
register const char *p;
int jflag, nflag;
{
register struct tm *lt;
struct timeval tv;
const char *dot, *t;
int century;
|
(In our case the function setthetime is declared as
static, but not defined as such.)
Files containing unused file-scoped writable identifiers
The link
``files containing unused file-scoped writable identifiers''
performs an identifier query, but lists as output files containing
matching identifiers.
Specifically, the link will produce a list of files containing
file-scoped (static) unused writable identifiers.
Although some modern compilers can detect file-local
identifiers, they fail to detect macros and some types of
variable declarations.
The CScout query is more general and can be more reliable.
The restriction to writable identifiers will filter-out noise
generated through the use of the system's library functions.
In our example, the following list is generated:
Files Containing Unused File-scoped Writable Identifiers
Matching Files
You can bookmark this page to save the respective query Main page
- Web: Home
Manual
CScout 2.0 - 2004/07/31 12:37:12
|
In our case all identifiers located were the
copyright and the rcsid
identifiers.
#ifndef lint
static char const copyright[] =
"@(#) Copyright (c) 1989, 1993\n\
The Regents of the University of California. All rights reserved.\n";
#endif /* not lint */
#ifndef lint
#if 0
static char sccsid[] = "@(#)echo.c 8.1 (Berkeley) 5/31/93";
#endif
static const char rcsid[] =
"$FreeBSD: src/bin/echo/echo.c,v 1.8.2.1 2001/08/01 02:33:32 obrien Exp $";
#endif /* not lint */
|
Later on we will explain how an identifier query could have used a regular
expression to filter-out the noise generated by these two identifiers.
Writable .c files without any statements
The
``writable .c files without any statements''
will locate C files that do not contain any C statements.
You can use it to locate files that only contain variable definitions,
or files that are #ifdef'd out.
In our example,
the result set only contains the processing script
(the compiled workspace definition file).
Writable .c Files Without Any Statments
You can bookmark this page to save the respective query Main page
CScout 1.6 - 2003/06/04 15:14:51
|
The processing script (the compiled workspace definition file)
follows the C syntax,
but only contains preprocessor directives
(mostly CScout-specific #pragma commands)
to drive the CScout's source code analysis.
Writable files containing unprocessed lines
The ``writable files containing unprocessed lines'' link will present you
C files containing lines that were skipped by the C preprocossor,
due to conditional compilation directives.
The files are ordered according to the number of unprocessed lines
(files with the largest number will appear on the top).
In our case the results are:
Writable Files Containing Unprocessed Lines
You can bookmark this page to save the respective query Main page
- Web: Home
Manual
CScout 2.0 - 2004/07/31 12:37:12
|
Lines skipped by the C preprocessor can be detrimental to the analysis
and the refactoring you perform.
If those lines contain live code that will be used under some other
circumstances (a different platform, or different configuration options),
then any results you obtain may miss important data.
The list of files allows you to see if there are any large chunks of
code that CScout ignored.
If there are, think about specifying additional configuration options as
preprocessor variables.
If some configuration options are mutually exclusive you can process the same
source multiple times, with different preprocessor variables set.
Writable files containing strings
The ``writable files containing strings'' link will present you
C files containing C strings.
In some applications user-messages are not supposed to be put
in the source code, to aid localization efforts.
This file query can then help you locate files that contain
strings.
In our case the results are:
Writable Files Containing Strings
You can bookmark this page to save the respective query Main page
CScout 1.6 - 2003/06/04 15:14:51
|
Writable .h files with #include directives
Some coding conventions dictate against recursive #include
invocations.
This query can be used to find files that break such a guideline.
As usual, read-only system files are excluded; these typically
use recursive #include invocations as a matter of course.
In our example, the result is:
Writable .h Files With #include directives
You can bookmark this page to save the respective query Main page
CScout 1.6 - 2003/06/04 15:14:51
|
Generic File Queries
A generic file query is a powerful mechanism for locating files
that match the criteria you specify.
All the ready-made file queries that CScout provides you are
just URLs specifying saved instances of generic queries.
You specify the query through the following form:
You start by specifying whether the file should be
writable (i.e. typically part of your application)
and/or
readable (i.e. typically part of the compiler or system).
Next come a series of metrics CScout collects for each
file.
For each metric (e.g. the number of comments) you can specify
an operator ==, !=, < or > and a number
to match that metric against.
Thus to locate files without any comments you would specify
Number of block comments == 0.
On the left of each metric you can specify whether that metric
will be used to sort the resulting file list.
In that case, the corresponding number will appear together with
each file listed.
A separate option allows you to specify that files should be sorted
in the reverse order.
You can request to see files matching any of your specifications
(Match any of the above) or to see files matching all your
specifications
(Match all of the above).
Sometimes you may only want to search in a subset of files;
you can then specify a regular expression that filenames should
match (or not match) against: "File names should (not) match RE".
Finally, you can also specify a title for your query.
The title will then appear on the result document annotating the
results, and will also provide you with a sensible name when creating a
bookmark to it.
Include Graphs
CScout can create include graphs that list how files include each
other.
Two global options
specify the format of the include graph and the content
on each graph's node.
Through these options you can obtain graphs in
- plain text form: suitable for processing with other tools,
- HTML: suitable for browsing via CScout,
- dot: suitable for generating high-quality graphics files,
- SVG: suitable for graphical browsing, if your browser supports this format, and
- GIF: suitable for viewing on SVG-challenged browsers.
All diagrams follow the notation
including file -> included file
Two links on the main page
(file include graph - writable files and
file include graph - all files)
can give you the include graphs of the complete program.
For programs larger than a hundred thousand lines,
these graphs are only useful in their textual form.
In their graphical form, even with node information disabled,
they can only serve to give you a rough idea of how the program is
structured.
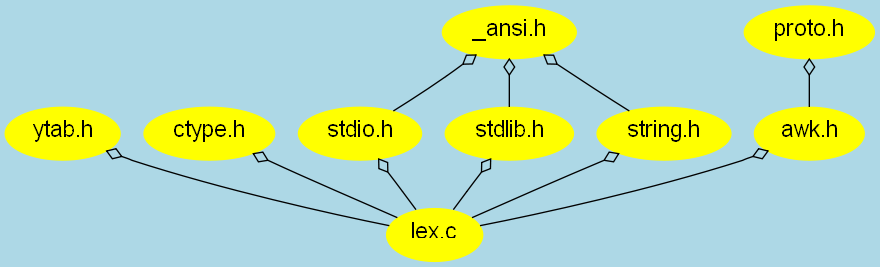
The following image depicts how writable (non-system) files are
included in the awk source code.

and the following is a part of the include file structure of the
Windows Research Kernel

More useful are typically the include graphs that can be generated for
individual files.
These can allow you to see what paths can possibly lead to the inclusion
of a given file (include graph of all including files) or what files
a given file includes (include graph of all included files).
(call graph of all callers),
which functions can be reached starting from a given function,
and how functions in a given file relate to each other.
As an example, the following diagram depicts all files that
main.c includes
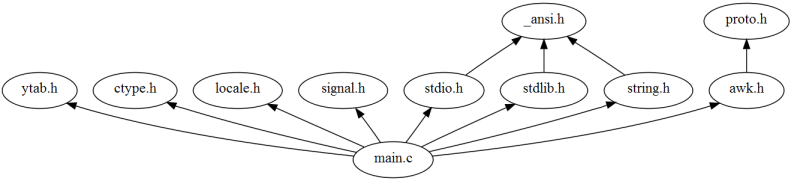
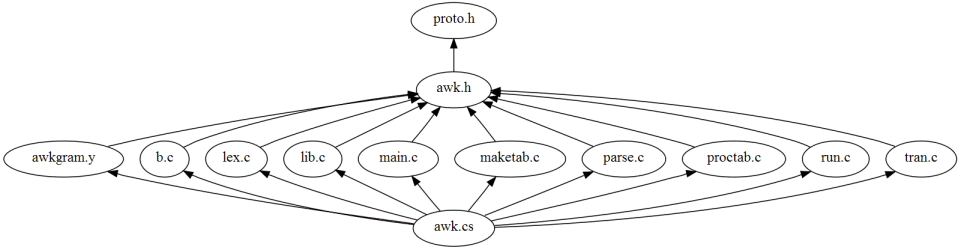
while the following diagrams shows all the files including
(directly or indirectly)
proto.h.
C Namespaces
To understand identifier queries it is best to refresh our notion of the
C namespaces.
The main way we normally reuse identifier names in C programs is
through scoping: an identifier within a given scope
such as a block or declared as static within a file
will not interfere with identifiers outside that scope.
Thus, the following example will print 3 and not 7.
int i = 3;
foo()
{
int i = 7;
}
main()
{
foo();
printf("%d\n", i);
}
CScout analyzes and stores each identifier's scope performing
substitutions accordingly.
In addition, C also partitions a program's identifiers into four
namespaces.
Identifiers in one namespace, are also considered different from
identifiers in another.
The four namespaces are:
- Tags for a
struct/union/enum
- Members of
struct/union
(actually a separate namespace is assigned
to each struct/union)
- Labels
- Ordinary identifiers (termed objects in the C standard)
Thus in the following example all id identifier instances are
different:
/* structure tag */
struct id {
int id; /* structure member */
};
/* Different structure */
struct id2 {
char id; /* structure member */
};
/* ordinary identifier */
id()
{
id: /* label */
}
Furthermore, macro names and the names of macro formal arguments also
live in separate namespaces within the preprocessor.
Normally when you want to locate or change an identifier name,
you only consider identifiers in the same scope and namespace.
Sometimes however,
a C preprocessor macro can semantically unite identifiers
living in different namespaces, so that changes in one of them
should be propagated to the others.
The most common case involves macros that access structure members.
struct s1 {
int id;
} a;
struct s2 {
char id;
} b;
#define getid(x) ((x)->id)
main()
{
printf("%d %c", getid(a), getid(b));
}
In the above example, a name change in any of the id
instances should be propagated to all others for the program to
retain its original meaning.
CScout understands such changes and will propagate any changes
you specify accordingly.
Finally, the C preprocessor's token concatenation feature can result
in identifiers that should be treated for substitution purposes in
separate parts.
Consider the following example:
int xleft, xright;
int ytop, ybottom;
#define coord(a, b) (a ## b)
main()
{
printf("%d %d %d %d\n",
coord(x, left),
coord(x, right),
coord(y, top),
coord(y, bottom));
}
In the above example, replacing x in one of the coord
macro invocations should replace the x part in the
xleft and xright variables.
Again CScout will recognize and correctly handle this code.
Identifier Elements
All identifier queries produce identifier lists data as their result.
Clicking on an identifier in the list will lead you to a page
like the following.
As you see, for each identifier CScout will display:
- If the identifier is read-only (i.e. it appears in at least one
read-only file)
- The C namespace(s) it appears in (the same identifier can be a member
of multiple namespaces)
- Whether the identifier is visible at file or project scope
- Whether the identifier is a
typedef
(typedef's belong to the ``ordinary identifier'' namespace,
but are obviously important, so CScout will tag them as such).
- Whether the identifier crosses a file boundary, i.e. it appears in
more than one file
- Whether the identifier is unused i.e. it appears in exactly one location
- The identifier's number of occurences in all the workspace's files
- The projects the identifier appears in
- The function names the identifier forms; the link
"function page" will provide you more details regarding the function
- An option to substitute the identifier's name with a different name
The substitution will globally replace the identifier (or the
identifier part) in all namespaces, files, and scopes required for
the program to retain its original meaning.
No checks for name collisions are made, so ensure that the name you
specify is unique for the appropriate scope.
Performing the substitution operation will not change the identifier's
name in the current invocation of CScout.
However, once you have finished your browsing and replacing session,
you have an option to terminate CScout and write back all
the subtitutions you made to the respective source files.
Finally, the identifier's page will list the writable and all files
the specific identifier appears in.
Clicking on the ``marked source'' hyperlink will display the respective
file's source code with only the given identifier marked as a hyperlink.
By pressing your browser's tab
key you can then see where the given identifier is used.
In our example the cp.c source code
with the copy_file identifier marked
would appear as follows:
case S_IFBLK:
case S_IFCHR:
if (Rflag) {
if (copy_special(curr->fts_statp, !dne))
badcp = rval = 1;
} else {
if (copy_file(curr, dne))
badcp = rval = 1;
}
break;
case S_IFIFO:
if (Rflag) {
if (copy_fifo(curr->fts_statp, !dne))
badcp = rval = 1;
} else {
if (copy_file(curr, dne))
badcp = rval = 1;
}
break;
default:
if (copy_file(curr, dne))
badcp = rval = 1;
break;
}
|
Identifier Metrics
The identifier metrics page displays a summary of metrics related to
identifier use.
In our example, the metrics are as follows:
Identifier Metrics
Writable Identifiers
| Identifier class | Distinct # ids | Total # ids | Avg length | Min length | Max length |
|---|
| All identifiers | 1439 | 10472 | 3.72272 | 1 | 17 |
| Tag for struct/union/enum | 10 | 24 | 4.7 | 2 | 9 |
| Member of struct/union | 56 | 721 | 4.21429 | 1 | 10 |
| Label | 7 | 16 | 5.28571 | 2 | 9 |
| Ordinary identifier | 1149 | 8342 | 3.51175 | 1 | 17 |
| Macro | 185 | 1298 | 5.16216 | 2 | 10 |
| Undefined macro | 2 | 2 | 8.5 | 6 | 11 |
| Macro argument | 30 | 69 | 1 | 1 | 1 |
| File scope | 159 | 1493 | 5.47799 | 2 | 17 |
| Project scope | 277 | 2442 | 6.28881 | 2 | 12 |
| Typedef | 9 | 720 | 5.22222 | 2 | 8 |
| Enumeration constant | 0 | 0 | - | 0 | 0 |
| Function | 177 | 1455 | 6.58192 | 3 | 17 |
Read-only Identifiers
| Identifier class | Distinct # ids | Total # ids | Avg length | Min length | Max length |
|---|
| All identifiers | 375 | 1180 | 6.36 | 1 | 18 |
| Tag for struct/union/enum | 5 | 14 | 5.4 | 2 | 7 |
| Member of struct/union | 56 | 67 | 7.80357 | 2 | 17 |
| Label | 0 | 0 | - | 0 | 0 |
| Ordinary identifier | 164 | 604 | 6.04878 | 3 | 14 |
| Macro | 116 | 409 | 7.47414 | 2 | 18 |
| Undefined macro | 17 | 154 | 9 | 4 | 15 |
| Macro argument | 33 | 83 | 1.42424 | 1 | 4 |
| File scope | 12 | 131 | 7.25 | 4 | 14 |
| Project scope | 152 | 473 | 5.95395 | 3 | 13 |
| Typedef | 12 | 131 | 7.25 | 4 | 14 |
| Enumeration constant | 0 | 0 | - | 0 | 0 |
| Function | 146 | 449 | 5.84247 | 3 | 10 |
Main page
- Web: Home
Manual
CScout
|
You can use these metrics to compare characteristics of different
projects, adherance to coding standards, or to identify identifier
classes with abnormally short or long names.
The ratio between the distinct number of identifiers
and the total number of identifiers is the number of times each
identifier is used.
Notice the difference in our case between the read-only identifiers
(which are mostly declarations) and the writable identifiers (which
are actually used).
All identifiers
The all identifiers page will list all the identifiers in your project in
alphabetical sequence.
In large projects this page will be huge.
Read-only identifiers
The ``read-only identifiers'' page will only list the read-only identifiers
of your project in alphabetical sequence.
These typically become part of the project through included header files.
Writable identifiers
The ``writable identifiers'' page will only list the writable identifiers
of your project in alphabetical sequence.
These are typically the identifiers your project has defined.
In large projects this page will be huge.
File-spanning writable identifiers
The ``file-spanning writable identifiers'' page will only list your
project's identifiers that span a file boundary.
Refactoring operations and coding standards typically pay higher attention
to such identifiers, since they tend occupy the project's global namespace.
In our example, the following page is generated:
Unused project-scoped writable identifiers
The unused project-scoped writable identifiers are useful to know,
since they can pinpoint functions or variables that can be eliminated
from a workspace.
Unused file-scoped writable identifiers
The unused file-scoped writable identifiers can also
pinpoint functions or variables that can be eliminated from a file.
In our example the following list is generated:
Notice how distinct identifiers appear as separate entries.
Unused writable macros
Finally, the unused writable macros page will list macros that are not used
within a workspace.
In our case the list contains an identifier that was probably used in an
earlier version.
Unused Writable Macros
Matching Identifiers
RETAINBITS
You can bookmark this page to save the respective query Main page
CScout 1.6 - 2003/06/04 15:14:51
|
Generic Identifier Queries
The generic identifier query feature of CScout is one of
its most powerfull features, allowing you to accurately specify
the properties of identifiers you are looking for, by means of
the following form.
In the form you specify:
- The properties (namespace, scope, instances) of the identifier
- Whether the specified properties should be
treated
- as a disjunction (match any marked),
- as a conjunction (match all marked),
- as a negation excluding all identifiers matching any property (exclude marked), or
- as an exact match specification matching only identifiers that match
exactly the properties specified (exact match)
- A regular expression against which identifier names should match
(or not match)
- A regular expression that filenames in which identifiers occur should
match (or not match)
- A query title to be used for naming the result page.
The title will appear on the result document annotating the
results, and will also provide you with a sensible name when creating a
bookmark to it.
Through the query's submission button can choose to obtain as a result
- the identifiers that match the specific query,
- the files containing identifiers that match the query, or
- the functions containing identifiers that match the query.
In the second case (matching files),
each file in the file list will provide you with
a link (marked source) showing the file's source code with all matched
identifiers marked using hyperlinks.
As an example, the following query could be used to identify
unused file-scoped writable identifiers, but excluding
the copyright and rcsid identifiers:
Identifier Query
Main page
CScout 1.16 - 2003/08/17 12:13:01
|
Function Elements
Every function (C function or function like macro) is associated with
a page like the following.
From this page you can refactor the function's arguments
(more on this in the next section) and obtain the following data.
- The identifier or identifiers composing the function name.
These can be modified (from the corresponding identifier page)
to change the function's name.
- The function's declaration. This may be an implicit declaration
(the location of its first use).
CScout only maintains the location of one declaration for
each function.
You can locate additional points of declaration by looking at the
places where the corresponding identifier is used.
The "marked source" link allows you to see the declaration as
a hyperlink in the file where it occurs.
In many browsers pressing the tab key on that page will lead you
directly to the function's declaration.
- The function's definition (if a definition was found).
Library functions obviously will not have a definition associated with them.
- The number of functions this function directly calls.
These are the functions (C functions and function-like macros)
that appear inside the function's body.
-
A list allowing you to explore interactively the tree of called functions.
The tree will appear in the following form:
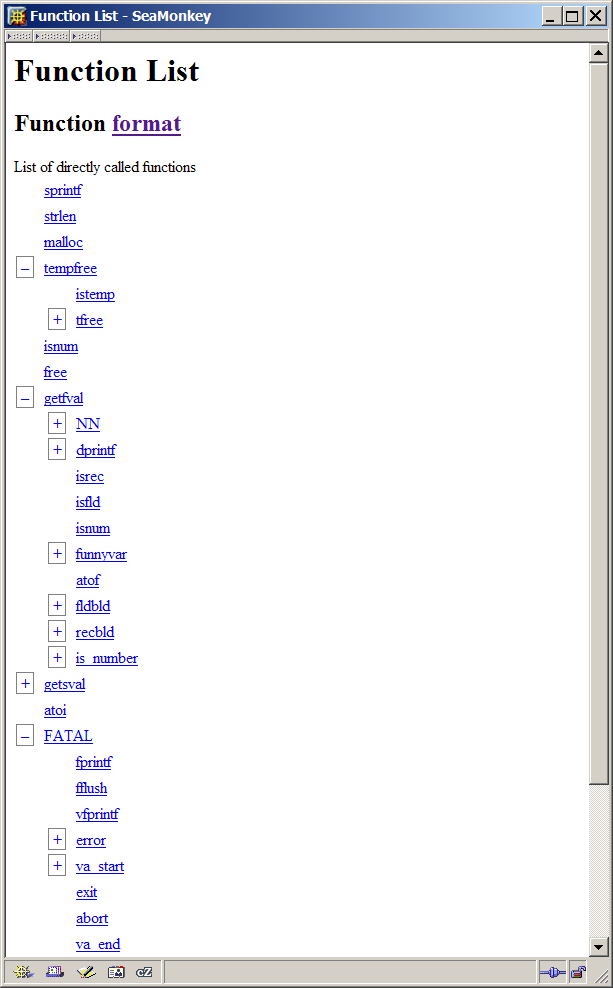
Each plus or minus box will open or close the list of called functions.
Each function name is a hyperlink to the corresponding function page.
- A list of all called functions.
This list includes all functions that can be called,
starting from the function we are examining.
On the right of each function is
a hyperlink to a call graph of the path(s) leading from
the function being examined to the function listed.
- A call graph of all called functions (explained in a following section).
- A page allowing you to explore interactively all callers.
These are the functions that directly call the function we are examining.
The functionality of this page is the same as that of the one for exploring
the called functions.
- A list of all callers.
These are all functions that can directly or
indirectly call the function we are examining.
- A call graph of all callers (explained in a following section).
- A call graph of all the function's callers and called functions
showing the function in context (explained in a following section).
- A comprehensive set of metrics regarding the function
(only for defined functions and macros).
All Functions
The all functions page will list all the functions (C functions
and function-like macros) defined or declared
in the CScout workspace.
In moderately sized projects,
you can use it as a starting point for jumping to a function;
in larger projects it is probably useful only as a last resort.
Project-scoped writable functions
This page contains all the writable functions that are globaly visible.
The page does not list function-like macros.
File-scoped writable functions
This page contains all the writable functions that are visible only
within the context of a single file.
This include C functions declared as static, and function-like
macros.
Writable functions that are not directly called
This page will list all writable functions that are never directly
called.
The most probable cause is that the corresponding functions are called through
a pointer,
but some may be historic leftovers - candidates for removal.
Writable functions that are called exactly once
Functions that are called exactly once may be candidates for inlining.
Refactoring Function Arguments
A text box appearing on a function's page allows the refactoring of
a function's arguments across all identified calls of the function.
This box will appear only for functions whose identifiers are
writable (i.e. all instances of them appear in writable files),
and where there is a one to one correspondence between the function
name and the corresponding identifier.
If the same identifier is aliased through a macro to refer to various functions
or if a function's name is generated by pasting together multiple identifiers,
then the function argument refactoring facility will not be made available
for that function.
The requirement for the function's identifier to be writable can be overridden
through the options page.
To refactor the function's arguments, one simply enters in the text box
a template describing the argument replacement pattern.
The template consists of text, which is copied verbatim as a function's
argument, and elements starting with the operator @, which have a special
meaning.
The combined effect of this template mechanism allows you to
- Introduce new arguments
- Remove existing arguments
- Change the arguments' order
The following types of @ operator are supported.
N is always an integer starting from 1, and denotes the function's Nth argument.
@N- pastes the original Nth argument passed to the function.
Thus, @1 will get replaced with the function's first argument.
Specifying in a template for a function taking two arguments "
@2, @1" will
swap their order, while specifying "@1, sizeof(@1), stdin" as
the arguments for gets will refactor them in a form suitable for
calling fgets (if the original argument refers to a fixed-size character array).
@.N- pastes the Nth argument and all subsequent ones, separated
by commas.
This is useful for handling functions with a variable number of arguments,
like printf.
Specifying in a template for the printf function
"
stdout, @1, @.2" will introduce an extra first parameter, named stdout.
(Presumably the function will also be renamed to fprintf.)
@+N{...}- pastes the text in the braces, if the specific
function being replaced has an Nth argument.
The text in the braces can include arbitrary text,
including nested @ operators.
@-N{...}- pastes the text in the braces, if the specific
function being replaced does not have an Nth argument.
The last two operators can often be combined to achieve more complex results.
For instance, the template "@1, @2, @+3{@3}@-3{NULL}" will add to any
call to the function missing a third argument, a third argument with a
value of NULL.
Note that the refactorings will take place on all instances where the
identifier is found to match the function or macro.
This includes declarations and definitions
(which might require some hand-editing if arguments are introduced),
and the appearance of the name in the replacement
text of a macro, when that macro is used in a way that makes the function
match the one being refactored.
The replacements will not be performed to function calls that are executed
through a function pointer.
Call Graphs
CScout can create call graphs that list how functions call each
other.
Keep in mind that the graphs only indicate the calls detected by statically
analyzing the program source.
Calls via function pointers will not appear in the call graph.
Two global options
specify the format of the call graph and the content
on each graph's node.
Through these options you can obtain graphs in
- plain text form: suitable for processing with other tools,
- HTML: suitable for browsing via CScout,
- dot: suitable for generating high-quality graphics files,
- SVG: suitable for graphical browsing, if your browser supports this format, and
- GIF: suitable for viewing on SVG-challenged browsers.
All diagrams follow the notation
calling function -> called function
Two links on the main page
(function and macro call graph, and non-static function call graph)
can give you the call graphs of the complete program.
For any program larger than a few thousand lines,
these graphs are only useful in their textual form.
In their graphical form, even with node information disabled,
they can only serve to give you a rough idea of how the program is
structured.
The following image depicts how the three different programs we
analyzed in the bin example relate to each other.

More useful are the call graphs that can be generated for individual
functions or files.
These can allow you to see what paths can possibly lead to a given function
(call graph of all callers),
which functions can be reached starting from a given function,
the function in context,
and how functions in a given file relate to each other.
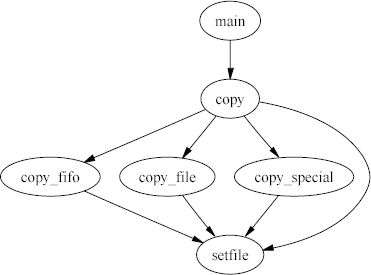
As an example, the following diagram depicts all paths leading to the
setfile function.
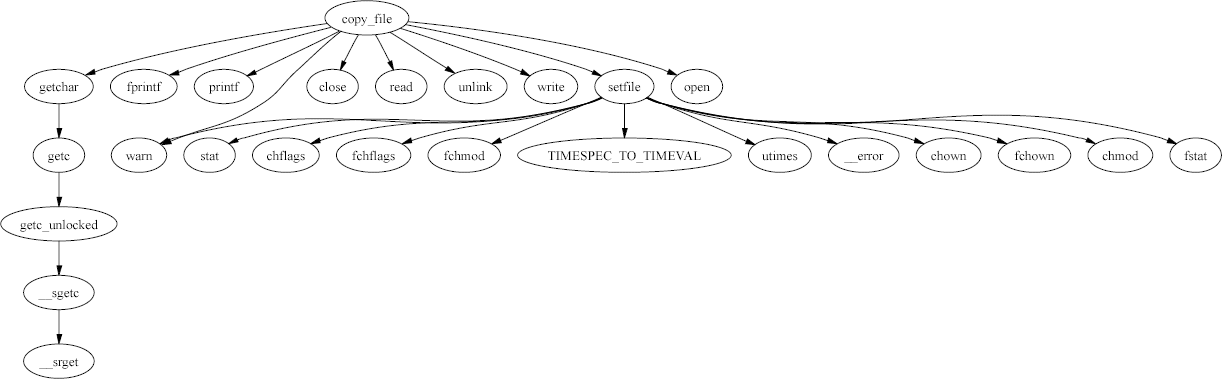
Correspondingly, the functions that can be reached starting from the
copy_file function appears in the following diagram.
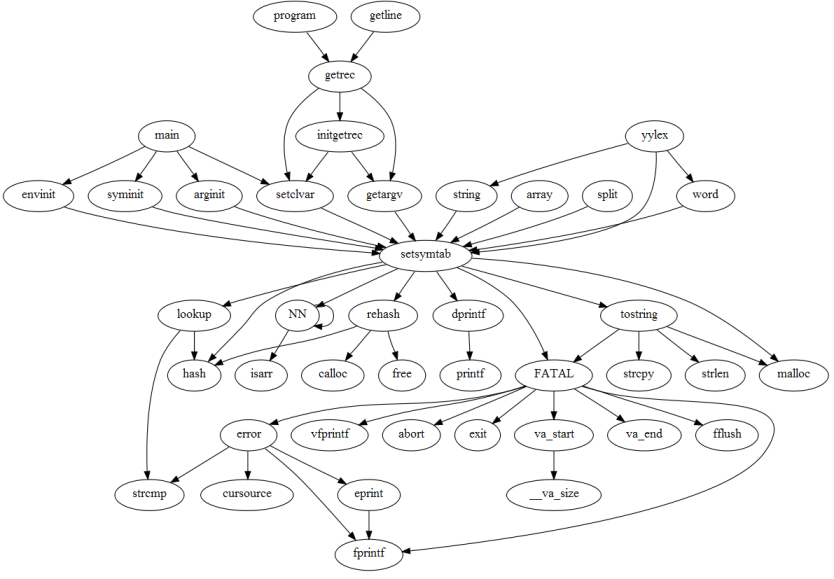
while the following shows the function setsymtab in context,
depicting all the paths leading to it (callers) and leaving from it
(called functions).
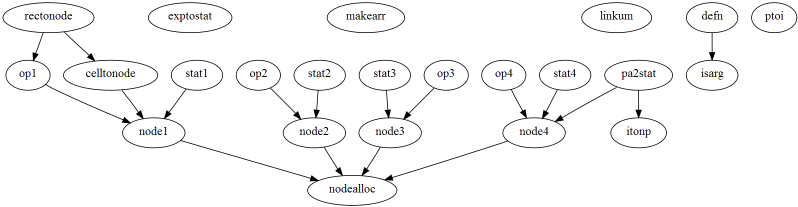
Finally, the following is an example of how the functions in a single
file (parse.c) relate to each other.
Generic Function Queries
The generic function query allows you to select functions by
means of the following form.
On the top you can specify whether each function you want listed:
- is a C function
- is a function-like macro
- has a writable declaration
- has a read-only declaration
- is visible in the whole project scope
- is visible only in a file scope
- has a definition body.
As is the case in file queries,
next comes a series of metrics CScout collects for each
defined function.
For each metric (e.g. the number of comments) you can specify
an operator ==, !=, < or > and a number
to match that metric against.
Thus to locate functions containing goto statement
you would specify
Number of goto statements != 0.
On the left of each metric you can specify whether that metric
will be used to sort the resulting file list.
In that case, the corresponding number will appear together with
each file listed.
A separate option allows you to specify that files should be sorted
in the reverse order.
Similarly to the identifier query,
you can also specify whether the specified properties should be treated
- as a disjunction (match any marked),
- as a conjunction (match all marked),
- as a negation excluding all identifiers matching any property (exclude marked), or
- as an exact match specification matching only identifiers that match
exactly the properties specified (exact match)
In addition you can specify:
- That the function should have a specified number of direct callers.
- A regular expression against which function names should match
(or not match)
- A regular expression against which the names of calling functions should match
(or not match)
- A regular expression against which the names of any called functions should match
(or not match)
- A regular expression that filenames in which functions are declared occur should
match (or not match)
- A query title to be used for naming the result page.
The title will appear on the result document annotating the
results, and will also provide you with a sensible name when creating a
bookmark to it.
Global Options
The operations CScout provides group together functions
that globally affect its operation.
The global options link leads you to the following page.
The meaning of each option is described in the following sections.
File and Identifier Pages
Show Only True Identifier Classes
Setting the option ``show only true identifier classes (brief view)''
will remove from each identifier page all identifier properties
marked as no, resulting in a less verbose page.
Show Associated Projects
Normally, each identifier or file page lists the projects in which
the corresponding identifier or file has appeared during processing.
When the CScout workspace typically consists only of a single project,
or consists of hundreds of projects, listing the project membership
can be useless or result into too volumneous output.
The corresponding option can be used to control this output.
Show Lists of Identical Files
CScout will detect during processing when a file is an exact
duplicate of another file (typically the result of a copy operation
during the building process).
On the file information page it will then list the files that are
duplicates of the one being listed.
The corresponding option can be used to control this output.
Source Listings
Show Line Numbers
The "show line numbers in source listings" option
allows you to specify whether the source file line numbers will be shown
in source listings.
Line numbers can be useful when you are editing or viewing the same
file with an editor.
A file with line numbers shown appears as follows:
78 fa *makedfa(const char *s, int anchor) /* returns dfa for reg expr s */
79 {
80 int i, use, nuse;
81 fa *pfa;
82 static int now = 1;
83
84 if (setvec == 0) { /* first time through any RE */
85 maxsetvec = MAXLIN;
86 setvec = (int *) malloc(maxsetvec * sizeof(int));
87 tmpset = (int *) malloc(maxsetvec * sizeof(int));
88 if (setvec == 0 || tmpset == 0)
89 overflo("out of space initializing makedfa");
90 }
91
92 if (compile_time) /* a constant for sure */
93 return mkdfa(s, anchor);
94 for (i = 0; i < nfatab; i++) /* is it there already? */
95 if (fatab[i]->anchor == anchor
96 && strcmp((const char *) fatab[i]->restr, s) == 0) {
97 fatab[i]->use = now++;
98 return fatab[i];
99 }
100 pfa = mkdfa(s, anchor);
101 if (nfatab < NFA) { /* room for another */
102 fatab[nfatab] = pfa;
103 fatab[nfatab]->use = now++;
104 nfatab++;
105 return pfa;
106 }
|
Tab Width
The ``code listing tab width'' option allows you to specify
the tab width to use when listing source files as hypertext
(8 by default).
The width should match the width normally used to display the file.
It does not affect the way the modified file is written;
tabs and spaces will get written exactly as found in the source code file.
Refactoring
Allow the renaming of read-only identifiers
Setting this option will present a rename identifier box,
in an identifier's page, even if that identifier occurs in read-only
files.
When CScout exist saving refactoring changes,
replacements in those files may fail due to file system permissions.
Allow the refactoring of function arguments of read-only functions
Setting this option will present a function argument refactoring template
input box
in an function's page, even if that identifier associated with the
function occurs in read-only files.
Check for renamed identifier clashes when saving refactored code
Setting this option will reprocess the complete source code (re-execute
the processing script) before saving code with renamed identifiers,
in order to verify that no accidental clashes were introduced.
Identifier clashes are reported on the command-line console as errors.
The check is enabled by default.
For very large projects and if you are sure no clashes were accidentally
introduced you may disable the check in order to save the additional
processing time.
Queries
Case-insensitive File Name Regular Expression Match
Some environments, such as Microsoft Windows,
are matching filenames in a case insensitive manner.
As a result the same filename may appear with different
capitalization (e.g. Windows.h, WINDOWS.h, and
windows.h).
The use of the
``case-insensitive file name regular expression match''
option makes filename regular expression matches
ignore letter case thereby matching the operating system's semantics.
Query Result Lists
Number of Entries on a Page
The number of entries on a page, specifies the number of records
appearing on each separate page resulting
from a file, identifier, or function query.
Too large values of this option (say above 1000) may cause your
web browser to behave sluggishly, and will also reduce the program's
responsiveness when operating over low-bandwidth network links.
Show File Lists With File Name in Context
Setting the ``Show file lists with file name in context'' option
will result in file lists showing the file name (the last component
of the complete path) in the same position,
as in the following example:
Read-only Files
You can bookmark this page to save the respective query Main page
|
This results in lists that are easier to read, but that can not
be easilly copy-pasted into other tools for further processing.
Sort Identifiers Starting from their Last character
Some coding conventions use identifier suffixes for distinguishing the
use of a given identifier.
As an example, typedef identifiers often end in _t.
The following list contains our example's typedefs ordered by the last
character, making it easy to distinguish typedefs not ending
in _t
Call and File Dependency Graphs
Call Graph Links Should Lead to Pages of
Function and macro call graphs can appear in four different formats.
- Plain text: suitable for processing with other text tools.
- HTML: suitable for interactive browsing
- dot: suitable for processing with GraphViz dot into different
graphics formats, like PNG, MIF, VRML, and EPS.
Dot files can also be processed as graphs using the
AT&T gpr program
- SVG: suitable for interactively browsing the graphical representation
of the call graph.
This option requires your browser to support the rendering of SVG
(directly or via a plugin, such as
Adobe's (http://www.adobe.com/svg/)), and the existence of
the AT&T GraphViz (http://www.graphviz.org) dot
program in your executable file path.
- GIF: suitable for directly viewing relatively small images.
Call Graphs Should Contain
This option allows you to specify the level of detail you wish to see
in the call graph nodes.
- Only edges, will not display anything on the node.
This option can be used in the graphics formats (dot, SVG, GIF) to
provide an overall picture of the program's call structure.
- Function names: only include the function names.
Functions with the same name will still be separately listed,
but you will have to follow their hyperlinks to see where they
are defined.
- File and function names: the name of the file where a function
is declared will precede the name of the function.
- Path and function names: the complete file path of the file
where a function
is declared will precede the name of the function.
File Graphs Should Contain
This option allows you to specify the level of detail you wish to see
in the file dependency graph nodes.
- Only edges, will not display anything on the node.
This option can be used in the graphics formats (dot, SVG, GIF) to
provide an overall picture of the program's file dependency structure.
- File names: only include the file names.
Files with the same name will still be separately listed,
but you will have to follow their hyperlinks to see where they
are defined.
- Path and file names: the complete path of each path will be show.
Maximum number of call levels in a graph
Call graphs can easily grow too large for viewing, printing, or even
formatting as a graph.
This option limits the number of functions that will be traversed from a
specific function when computing a call graph
or a list of calling or called functions.
Maximum dependency depth in a file graph
File dependency graphs can easily grow too large for viewing, printing, or even
formatting as a graph.
This option limits the number of edges that will be traversed from the root
file when computing a file dependency graph.
Include URLs in dot output
By checking this option
URLs to CScout's interface will be included in plain dot
output.
In typical cases, URLs outside the context of CScout's operation
don't make sense, but there are specialized instances where you might
want to post-process the output with a tool, and then display
the graph in a way that will provide you links to CScout.
Graph options
A semicolon-separated list of options that will be passed to dot
as graph attributes.
Graph attributes accepted by dot include
size, page, ration, margin, nodesep, ranksep, ordering, rankdir,
pagedir, rank, rotate, center, nslimit, mclimit, layers, color,
href, URL, and stylesheet.
Node options
A comma-separated list of options that will be passed to dot
as node attributes.
Node attributes accepted by dot include
height, shape, fontsize, fontname, color, fillcolor, fontcolor, style, layer,
regular, peripheries, sides, orientation, distortion, skew, href, URL,
target, and tooltip.
Note that node options are ignored, if the option to draw empty nodes is
set.
Edge options
A comma-separated list of options that will be passed to dot
as edge attributes.
Edge attributes accepted by dot include
minlen, weight, label, fontsize, fontname, fontcolor, style, color,
dir, tailclip, headclip, href, URL, target, tooltop, arrowhead,
arrowtail, arrowsize, headlabel, taillabel,
headref, headURL, headtarget, headtooltip,
tailref, tailURL, tailtarget, tailtooltip,
labeldistance, decorate, samehead, sametail, constraint, and layer.
The graph, node, and edge options can be used to fine tune the graph's
look.
See the
GraphViz documentation (http://www.graphviz.org/doc/info/attrs.html)
for more details.
For instance, the following diagram
was created using
| Graph options | bgcolor=lightblue |
| Node options | color=yellow,fontname="Helvetica",fillcolor=yellow,style=filled |
| Edge options | arrowtail=odiamond |
Saved Files
When Saving Modified Files Replace
When saving files where an identifier has been modified
it is often useful to use a different directory than the
one where the original version of the source code resides.
This allows you to
- continue operating CScout, even after the changes have been saved, and
- easilly back out changes your are not satisfied with.
To use this option, specify a regular expression that will match
a path component of the original source code files (often just a fixed
string), and a corresponding substitution string.
As an example, if your project files are of the type
/home/jack/src/foo/filename.c, you could
specify that /foo/ should be changed
into /../foo.new/.
Note than when this option is specified the existing and new locations
of the file must reside on the same drive and partition (under Windows)
or file system (under Unix).
Editing
The "External editor invocation command" allows the specification of the
editor that wil be used for hand-editing files.
This string can contain two %s placeholders.
The first is substituted by a regular expression that is associated
with the identifier for which the file is edited,
while the second is substituted with the corresponding file name.
The default string under Unix is
xterm -c "$VISUAL +/'%s' '%s'"
and under Windows
echo Ignoring search for "%s" & start notepad "%s"
Under Windows a more sensible default could be something like
start C:\Progra~1\Vim\vim70\gvim.exe +/"%s" "%s"
which fires off the VIM editor in a new window.
Option Files
The link on the right of global options allows you to
save the CScout global options into a file.
A directory .cscout will be created in the
current directory (if it does not already exist),
and a file named options will be written in it,
listing the options you specified.
When CScout starts-up it will attempt to load the options
file by searching in
$CSCOUT_HOME,
$HOME/.cscout, or
.cscout in the current directory.
The options file is text based and contains key-value pairs.
The order of the entries is not significant.
This is an example of an options file.
show_true: 1
show_projects: 1
show_identical_files: 1
show_line_number: 0
tab_width: 8
rename_override_ro: 1
refactor_fun_arg_override_ro: 1
file_icase: 0
entries_per_page: 20
fname_in_context: 1
sort_rev: 0
cgraph_type: s
cgraph_show: n
fgraph_show: n
cgraph_depth: 5
fgraph_depth: 5
cgraph_dot_url: 0
sfile_re_string: sfile_repl_string:
sfile_repl_string: entries_per_page:
start_editor_cmd: start C:\Progra~1\Vim\vim71\gvim.exe +/"%s" "%s"
Operations
The operations CScout provides group together functions
that globally affect its operation.
The following sections describe all operations appart from the global
options.
Identifier Replacements
This operation allows you to review the identifier replacements
you have specified in identifier pages,
and modify or selectively deactivate some of them.
This page, together with the "save and continue" operation and
the file path substitution option provide
you a way to test and revoke source code changes, while operating CScout.
The following is an example of the identifier replacements page.
You see all identifiers for which replacements have been specified.
All specified replacements are originally active.
If a particular replacement appears to be causing problems
you can deactivate it from this page.
In addition, you can change the replaced name of any of the
replaced identifiers.
Finally, clicking on an identifier name will lead you to the
corresponding identifier page.
Select Active Project
When using a workspace with multiple projects, you can restrict the
results of all identifier and file queries (read-made and those
you explicitly specify) to refer to a particular project or to all projects.
The metric results displayed are not affected.
When a project is delected, all pages end with a remark indicating the fact.
The following shows our example's project selection page.
Select Active Project
Project cp is currently selected
Main page
CScout 1.6 - 2003/06/04 15:14:51
|
Save Changes and Continue
Through this option you can save changes you have made to the program's
identifiers, and continue CScout's operation.
CScout bases its source code display facilities on the source code it
has analyzed.
Therefore, this operation can only be executed if a file substitution
regular expression has been specified as an option.
Exit - Saving Changes
Once you have changed the name of some identifiers by substituting it
with another name,
you should exit CScout through this option to commit the changes
you made to the respective file source code.
Exit - Ignore Changes
You can also exit CScout without committing any changes.
As this option will trigger millions of object desctructors in large
workspaces, it may be faster to just terminate CScout
from its command-line instance by pressing ^C.
Hand-Editing
Some file and identifier listings provide an option to edit the file by
hand.
Such an operation is useful when CScout has identified a function as unused, and
one therefore wishes to remove the complete function body.
The edit link invokes an external editor,
where possible with an argument that will move the edit point near the point
of the corresponding identifier.
The argument is specified as a regular expression.
This has the advantage that the location will work
even when the file length changes,
but the disadvantage is imprecise and can also result in spurious matches.
The automatic global identifier replacement and the hand-editing of
files are mutualy exclusive operations.
Once either of the two is performed the other ceases to be available.
This is done to protect the integrity of the underlying source code.
Furthermore, all CScout's operations, such as queries and source code listings,
are always performed on a snapshot of the source code taken just before a
file is edited by hand.
Interfacing with Version Management Systems
When the files CScout will modify are under revision control
you may want to check them out for editing before doing the identifier
substitutions, and then check them in again.
CScout provides hooks for this operation.
Before a file is modified CScout will try to
execute the command cscout_checkout;
after the file is modified CScout will try to execute the
command cscout_checkin.
Both commands will receive as their argument the full path name of the
respective file.
If commands with such names are in your path, they will be executed
performing whatever action you require.
As an example, for a system managed with
Perforce (https://www.perforce.com/)
the following commands could be used:
cscout_checkout
#!/bin/sh
p4 edit $1
cscout_checkin
#!/bin/sh
p4 submit -d 'CScout identifier name refactoring' $1
Language Extensions
CScout implements the
C language as defined in ANSI X3.159-1989.
In addition, it supports the following extensions:
- Preprocessor directives can appear within a call to a function-like macro (gcc)
- Initializers and compound literals can be empty (gcc)
- The
alignof operator can be used on types (gcc)
- A declaration expression as the first element of a
for statement (C99)
- The
restrict qualifier and the inline specifier (C99)
- The
_Bool type (C99)
- The
_Thread_local storage class specifier (C11)
- The
_Generic generic selection expression (C11)
- Support
static and other qualifiers in array type declarations (C99)
- Initialization designators (C99)
- Array initialization designators can include ranges (gcc)
- ANSI-style function definitions can be nested (gcc) (gcc also allows
nested K&R-style function definitions)
- The equals sign following an initializer designator is optional (gcc)
- Array and structure initialization (gcc)
- Compound literals (C99)
- Declarations can be intermixed with statements (C99).
- Recognise
__atribute__(__unused__) for determining which
identifiers should not be reported as unused (gcc).
-
// line comments (common extension)
-
__asm__ blocks (gcc)
-
enum lists ending with a comma (common extension)
- Anonymous
struct/union members (gcc, Microsoft C)
- Allow
case expression ranges (gcc).
- An enumeration list can be empty (Microsoft C)
- Allow braces around scalar initializers (common extension).
- Indirect
goto targets and the label address-of operator (gcc).
-
__typeof keyword (gcc)
- The ‘##’ token paste operator deletes the comma when placed between a comma and an empty variable argument (gcc)
-
__VA_OPT__ function macro (C23)
- A compound statement in brackets can be an expression (gcc)
- Macros expanding from
/##/ into
// are then treated as a line comment (Microsoft C)
- Exception handling using the
__try __except __finally __leave keywords (Microsoft C)
-
#include_next preprocessor directive (gcc)
-
#warning preprocessor directive (gcc)
- Variable number of arguments preprocessor macros
(support for both the gcc and the C99 syntax)
- Allow empty member declarations in aggregates (gcc)
-
long long type (common extension)
- A semicolon can appear as a declatation (common extension)
- An aggregate declaration body can be empty (gcc)
- Aggregate member initialization using the member: value syntax (gcc)
- Statement labels do not require a statement following them (gcc)
- #ident preprocessor directive (gcc)
- Allow assignment to case expressions (common extension)
- Accept an empty translation unit (common extension).
- Support locally declared labels (
__label__) (gcc).
- The second argument of a conditional expression can be omitted (gcc).
- Dereferencing a function yields a function (common extension).
- The
__simd type qualifier can be used to define
basic types that are also indexable, similarly to the gcc
extension __attribute__((__vector_size__(…))).
Many other compiler-specific extensions are handled by suitable
macro definitions in the CScout initialization file.
Processing Yacc Files
Many C programs include parsing code in the form of yacc source files.
CScout can directly process those files, allowing you
to analyze and modify the identifiers used in those files.
CScout determines whether a file is yacc source or
plain C, by examining the file's suffix:
file names ending in a lowercase 'y' are considered
to contain yacc source and processed accordingly.
CScout processes yacc files as follows:
- All terminal and non-terminal names are considered to be
defined as file-scoped identifiers in a special yacc-only
namespace.
- All terminal symbols are also marked as an undefined macro.
Thus, processing the yacc-generated file
y.tab.h
immediately after the grammar (i.e. in the same scope) will
unify the terminal symbols with the corresponding macro definitions
throughout the program.
- Members of the
%union construct are defined as
members of the YYSTYPE union typedef.
These are then considered to be accessed in all
%type and the precedence specification constructs,
as well as the
explicit type specification through the $<tag># construct.
- No yacc-specific macros (
yyerrok,
YYABORT,
YYACCEPT, etc)
are defined.
Feel free to define anything required to silence CScout
as a macro in the workspace definition file.
CScout is designed to process well-formed modern-style yacc
files.
All rules must be terminated with a semicolon
(apparently this is optional in the original yacc version).
The accepted grammar appears below.
body:
defs '%%' rules tail
;
tail:
/* Empty */
| '%%' c_code
;
defs:
/* Empty */
| defs def
;
def:
'%start' IDENTIFIER
| '%union' '{' member_declaration_list '}'
| '%{' c_code '%}'
| rword name_list_declaration
;
rword:
'%token'
| '%left'
| '%right'
| '%nonassoc'
| '%type'
;
tag:
/* Empty: union tag is optional */
| '<' IDENTIFIER '>'
;
name_list_declaration:
tag name_number
| name_list_declaration opt_comma name_number
;
opt_comma:
/* Empty */
| ','
;
name_number:
name
| name INT_CONST
;
name:
IDENTIFIER
| CHAR_LITERAL
;
/* rules section */
rules:
rule
| rules rule
;
rule:
IDENTIFIER ':' rule_body_list ';'
;
rule_body_list:
rule_body
| rule_body_list '|' rule_body
;
rule_body:
id_action_list prec
;
id_action_list:
/* Empty */
| id_action_list name
| id_action_list '{' c_code '}'
;
prec:
/* Empty */
| '%prec' name
| '%prec' name '{' c_code '}'
;
variable:
'$$'
| '$' INT_CONST
| '$-' INT_CONST
{ $$ = basic(b_int); }
| '$<' IDENTIFIER '>' variable_suffix
{ $$ = $3; }
;
variable_suffix:
'$'
| INT_CONST
| '-' INT_CONST
;
Regular Expression Syntax
CScout allows you to specify regular expressions for specifying
identifier or file names you are looking for.
The following description of the regular expressions
CScout accepts
is adapted from the FreeBSD re_format(7) manual page.
Regular expressions (``REs''), as defined in IEEE Std 1003.2
(``POSIX.2''), come in two forms: modern REs (roughly those of egrep(1);
1003.2 calls these ``extended'' REs) and obsolete REs (roughly those of
ed(1); 1003.2 ``basic'' REs).
CScout has adopted the use of modern (extended) REs.
A (modern) RE is one= or more non-empty= branches, separated by `|'. It
matches anything that matches one of the branches.
A branch is one= or more pieces, concatenated. It matches a match for
the first, followed by a match for the second, etc.
A piece is an atom possibly followed by a single= `*', `+', `?', or
bound. An atom followed by `*' matches a sequence of 0 or more matches
of the atom. An atom followed by `+' matches a sequence of 1 or more
matches of the atom. An atom followed by `?' matches a sequence of 0 or
1 matches of the atom.
A bound is `{' followed by an unsigned decimal integer, possibly followed
by `,' possibly followed by another unsigned decimal integer, always fol-
lowed by `}'. The integers must lie between 0 and RE_DUP_MAX (255=)
inclusive, and if there are two of them, the first may not exceed the
second. An atom followed by a bound containing one integer i and no
comma matches a sequence of exactly i matches of the atom. An atom fol-
lowed by a bound containing one integer i and a comma matches a sequence
of i or more matches of the atom. An atom followed by a bound containing
two integers i and j matches a sequence of i through j (inclusive)
matches of the atom.
An atom is a regular expression enclosed in `()' (matching a match for
the regular expression), an empty set of `()' (matching the null
string)=, a bracket expression (see below), `.' (matching any single
character), `^' (matching the null string at the beginning of a line),
`$' (matching the null string at the end of a line), a `\' followed by
one of the characters `^.[$()|*+?{\' (matching that character taken as an
ordinary character), a `\' followed by any other character= (matching
that character taken as an ordinary character, as if the `\' had not been
present=), or a single character with no other significance (matching
that character). A `{' followed by a character other than a digit is an
ordinary character, not the beginning of a bound=. It is illegal to end
an RE with `\'.
A bracket expression is a list of characters enclosed in `[]'. It nor-
mally matches any single character from the list (but see below). If the
list begins with `^', it matches any single character (but see below) not
from the rest of the list. If two characters in the list are separated
by `-', this is shorthand for the full range of characters between those
two (inclusive) in the collating sequence, e.g. `[0-9]' in ASCII matches
any decimal digit. It is illegal= for two ranges to share an endpoint,
e.g. `a-c-e'. Ranges are very collating-sequence-dependent, and portable
programs should avoid relying on them.
To include a literal `]' in the list, make it the first character (fol-
lowing a possible `^'). To include a literal `-', make it the first or
last character, or the second endpoint of a range. To use a literal `-'
as the first endpoint of a range, enclose it in `[.' and `.]' to make it
a collating element (see below). With the exception of these and some
combinations using `[' (see next paragraphs), all other special charac-
ters, including `\', lose their special significance within a bracket
expression.
Within a bracket expression, a collating element (a character, a multi-
character sequence that collates as if it were a single character, or a
collating-sequence name for either) enclosed in `[.' and `.]' stands for
the sequence of characters of that collating element. The sequence is a
single element of the bracket expression's list. A bracket expression
containing a multi-character collating element can thus match more than
one character, e.g. if the collating sequence includes a `ch' collating
element, then the RE `[[.ch.]]*c' matches the first five characters of
`chchcc'.
Within a bracket expression, a collating element enclosed in `[=' and
`=]' is an equivalence class, standing for the sequences of characters of
all collating elements equivalent to that one, including itself. (If
there are no other equivalent collating elements, the treatment is as if
the enclosing delimiters were `[.' and `.]'.) For example, if `x' and
`y' are the members of an equivalence class, then `[[=x=]]', `[[=y=]]',
and `[xy]' are all synonymous. An equivalence class may not= be an end-
point of a range.
Within a bracket expression, the name of a character class enclosed in
`[:' and `:]' stands for the list of all characters belonging to that
class. Standard character class names are:
alnum digit punct
alpha graph space
blank lower upper
cntrl print xdigit
These stand for the character classes defined in ctype(3). A locale may
provide others. A character class may not be used as an endpoint of a
range.
There are two special cases= of bracket expressions: the bracket expres-
sions `[[:<:]]' and `[[:>:]]' match the null string at the beginning and
end of a word respectively. A word is defined as a sequence of word
characters which is neither preceded nor followed by word characters. A
word character is an alnum character (as defined by ctype(3)) or an
underscore. This is an extension, compatible with but not specified by
IEEE Std 1003.2 (``POSIX.2''), and should be used with caution in soft-
ware intended to be portable to other systems.
In the event that an RE could match more than one substring of a given
string, the RE matches the one starting earliest in the string. If the
RE could match more than one substring starting at that point, it matches
the longest. Subexpressions also match the longest possible substrings,
subject to the constraint that the whole match be as long as possible,
with subexpressions starting earlier in the RE taking priority over ones
starting later. Note that higher-level subexpressions thus take priority
over their lower-level component subexpressions.
Match lengths are measured in characters, not collating elements. A null
string is considered longer than no match at all. For example, `bb*'
matches the three middle characters of `abbbc',
`(wee|week)(knights|nights)' matches all ten characters of `weeknights',
when `(.*).*' is matched against `abc' the parenthesized subexpression
matches all three characters, and when `(a*)*' is matched against `bc'
both the whole RE and the parenthesized subexpression match the null
string.
If case-independent matching is specified, the effect is much as if all
case distinctions had vanished from the alphabet. When an alphabetic
that exists in multiple cases appears as an ordinary character outside a
bracket expression, it is effectively transformed into a bracket expres-
sion containing both cases, e.g. `x' becomes `[xX]'. When it appears
inside a bracket expression, all case counterparts of it are added to the
bracket expression, so that (e.g.) `[x]' becomes `[xX]' and `[^x]'
becomes `[^xX]'.
Access Control
By default CScout only allows the local host (127.0.0.1)
to connect to your server for casual browsing.
To allow other hosts to connect CScout features an access control list.
The list is specified in a file called acl which
should be located in
$CSCOUT_HOME,
$HOME/.cscout, or
.cscout in the current directory.
The list contains lines with IP numeric addresses prefixed by an
A (allow)
or
D (deny)
prefix and a space.
Matching is performed by comparing a substring of a machine's IP address
against the specified access rule.
Thus an entry such as
A 128.135.11.
can be used to allow access from a whole subnet.
Unfortunatelly allowing access from the IP address
192.168.1.1 will
also allow access
192.168.1.10, 192.168.1.100, and so on.
Allow and deny entries cannot be combined in a useful manner
since the rules followed are:
- If the address matches an allowed entry the machine will be allowed access.
- If no allowed entries have been specified,
the machine will be allowed access unless it has been denied access.
(i.e. you can not use a deny entry to exclude a machine from an
allowed group)
Thus you will either specify a restricted list of allowed hosts,
or allow access to the world, specifying a list of denied hosts.
Obfuscation Back-end
CScout can convert a workspace into an obfuscated version.
The obfuscated version of the workspace can be distributed instead
of the original C source, and can be compiled on different processor
architectures and operating systems,
hindering however the code's reverse engineering and modification.
Each source code file is obfuscated by
- Giving meaningless names to all identifiers: macros, arguments, ordinary identifiers, structure tags, structure members, and labels.
- Removing comments.
- Removing extraneous whitespace.
Before running CScout to obfuscate, make a complete backup copy of
your source code files, and store them in a secure place;
preferably off-line.
Once the source code files are obfuscated and overwritten, there is no
way to get back their original contents.
To obfuscate the workspace, first ensure that CScout can correctly
process the complete set of its source code files.
Use the "unprocessed lines" metric of each file to verify that no
parts of a file are left unprocessed;
unprocessed regions will not be obfuscated.
You can easily increase the coverage of CScout's processing by
including in the workspace multiple projects with different defined
directives.
Also ensure that all your project's files are considered writable, and no
files outside your project (for example system headers) are considered writable.
This will allow CScout to rename your identifier names, but
keep the names of library-defined identifiers (for example printf)
unchanged.
Finally, run CScout with the switch -o.
For each writable workspace file CScout will create a file ending
in .obf that will contain the obfuscated version of its
contents.
The files are not overwritten, providing you with another countermeasure
against accidentally destroying them.
To overwrite the original source with the obfuscated one,
use the following Unix command:
find . -name '*.obf' |
sed 's/\\/\//g;s/\(.*\)\.obf$/mv "\1.obf" "\1"/' |
sh
You can then compile the obfuscated version of your project,
to verify the obfuscation's results.
SQL Back-end
CScout can dump the relationships of
an entire workspace in the form of a SQL script.
This can then be uploaded into a relational database for further
querying and processing.
To generate the SQL script simply
run CScout with the switch -s dialect,
where the argument specifies the SQL dialect (for example,
mysql, or postgresql).
The SQL script will appear in CScout's standard output,
allowing you to directly pipe the results into the database's
client.
For example, say the database you would want to create for your project
was called myproj.
For SQLite you would write:
rm -f myproj.db
cscout -s sqlite myproj.cs | sqlite3 myproj.db
For MySQL you would write:
(
echo "create database myproj; use myproj ;"
cscout -s mysql myproj.cs
) | mysql
For PostgreSQL you would write:
createdb -U username myproj
cscout -s postgres myproj.cs | psql -U username myproj
For HSQLDB you would write:
cscout -s hsqldb myproj.cs |
java -classpath $HSQLDBHOME/lib/hsqldb/hsqldb.jar org.hsqldb.util.SqlTool --rcfile $HSQLDBHOME/lib/hsqldb/sqltool.rc mem -
The direct piping allows you to avoid the overhead of creating an
intermediate file, which can be very large.
Schema of the Generated Database
-- Details of interdependant identifiers appearing in the workspace
CREATE TABLE IDS(
EID BIGINT PRIMARY KEY, -- Unique identifier key
NAME CHARACTER VARYING, -- Identifier name
READONLY BOOLEAN, -- True if it appears in at least one read-only file
UNDEFMACRO BOOLEAN, -- True if it is apparantly an undefined macro
MACRO BOOLEAN, -- True if it a preprocessor macro
FUNMACRO BOOLEAN, -- True if it a preprocessor function-like macro
MACROARG BOOLEAN, -- True if it a preprocessor macro argument
CPPCONST BOOLEAN, -- True if used in a preprocessor constant
CPPSTRVAL BOOLEAN, -- True if macro value is used as a preprocessor string operand
DEFCCONSTVAL BOOLEAN, -- True if macro value defined as a C compile time constant
NOTDEFCCONSTVAL BOOLEAN, -- True if macro value defined as not a C compile time constant
EXPCCONSTVAL BOOLEAN, -- True if macro value expanded as a C compile time constant
NOTEXPCCONSTVAL BOOLEAN, -- True if macro value expanded as not a C compile time constant
ORDINARY BOOLEAN, -- True if it is an ordinary identifier (variable or function)
SUETAG BOOLEAN, -- True if it is a structure, union, or enumeration tag
SUMEMBER BOOLEAN, -- True if it is a structure or union member
LABEL BOOLEAN, -- True if it is a label
TYPEDEF BOOLEAN, -- True if it is a typedef
ENUM BOOLEAN, -- True if it is an enumeration member
YACC BOOLEAN, -- True if it is a yacc identifier
FUN BOOLEAN, -- True if it is a function name
CSCOPE BOOLEAN, -- True if its scope is a compilation unit
LSCOPE BOOLEAN, -- True if it has linkage scope
UNUSED BOOLEAN -- True if it is not used
);
-- File details
CREATE TABLE FILES(
FID INTEGER PRIMARY KEY, -- Unique file key
NAME CHARACTER VARYING, -- File name
RO BOOLEAN -- True if the file is read-only
);
-- File metrics
CREATE TABLE FILEMETRICS(
FID INTEGER, -- File key
PRECPP BOOLEAN, -- True for values before the cpp false for values after it
NCHAR INTEGER, -- Number of characters
NCCOMMENT INTEGER, -- Number of comment characters
NSPACE INTEGER, -- Number of space characters
NLCOMMENT INTEGER, -- Number of line comments
NBCOMMENT INTEGER, -- Number of block comments
NLINE INTEGER, -- Number of lines
MAXLINELEN INTEGER, -- Maximum number of characters in a line
MAXSTMTLEN INTEGER, -- Maximum number of tokens in a statement
MAXSTMTNEST INTEGER, -- Maximum level of statement nesting
MAXBRACENEST INTEGER, -- Maximum level of brace nesting
MAXBRACKNEST INTEGER, -- Maximum level of bracket nesting
BRACENEST INTEGER, -- Dangling brace nesting
BRACKNEST INTEGER, -- Dangling bracket nesting
NULINE INTEGER, -- Number of unprocessed lines
NPPDIRECTIVE INTEGER, -- Number of C preprocessor directives
NPPCOND INTEGER, -- Number of processed C preprocessor conditionals (ifdef, if, elif)
NPPFMACRO INTEGER, -- Number of defined C preprocessor function-like macros
NPPOMACRO INTEGER, -- Number of defined C preprocessor object-like macros
NTOKEN INTEGER, -- Number of tokens
NSTMT INTEGER, -- Number of statements or declarations
NOP INTEGER, -- Number of operators
NUOP INTEGER, -- Number of unique operators
NNCONST INTEGER, -- Number of numeric constants
NCLIT INTEGER, -- Number of character literals
NSTRING INTEGER, -- Number of character strings
NPPCONCATOP INTEGER, -- Number of token concatenation operators (##)
NPPSTRINGOP INTEGER, -- Number of token stringification operators (#)
NIF INTEGER, -- Number of if statements
NELSE INTEGER, -- Number of else clauses
NSWITCH INTEGER, -- Number of switch statements
NCASE INTEGER, -- Number of case labels
NDEFAULT INTEGER, -- Number of default labels
NBREAK INTEGER, -- Number of break statements
NFOR INTEGER, -- Number of for statements
NWHILE INTEGER, -- Number of while statements
NDO INTEGER, -- Number of do statements
NCONTINUE INTEGER, -- Number of continue statements
NGOTO INTEGER, -- Number of goto statements
NRETURN INTEGER, -- Number of return statements
NASM INTEGER, -- Number of assembly statements
NTYPEOF INTEGER, -- Number of typeof operators
NPID INTEGER, -- Number of project-scope identifiers
NFID INTEGER, -- Number of file-scope (static) identifiers
NMID INTEGER, -- Number of macro identifiers
NID INTEGER, -- Total number of object and object-like identifiers
NUPID INTEGER, -- Number of unique project-scope identifiers
NUFID INTEGER, -- Number of unique file-scope (static) identifiers
NUMID INTEGER, -- Number of unique macro identifiers
NUID INTEGER, -- Number of unique object and object-like identifiers
NLABEL INTEGER, -- Number of goto labels
NMACROEXPANDTOKEN INTEGER, -- Tokens added by macro expansion
NCOPIES INTEGER, -- Number of copies of the file
NINCFILE INTEGER, -- Number of directly included files
NPFUNCTION INTEGER, -- Number of defined project-scope functions
NFFUNCTION INTEGER, -- Number of defined file-scope (static) functions
NPVAR INTEGER, -- Number of defined project-scope variables
NFVAR INTEGER, -- Number of defined file-scope (static) variables
NAGGREGATE INTEGER, -- Number of complete aggregate (struct/union) declarations
NAMEMBER INTEGER, -- Number of declared aggregate (struct/union) members
NENUM INTEGER, -- Number of complete enumeration declarations
NEMEMBER INTEGER, -- Number of declared enumeration elements
PRIMARY KEY(FID, PRECPP),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Instances of identifier tokens within the source code
CREATE TABLE TOKENS(
FID INTEGER, -- File key
FOFFSET INTEGER, -- Offset within the file
EID BIGINT, -- Identifier key
PRIMARY KEY(FID, FOFFSET),
FOREIGN KEY(FID) REFERENCES FILES(FID),
FOREIGN KEY(EID) REFERENCES IDS(EID)
);
-- Comments in the code
CREATE TABLE COMMENTS(
FID INTEGER, -- File key
FOFFSET INTEGER, -- Offset within the file
COMMENT CHARACTER VARYING, -- The comment, including its delimiters
PRIMARY KEY(FID, FOFFSET),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Strings in the code
CREATE TABLE STRINGS(
FID INTEGER, -- File key
FOFFSET INTEGER, -- Offset within the file
STRING CHARACTER VARYING, -- The string, including its delimiters
PRIMARY KEY(FID, FOFFSET),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Remaining, non-identifier source code
CREATE TABLE REST(
FID INTEGER, -- File key
FOFFSET INTEGER, -- Offset within the file
CODE CHARACTER VARYING, -- The actual code
PRIMARY KEY(FID, FOFFSET),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Line number offsets within each file
CREATE TABLE LINEPOS(
FID INTEGER, -- File key
FOFFSET INTEGER, -- Offset within the file
LNUM INTEGER, -- Line number (starts at 1)
PRIMARY KEY(FID, FOFFSET),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Project details
CREATE TABLE PROJECTS(
PID INTEGER PRIMARY KEY, -- Unique project key
NAME CHARACTER VARYING -- Project name
);
-- Identifiers appearing in projects
CREATE TABLE IDPROJ(
EID BIGINT, -- Identifier key
PID INTEGER, -- Project key
PRIMARY KEY(EID, PID),
FOREIGN KEY(EID) REFERENCES IDS(EID),
FOREIGN KEY(PID) REFERENCES PROJECTS(PID)
);
-- Files used in projects
CREATE TABLE FILEPROJ(
FID INTEGER, -- File key
PID INTEGER, -- Project key
PRIMARY KEY(PID, FID),
FOREIGN KEY(FID) REFERENCES FILES(FID),
FOREIGN KEY(PID) REFERENCES PROJECTS(PID)
);
-- Lines processed in projects
CREATE TABLE LINEPROJ(
FID INTEGER, -- File key
PID INTEGER, -- Project key
LNUM INTEGER, -- Line number (starts at 1)
PRIMARY KEY(PID, FID, LNUM),
FOREIGN KEY(FID) REFERENCES FILES(FID),
FOREIGN KEY(PID) REFERENCES PROJECTS(PID)
);
-- Foreign keys for the following four tables are not specified, because it is
-- difficult to satisfy integrity constraints: files (esp. their metrics,
-- esp. ncopies) can't be written until the end of processing, while
-- to conserve space, these tables are written after each file is processed.
-- Alternatively, inserts to these tables could be wrapped into
-- SET REFERENTIAL_INTEGRITY { TRUE | FALSE } calls.
-- Included files defining required elements for a given compilation unit and project
CREATE TABLE DEFINERS(
PID INTEGER, -- Project key
CUID INTEGER, -- Compilation unit key
BASEFILEID INTEGER, -- File (often .c) requiring (using) a definition
DEFINERID INTEGER -- File (often .h) providing a definition
-- FOREIGN KEY(PID) REFERENCES PROJECTS(PID),
-- FOREIGN KEY(CUID) REFERENCES FILES(FID),
-- FOREIGN KEY(BASEFILEID) REFERENCES FILES(FID),
-- FOREIGN KEY(DEFINERID) REFERENCES FILES(FID)
);
-- Included files including files for a given compilation unit and project
CREATE TABLE INCLUDERS(
PID INTEGER, -- Project key
CUID INTEGER, -- Compilation unit key
BASEFILEID INTEGER, -- File included in the compilation
INCLUDERID INTEGER -- Files that include it
-- FOREIGN KEY(PID) REFERENCES PROJECTS(PID),
-- FOREIGN KEY(CUID) REFERENCES FILES(FID),
-- FOREIGN KEY(BASEFILEID) REFERENCES FILES(FID),
-- FOREIGN KEY(INCLUDERID) REFERENCES FILES(FID)
);
-- Included files providing code or data for a given compilation unit and project
CREATE TABLE PROVIDERS(
PID INTEGER, -- Project key
CUID INTEGER, -- Compilation unit key
PROVIDERID INTEGER -- Included file
-- FOREIGN KEY(PID) REFERENCES PROJECTS(PID),
-- FOREIGN KEY(CUID) REFERENCES FILES(FID),
-- FOREIGN KEY(PROVIDERID) REFERENCES FILES(FID)
);
-- Tokens requiring file inclusion for a given compilation unit and project
CREATE TABLE INCTRIGGERS(
PID INTEGER, -- Project key
CUID INTEGER, -- Compilation unit key
BASEFILEID INTEGER, -- File requiring a definition
DEFINERID INTEGER, -- File providing a definition
FOFFSET INTEGER, -- Definition's offset within the providing file
LEN INTEGER -- Token's length
-- FOREIGN KEY(PID) REFERENCES PROJECTS(PID),
-- FOREIGN KEY(CUID) REFERENCES FILES(FID),
-- FOREIGN KEY(BASEFILEID) REFERENCES FILES(FID),
-- FOREIGN KEY(DEFINERID) REFERENCES FILES(FID)
);
-- C functions and function-like macros
CREATE TABLE FUNCTIONS(
ID BIGINT PRIMARY KEY, -- Unique function identifier
NAME CHARACTER VARYING, -- Function name (denormalized; see the FUNCTIONID table)
ISMACRO BOOLEAN, -- True if a function-like macro (otherwise a C function)
DEFINED BOOLEAN, -- True if the function is defined within the workspace
DECLARED BOOLEAN, -- True if the function is declared within the workspace
FILESCOPED BOOLEAN, -- True if the function's scope is a single compilation unit (static or macro)
FID INTEGER, -- File key of the function's definition, declaration, or use
FOFFSET INTEGER, -- Offset of definition, declaration, or use within the file
FANIN INTEGER, -- Fan-in (number of callers)
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Details of defined functions and macros
CREATE TABLE FUNCTIONDEFS(
FUNCTIONID BIGINT PRIMARY KEY, -- Function identifier key
FIDBEGIN INTEGER, -- File key of the function's definition begin
FOFFSETBEGIN INTEGER, -- Offset of definition begin within the file
FIDEND INTEGER, -- File key of the function's definition end
FOFFSETEND INTEGER, -- Offset of definition end within the file
FOREIGN KEY(FUNCTIONID) REFERENCES FUNCTIONS(ID)
);
-- Metrics of defined functions and macros
CREATE TABLE FUNCTIONMETRICS(
FUNCTIONID BIGINT, -- Function identifier key
PRECPP BOOLEAN, -- True for values before the cpp false for values after it
NCHAR INTEGER, -- Number of characters
NCCOMMENT INTEGER, -- Number of comment characters
NSPACE INTEGER, -- Number of space characters
NLCOMMENT INTEGER, -- Number of line comments
NBCOMMENT INTEGER, -- Number of block comments
NLINE INTEGER, -- Number of lines
MAXLINELEN INTEGER, -- Maximum number of characters in a line
MAXSTMTLEN INTEGER, -- Maximum number of tokens in a statement
MAXSTMTNEST INTEGER, -- Maximum level of statement nesting
MAXBRACENEST INTEGER, -- Maximum level of brace nesting
MAXBRACKNEST INTEGER, -- Maximum level of bracket nesting
BRACENEST INTEGER, -- Dangling brace nesting
BRACKNEST INTEGER, -- Dangling bracket nesting
NULINE INTEGER, -- Number of unprocessed lines
NPPDIRECTIVE INTEGER, -- Number of C preprocessor directives
NPPCOND INTEGER, -- Number of processed C preprocessor conditionals (ifdef, if, elif)
NPPFMACRO INTEGER, -- Number of defined C preprocessor function-like macros
NPPOMACRO INTEGER, -- Number of defined C preprocessor object-like macros
NTOKEN INTEGER, -- Number of tokens
NSTMT INTEGER, -- Number of statements or declarations
NOP INTEGER, -- Number of operators
NUOP INTEGER, -- Number of unique operators
NNCONST INTEGER, -- Number of numeric constants
NCLIT INTEGER, -- Number of character literals
NSTRING INTEGER, -- Number of character strings
NPPCONCATOP INTEGER, -- Number of token concatenation operators (##)
NPPSTRINGOP INTEGER, -- Number of token stringification operators (#)
NIF INTEGER, -- Number of if statements
NELSE INTEGER, -- Number of else clauses
NSWITCH INTEGER, -- Number of switch statements
NCASE INTEGER, -- Number of case labels
NDEFAULT INTEGER, -- Number of default labels
NBREAK INTEGER, -- Number of break statements
NFOR INTEGER, -- Number of for statements
NWHILE INTEGER, -- Number of while statements
NDO INTEGER, -- Number of do statements
NCONTINUE INTEGER, -- Number of continue statements
NGOTO INTEGER, -- Number of goto statements
NRETURN INTEGER, -- Number of return statements
NASM INTEGER, -- Number of assembly statements
NTYPEOF INTEGER, -- Number of typeof operators
NPID INTEGER, -- Number of project-scope identifiers
NFID INTEGER, -- Number of file-scope (static) identifiers
NMID INTEGER, -- Number of macro identifiers
NID INTEGER, -- Total number of object and object-like identifiers
NUPID INTEGER, -- Number of unique project-scope identifiers
NUFID INTEGER, -- Number of unique file-scope (static) identifiers
NUMID INTEGER, -- Number of unique macro identifiers
NUID INTEGER, -- Number of unique object and object-like identifiers
NLABEL INTEGER, -- Number of goto labels
NMACROEXPANDTOKEN INTEGER, -- Tokens added by macro expansion
NGNSOC INTEGER, -- Number of global namespace occupants at function's top
NMPARAM INTEGER, -- Number of parameters (for macros)
NFPARAM INTEGER, -- Number of parameters (for functions)
NEPARAM INTEGER, -- Number of passed non-expression macro parameters
FANIN INTEGER, -- Fan-in (number of calling functions)
FANOUT INTEGER, -- Fan-out (number of called functions)
CCYCL1 INTEGER, -- Cyclomatic complexity (control statements)
CCYCL2 INTEGER, -- Extended cyclomatic complexity (includes branching operators)
CCYCL3 INTEGER, -- Maximum cyclomatic complexity (includes branching operators and all switch branches)
CSTRUC REAL, -- Structure complexity (Henry and Kafura)
CHAL REAL, -- Halstead volume
IFLOW REAL, -- Information flow metric (Henry and Selig)
PRIMARY KEY(FUNCTIONID, PRECPP),
FOREIGN KEY(FUNCTIONID) REFERENCES FUNCTIONS(ID)
);
-- Identifiers comprising a function's name
CREATE TABLE FUNCTIONID(
FUNCTIONID BIGINT, -- Function identifier key
ORDINAL INTEGER, -- Position of the identifier within the function name (0-based)
FID INTEGER, -- File key of the identifier
FOFFSET INTEGER, -- Offset of the identifier within the file
LEN INTEGER, -- Length of the identifier part
PRIMARY KEY(FUNCTIONID, ORDINAL),
FOREIGN KEY(FUNCTIONID) REFERENCES FUNCTIONS(ID),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
-- Function calls
CREATE TABLE FCALLS(
SOURCEID BIGINT, -- Calling function identifier key
DESTID BIGINT, -- Called function identifier key
FOREIGN KEY(SOURCEID) REFERENCES FUNCTIONS(ID),
FOREIGN KEY(DESTID) REFERENCES FUNCTIONS(ID)
);
-- Files occuring in more than one copy
CREATE TABLE FILECOPIES(
GROUPID INTEGER, -- File group identifier
FID INTEGER, -- Key of file belonging to a group of identical files
PRIMARY KEY(GROUPID, FID),
FOREIGN KEY(FID) REFERENCES FILES(FID)
);
Examples of SQL Queries
Once data have been uploaded onto a SQL database they can be queried in a
number of different ways.
Here are some example queries.
All queries have been tested with SQLite, but
note that some queries may not run on a particular relational database
engine.
Index creation to speed up processing
CREATE INDEX IF NOT EXISTS idx_tokens_eid ON tokens(eid);
CREATE INDEX IF NOT EXISTS idx_tokens_fid_idx on tokens(fid);
CREATE INDEX IF NOT EXISTS idx_fcalls_destid ON fcalls(destid);
CREATE INDEX IF NOT EXISTS idx_fcalls_sourceid ON fcalls(sourceid);
CREATE INDEX IF NOT EXISTS idx_functiondefs_functionid ON functiondefs(functionid);
CREATE INDEX IF NOT EXISTS idx_ids_name ON ids(name);
CREATE INDEX IF NOT EXISTS idx_ids_name ON ids(eid);
CREATE INDEX IF NOT EXISTS idx_includers_cuid ON includers(cuid);
CREATE INDEX IF NOT EXISTS idx_includers_includerid ON includers(includerid);
Identifiers of a given type
SELECT name FROM ids WHERE ids.typedef ORDER BY name;
Number of different files that use a given identifier
SELECT name, Count(*) AS cf FROM (
SELECT fid, tokens.eid, Count(*) AS c
FROM tokens
GROUP BY eid, fid
) AS cl
INNER JOIN ids ON cl.eid = ids.eid
GROUP BY ids.eid, ids.name
HAVING cf > 1
ORDER BY cf DESC, name;
Identifiers occuring ten or more times in a single file
SELECT ids.name AS iname, files.name AS fname, Count(*) AS c
FROM tokens
INNER JOIN ids ON ids.eid = tokens.eid
INNER JOIN files ON tokens.fid = files.fid
GROUP BY ids.eid, tokens.fid
HAVING c >= 10
ORDER BY c DESC, ids.name, files.name;
Identifiers occuring ten or more times in the workspace
SELECT name, Count(*) AS c FROM tokens
INNER JOIN ids ON ids.eid = tokens.eid
GROUP BY ids.eid
HAVING c >= 10
ORDER BY c DESC, name;
Projects each identifier named main belongs to
SELECT ids.name, projects.name
FROM ids
INNER JOIN idproj ON ids.eid = idproj.eid
INNER JOIN projects ON idproj.pid = projects.pid
WHERE ids.name = 'main'
ORDER BY ids.name;
Included files required by other files for each compilation unit and project
SELECT
projects.name AS projname,
cufiles.name AS cuname,
basefiles.name AS basename,
definefiles.name AS defname
FROM definers
INNER join projects ON definers.pid = projects.pid
INNER JOIN files AS cufiles ON definers.cuid=cufiles.fid
INNER JOIN files AS basefiles ON definers.basefileid=basefiles.fid
INNER JOIN files AS definefiles ON definers.definerid = definefiles.fid;
Identifiers common between files participating in a define/use relationship
SELECT
min(ids.name) as identifier,
min(filesb.name) as defined,
min(filesa.name) as used
FROM definers
INNER JOIN tokens AS tokensa ON definers.basefileid = tokensa.fid
INNER JOIN tokens AS tokensb ON definers.definerid = tokensb.fid
INNER JOIN ids ON ids.eid = tokensa.eid
INNER JOIN files as filesa ON tokensa.fid = filesa.fid
INNER JOIN files as filesb ON tokensb.fid = filesb.fid
WHERE tokensa.eid = tokensb.eid
GROUP BY tokensa.eid, definerid, basefileid
ORDER BY defined, identifier, used;
Function and macro call graph
SELECT source.name AS CallingFunction, dest.name AS CalledFunction
FROM fcalls
INNER JOIN functions AS source ON fcalls.sourceid = source.id
INNER JOIN functions AS dest ON fcalls.destid = dest.id
ORDER BY CallingFunction, CalledFunction;
Number of C preprocessor directives in the project's source code files excluding the CScout configuration file
SELECT Sum(nppdirective) FROM filemetrics
WHERE precpp
AND fid != (SELECT fid FROM files WHERE name LIKE '%.cs');
Macros that cannot be easily converted into C
CREATE INDEX IF NOT EXISTS idx_tokens_eid ON tokens(eid);
CREATE INDEX IF NOT EXISTS idx_functiondefs_functionid ON functiondefs(functionid);
CREATE INDEX IF NOT EXISTS idx_fcalls_destid ON fcalls(destid);
CREATE INDEX IF NOT EXISTS idx_fcalls_sourceid ON fcalls(sourceid);
-- Macros that use local variables
WITH scoped_confused_macros AS (
SELECT DISTINCT macrodefs.functionid
FROM functiondefs AS macrodefs
INNER JOIN functions ON functions.id = macrodefs.functionid
AND functions.ismacro
-- Obtain macro's tokens
INNER JOIN tokens AS macrotokens ON macrotokens.fid = macrodefs.fidbegin
AND macrotokens.fid = macrodefs.fidend
AND macrotokens.foffset >= macrodefs.foffsetbegin
AND macrotokens.foffset < macrodefs.foffsetend
-- See those that are local objects or labels
INNER JOIN ids ON ids.eid = macrotokens.eid
AND ids.ordinary
AND NOT (ids.macro OR ids.macroarg OR ids.suetag OR ids.sumember OR ids.typedef OR ids.enum)
AND NOT ids.cscope
AND NOT ids.lscope
INNER JOIN files ON macrodefs.fidbegin = files.fid
-- For macros that get called by C code
WHERE EXISTS (
SELECT 1
FROM fcalls
WHERE fcalls.destid = macrodefs.functionid
AND EXISTS (
SELECT 1
FROM functions AS cfunctions
WHERE
fcalls.sourceid = cfunctions.id
AND cfunctions.defined
AND NOT cfunctions.ismacro
)
-- And tokens that also appear in the C function body
AND EXISTS (
SELECT 1
FROM functiondefs AS cdefs
INNER JOIN tokens AS ctokens ON ctokens.eid = macrotokens.eid
WHERE
fcalls.sourceid = cdefs.functionid
AND (cdefs.fidbegin != macrodefs.fidbegin
OR cdefs.foffsetbegin > macrodefs.foffsetbegin)
AND ctokens.fid = cdefs.fidend
AND ctokens.foffset >= cdefs.foffsetbegin
AND ctokens.foffset < cdefs.foffsetend
)
)
)
SELECT Count(*) FROM
functions
INNER JOIN filemetrics ON filemetrics.fid = functions.fid AND filemetrics.precpp
INNER JOIN functionmetrics AS fnmet ON functions.id = fnmet.functionid AND fnmet.precpp
WHERE ismacro
AND filemetrics.fid != (SELECT fid FROM files WHERE name LIKE '%.cs')
AND (
fnmet.fanin = 0
OR fnmet.bracenest != 0
OR fnmet.bracknest != 0
OR fnmet.nppstringop > 0
OR fnmet.nppconcatop > 0
OR fnmet.neparam > 0
-- Control flow problems
OR (
-- Callable macro, rather than macro defining a function
fnmet.fanin > 0
AND ((fnmet.ngoto > 0 AND fnmet.nlabel = 0)
OR (fnmet.nreturn > 1 AND fnmet.ndo = 1))
)
OR EXISTS (
SELECT 1
FROM scoped_confused_macros AS scm
WHERE scm.functionid = fnmet.functionid
)
)
;
Source Code Reconstitution
The data stored in the database allow the exact reconstitution
of the original source code.
All that is required is to run an appropriate query and filter
its results to recreate the original line breaks from irs output.
Elements modified in the database, such as identifier names or
comment contents, will be correctly mirrored in the generated output.
The following is the required SQL query for the SQLite database
to reconstitute the contents of the file with
file identifier (fid) 4.
.print "Starting dump"
SELECT s FROM (
SELECT name AS s, foffset
FROM ids
INNER JOIN tokens ON ids.eid = tokens.eid
WHERE fid = 4
UNION SELECT code AS s, foffset FROM rest WHERE fid = 4
UNION SELECT comment AS s, foffset FROM comments WHERE fid = 4
UNION SELECT string AS s, foffset FROM strings WHERE fid = 4
)
ORDER BY foffset;
The query's output needs to be pipped to the following commands
to adjust it as needed.
# Remove header and footer lines
sed -e '1,/^Starting dump/d;/^[0-9][0-9]* rows/d' |
# Remove line breaks added by the database engine
tr -d '\n\r' |
# Add line breaks appearing in the database output as Unicode escapes
perl -pe 's/\\u0000d\\u0000a/\n/g;s/\\u0000a/\n/g' >test/chunk/$NAME
Details of the Collected Metrics
The following sections provide details for some of
the collected function and file metrics.
Although the metrics collected by CScout are considerably
more accurate than those collected by programs that either
do not parse the source code or parse the preprocessed code,
they still employ approximations.
Metrics Common to Files and Functions
- Number of C preprocessor directives
- See note 1.
- Number of processed C preprocessor conditionals (ifdef, if, elif)
- See note 1.
- Number of defined C preprocessor function-like macros
- See note 1.
- Number of defined C preprocessor object-like macros
- See note 1.
- Number of preprocessed tokens
- Although during preprocessing whitespace is considered a valid token, this metric does not take whitespace tokens into account.
This makes it easy to compare the number of preprocessed tokens with the number
of compiled tokens.
The two metrics are equal if no macro expansion takes place.
- Number of compiled tokens
- See note 1.
File-Specific Metrics
- Number of statements
- This
metric measures number of statements parsed while processing the file,
including statements generated by macro expansion.
See note 1.
- Number of defined project-scope functions
- See note 1.
- Number of defined file-scope (static) functions
- See note 1.
- Number of defined project-scope variables
- See note 1.
- Number of defined file-scope (static) variables
- See note 1.
- Number of complete aggregate (struct/union) declarations
-
Also includes complete declarations without a tag.
See note 1.
- Number of declared aggregate (struct/union) members
- See note 1.
- Number of complete enumeration declarations
- See note 1.
- Number of declared enumeration elements
- See note 1.
- Number of directly included files
-
This counts the number of header files that were directly included while processing the project's source files. If each file is processed exactly once, the metric is roughly similar to the number of #include directives in the project's files.
See also note 1.
Function-Specific Metrics
- Number of statements or declarations
- Nested statements are counted recursively.
Thus
while (a)
if (b)
c();
counts as three statements.
- Number of operators
- See note 2.
- Number of unique operators
-
See note 2.
- Number of if statements
- See note 3.
- Number of else clauses
- See note 3.
- Number of switch statements
- See note 3.
- Number of case labels
- See note 3.
- Number of default labels
- See note 3.
- Number of break statements
- See note 3.
- Number of for statements
- See note 3.
- Number of while statements
- This metric does not include the
do .. while form.
See note 3.
- Number of do statements
- See note 3.
- Number of continue statements
- See note 3.
- Number of goto statements
- See note 3.
- Number of return statements
- See note 3.
- Total number of object and object-like identifiers
- Also includes macros.
- Number of unique object and object-like identifiers
- Also includes macros.
- Number of global namespace occupants at function's top
-
This metric measures the namespace pollution in the object namespace
at the point before entering a function.
Its value is the count of all macros as well as objects with
file and project-scope visibility that are declared at the point it
is measured.
See note 1.
See note 4.
- Number of parameters
- See note 1.
- Maximum level of statement nesting
-
In order to avoid excessively inflating this metric when measuring
sequences of the form
if (a) {
...
} else if (b) {
...
} else if (c) {
...
} else
...
}
this metric does not take into account the nesting
of else clauses.
Thus the above code will be given a nesting level of 1,
rather than 3, which is implied by the following
(actual) reading of the code.
if (a) {
...
} else
if (b) {
...
} else
if (c) {
...
} else
...
}
See note 1.
See note 4.
- Fan-in (number of calling functions)
-
This is also listed under a function's details for functions
that are not defined (and have not metrics associated with them).
- Cyclomatic complexity (control statements)
-
This metric, CC1 measures the number of branch points in the function.
In order to avoid misleadingly high values that occur from
even trivial
switch statements, this metric
measures the complexity of a switch statement as 1.
- Extended cyclomatic complexity (includes branching operators)
-
This metric, CC2, takes into account the nodes introduced by the Boolean-AND,
boolean-OR, and conditional evaluation operators.
- Maximum cyclomatic complexity (includes branching operators and all switch branches)
-
This metric, CC3, considers each
case label as a separate node.
- Structure complexity (Henry and Kafura)
-
This metric is calculcated as follows.
Cp = (fan_in * fan_out)2
- Halstead volume
-
This metric is calculcated as follows.
HC = (number_of_operators +
number_of_operands) *
log2(
unique_number_of_operators +
unique_number_of_operands)
Where operands are object identifiers, macros,
numeric and character constants.
For the purpose of determining unique operands,
each numeric or character constant is considered
a separate operand.
- Information flow metric (Henry and Selig)
-
This metric is calculcated as follows.
HCp =
CC1 *
Cp
Notes
Note 1
This metric is measured the first time a file is encountered in a project.
The metric does not take into account regions that were not processed
due to conditional compilation.
Note 2
This metric is calculated before preprocessing, so as to account
operators occuring in function-like macros to the corresponding macro.
However, this makes it difficult to differentiate between commas used
to separate function arguments and the comma operator.
As a result the comma is ignored as an operator.
Note 3
This metric is calculated before preprocessing, so as to account
keywords occuring in function-like macros to the corresponding macro.
As a result C keywords used during preprocessing as identifiers,
as in
#define x(if, while, else) (if + while + else)
will be miscounted as keywords occuring in the corresponding
macro.
Furthermore keywords generated during preprocessing, as in
#define WHILE(x) while(x) {
#define WEND }
WHILE (x)
foo();
WEND
will not be counted as occuring in the corresponding C function.
Note 4
This metric is not measured for function-like macros.
Shortcomings
The nature of the C language and its preprocessor can result in pathological
cases that can confuse the CScout analysis and substitution engine.
In all cases the confusion only results in erroneous analysis or
substitutions of the particular identifiers and will not affect other
parts of the code.
In some cases you can even slightly modify your workspace definition
or code to ensure CScout works as you intend.
The following cases are the most important in recognising and substituting
identifiers:
- Conditional compilation
Some programs have parts of them compiled under conditional preprocessor
directives.
Consider the following example:
#ifdef unix
#include <unistd.h>
#define erase_file(x) unlink(x)
#endif
#ifdef WIN32
#include <windows.h>
#define erase_file(x) DeleteFile(x)
#endif
main(int argc, char *argv[])
{
erase_file(argv[1]);
}
As humans we can understand that erase_file occurs three times
within the file.
However, because CScout preprocesses the file following the
C preprocessor semantics, it will typically match only two instances.
In some cases you can get around this problem by defining macros that will
ensure that all code inside conditional directives gets processed.
In other cases this will result in errors (e.g. a duplicate macro definition
in the above example).
In such cases you can include in your workspace the same project multiple
times, each time with a different set of defined macros.
workspace example {
project idtest {
define DEBUG 1
define TEST 1
file idtest.c util.c
}
project idtest2 {
define NDEBUG 1
define PRODUCTION
file idtest.c util.c
}
- Partial coverage of macro use
Consider the following example:
struct s1 {
int id;
} a;
struct s2 {
char id;
} b;
struct s3 {
double id;
} c;
#define getid(x) ((x)->id)
main()
{
printf("%d %c", getid(a), getid(b));
}
In the above example, changing an id instance should
also change the other three instances.
However, CScout will not associate the member of
s3 with the identifier appearing in the getid
macro or the
s1 or s2 structures,
because there is no getid macro invocation to link them together.
If e.g. id is replaced with val
the program will compile and function correctly,
but when one tries to access the c struture's member
in the future using getid an error will result.
struct s1 {
int val;
} a;
struct s2 {
char val;
} b;
struct s3 {
double id;
} c;
#define getid(x) ((x)->val)
main()
{
printf("%d %c", getid(a), getid(b)); /* OK */
printf(" %g", getid(c)); /* New statement: error */
}
To avoid this (rare) problem you can introduce dummy macro invocations
of the form:
#ifdef CSCOUT
(void)getid(d)
#endif
- Undefined macros
We employ a heuristic classifying all instances of an undefined macro
as being the same identifier.
Thus in the following sequence foo will match all
three macro instances:
#undef foo
#ifdef foo
#endif
#ifdef foo
#endif
#define foo 1
In most cases this is what you want, but there may be cases where the macro
appears in different files and with a different meaning.
In such cases the undefined instances of the macro will erroneously
match the defined instance.
In addition, the analysis of functions can be confused by the following
situations.
- Functions getting called through function pointers will not
appear in the call graphs.
This is a common limitation of static call analysis.
- Function-like macros called from inside function bodies that
were generated by macro expansion will not be registered as calls.
- Non-function like macros that expand into function calls will
not appear in the call graph; the corresponding functions will appear
to be called by the function containing the macro.
Finally, because function argument refactoring works at a higher level
thann simple identifiers, the following limitations hold.
- When a function call's arguments macro-expand into unballanced brackets
or into multiple function arguments the replacement can misbehave.
- When there is not a one-to-one correspondence between a
function's name and its associated identifier
(i.e. when the function's name is generated through macro-token concatenation)
the function argument refactoring is not offered as an option.
Error Messages
Warnings
-
#ifdef argument is not an identifier
The token following a
#ifdef
directive is not a legal identifier. -
Application of macro " ... ": operator # only valid before macro parameters
The stringizing operator
# was not followed
by a macro parameter. -
Assuming declaration int ... (...)
An undeclared identifier is used as a function. -
Duplicate (different) macro definition of macro ...
A defined macro can be redefined only if the
two definitions are exactly the same. -
Empty character literal
Character lirerals must include a character. -
Illegal combination of sign specifiers
The signedness specifiers used can not be combined
(e.g. unsigned signed). -
Processing automatically generated file; #line directive ignored.
A
#line
directive was found.
This signifies that the source file is automatically
generated and refactoring changes on that file may
be lost in the future.
References to the original source file are ignored. -
Sign specification on non-integral type - ignored
A signedness specification was given on a non-integral type. -
Undeclared identifier in typeof expression: ...
The identifier appearing within
typeof
has not been declared. -
Undeclared identifier: ...
An undeclared identifier was used
in a primary expression.
Fatal Errors
-
#pragma pushd: unable to get current directory: ...
The call to getcwd failed while
processing the
#pragma pushd
CScout-specific directive. -
EOF in comment
The end of file was reached while
processing a block comment. -
Error count exceeds 100; exiting ...
To avoid cascading errors only the first 100 errors
are reported. -
Invalid C token: '$'
A '$' token was encountered in C code.
Values starting with a '$' token are only allowed inside
yacc rules. -
Unable to get path of file ...
The Win32 GetfullPathName system call used to retrieve the
unique path file name failed (Windows-specific). -
Unable to stat file ...
The POSIX stat system call used to retrieve the
unique file identifier failed (Unix-specific).
Errors
-
#pragma echo: string expected
The
#pragma echo
CScout-specific directive was not followed by a
string. -
#pragma includepath: string expected
The
#pragma includepath
CScout-specific directive was not followed by a
string. -
#pragma process: string expected
The
#pragma process
CScout-specific directive was not followed by a
string. -
#pragma project: string expected
The
#pragma project
CScout-specific directive was not followed by a
string. -
#pragma pushd: string expected
The
#pragma pushd
CScout-specific directive was not followed by a
string. -
#pragma readonly: string expected
The
#pragma readonly
CScout-specific directive was not followed by a
string. -
#pragma ro_prefix: string expected
The
#pragma ro_prefix
CScout-specific directive was not followed by a
string. -
% not followed by yacc keyword
In the definitions section of a yacc file the
% symbol was not followed by a legal yacc keyword. -
%union does not have a member ...
The member used in a $<name>X yacc construct
was not defined as a %union member. -
Application of macro " ... ": operator # at end of macro pattern
No argument was supplied to the right
of the stringizing operator
#. -
Array not an abstract type
The underlying array object for which a type is
specified is not an abstract type. -
At most one storage class can be specified
More than one storage class was given for the same
object. -
Conflicting declarations for identifier ...
An identifier is declared twice
with compilation or linkage
unit scope with conflicting
declarations. -
Declared parameter does not appear in old-style function parameter list: ...
While processing an old-style (K&R) parameter
declaration, a declared parameter did not match
any of the parameters appearing in the function's
arguments definition. -
Division by zero in #if expression
A #if expression
divided by zero. -
Duplicate definition of identifier ...
An identifier is declared twice within the
same block. -
Duplicate definition of tag ...
A structure, union, or enumeration tag was defined
twice for the same entity. -
EOF while processing #if directive
The processing of code within a #if
block reached the end of file, without a
corresponding
#endif /
#else /
#elif directive. -
Empty #include directive
A
#include
directive was not followed by a filename specification. -
End of file in character literal
The end of file was reached while
processing a character literal:
a single quote was never closed. -
End of file in string literal
The end of file was reached while
processing a string. -
Explicit element tag without no %union in effect
The yacc $n syntax was used
to specify an element of the %union
but no union was defined.-
Illegal characters in hex escape sequence
A hexadecimal character escape sequence
\x continued with a non-hexadecimal
character. -
Illegal combination of type specifiers
The type specifiers used can not be combined
(e.g. double char). -
Illegal pointer dereference
An attempt was made to dereference an element that is not a pointer. -
Invalid #include syntax
A
#include
directive was not followed by a legal filename specification. -
Invalid application of basic type, storage class, or type specifier
A basic type, storage class or type specified was specified in
an invalid underlying object. -
Invalid character escape sequence
A character escape sequence \c can not be
recognised. -
Invalid macro name
The macro name specified in a
#define or
#undef
directive is not a valid identifier. -
Invalid macro parameter name
A macro parameter name specified in a
#define
directive is not a valid identifier. -
Invalid macro parameter punctuation
The formal parameters in a
#define macro
definition are not separated
by commas. -
Invalid preprocessor directive
An invalid preprocessor directive was found.
The directive did not match an identifier. -
Invalid type specification
An attempt was made to specify a type on an object that
did not allow this specification. -
Label ... already defined
The same goto label is defined more
than once in a given function. -
Macro [ ... ]: EOF while reading function macro arguments
The end of file was reached while
gathering a macro's arguments. -
Macro [ ... ]: close bracket expected for function-like macro
The arguments to a function-like macro did
not terminate with a closing bracket. -
Member access in incomplete struct/union: ...
The member access for a structure or union is applied
on an object with an incomplete definition. -
Missing close bracket in defined operator
The identifier of a
defined operator was not
followed by a closing bracket. -
Modulo division by zero in #if expression
A #if expression
divided by zero in a modulo
expression. -
Multiple storage classes in type declaration
Incompatible storage classes were specified in a single
type declaration. -
No identifier following defined operator
The
defined operator was not followed
by an identifier. -
Object is not a function
The object used as a function to be called is not a function
or a pointer to a function. -
Only struct/union anonymous elements allowed
Anonymous members within a member
declaring list (e.g.
struct {int x, y;})
can only be structures or unions.
(GCC/Microsoft C extension). -
Pointer not an abstract type
The underlying pointer object for which a type is
specified is not an abstract type. -
Popd: directory stack empty
The
#pragma popd
CScout-specific directive was performed on an
empty directory stack. -
Structure or union does not have a member ...
The structure or union on the left
of the
. or
-> operator
does not have as a member the
identifier appearing on the
operator's right. -
Subscript not on array or pointer
The object being subscripted using the []
operator is not an array or a pointer. -
Syntax error in preprocessor expression
A
#if or
#elif expression was syntactically
incorrect. -
Unable to open include file ...
The specified include file could not be opened. -
Unbalanced #elif
A
#elif
directive was found without a corresponding
#if. -
Unbalanced #else
A
#else
directive was found without a corresponding
#if. -
Unbalanced #endif
A
#endif
directive was found without a corresponding
#if. -
Undefined label ...
A goto
label used within a function was never defined. -
Unexpected end in character escape sequence
A character escape sequence (\c) was not
completed; no character follows the backslash. -
Unknown preprocessor directive: ...
An unkown preprocessor directive was found. -
Unkown %union element tag ...
The yacc %union
does not have as a member the
identifier appearing on the
element's tag. -
Yacc $value out of range
The number used in a $n yacc variable was greater than the
number of identifiers and actions on the rule's left side.
License
CScout is distributed as open source software under the GNU
General Public License, which is reproduced below.
Other licensing options and professional support are available
on request.
GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright © 2007 Free Software Foundation, Inc.
<http://fsf.org/ (http://fsf.org/)>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
“This License” refers to version 3 of the GNU General Public License.
“Copyright” also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
“The Program” refers to any copyrightable work licensed under this
License. Each licensee is addressed as “you”. “Licensees” and
“recipients” may be individuals or organizations.
To “modify” a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a “modified version” of the
earlier work or a work “based on” the earlier work.
A “covered work” means either the unmodified Program or a work based
on the Program.
To “propagate” a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To “convey” a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays “Appropriate Legal Notices”
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The “source code” for a work means the preferred form of the work
for making modifications to it. “Object code” means any non-source
form of a work.
A “Standard Interface” means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The “System Libraries” of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
“Major Component”, in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The “Corresponding Source” for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
- a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
- b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
“keep intact all notices”.
- c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
- d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
“aggregate” if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
- a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
- b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
- c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
- d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
- e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A “User Product” is either (1) a “consumer product”, which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, “normally used” refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
“Installation Information” for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
“Additional permissions” are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
- a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
- b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
- c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
- d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
- e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
- f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered “further
restrictions” within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An “entity transaction” is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A “contributor” is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's “contributor version”.
A contributor's “essential patent claims” are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, “control” includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a “patent license” is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To “grant” such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. “Knowingly relying” means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is “discriminatory” if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License “or any later version” applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM “AS IS” WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
Frequently Asked Questions
Contents
How do I handle conditional compilation?
You can either define macros that will cover all conditional cases,
or process the same project multiple times using different macro
definitions.
See this page.
How can I handle automatically generated files?
Some projects use mini domain-specific languages
similar to yacc and lex to express some of their
elements.
CScout can natively parse C and yacc source files, but
no other language.
Obviously changes should be performed in the original domain-specific
files, rather than the generated C code.
On the other hand, CScout can not parse the original files,
but can parse the generated code.
To escape this situation include the automatically generated file
in your workspace definition, but define it as read-only.
In this way CScout will not allow you to modify identifiers appearing
in it.
How can I save an identifier or file query?
Simply bookmark the page that shows the query's results.
You can even pass the URL around or print it on a T-shirt;
the URL contains the whole query.
Why aren't my call graphs appearing in the form I specified?
Changing the global options that specify the format of call graphs
affects the types of links appearing in the corresponding pages.
If you go to a previous page using the back button and you do not
reload it, you will use the old links and will obtain the old type
of call graph.
This is the only instance where the use of the back button will
surprise you.
How can I locate and fix a syntax error?
Most syntax errors occur due to compiler extensions or incorrect
definitions of macros.
They can often be corrected, by introducing a dummy macro that gets around
the corresponding compiler extension, like the following.
#define __declspec(x)
If the problem isn't obvious from the source code, you might need
preprocess the file by using the -E option,
and look at the preprocessed code.
To do this search in the preprocessed code for an (ideally unique)
occurrence of non-macro code near the problem spot.
Why is my read-only prefix pragma not working under Windows?
Filename matching under Windows is a difficult subject.
Filenames retain case, but are compared in a case insensitive manner.
To avoid problems, when writing ro_prefix and ipath
pragmas under a Windows platform, respect the following rules.
- Include a drive letter in the path.
- Write the drive letter in uppercase.
- Separate the path elements using a single backslash.
- Do not end the path with a trailing backslash.
My system appears to be using the hard disk excessively (thrashing). Why?
CScout tags and follows each and every identifier of the source
code it processes, including header files.
As a result, the memory requirements of CScout are considerable.
Typical memory requirements are 700-1600 bytes per line processed.
If your system's main memory is less than the ammount needed,
CScout will page to disk and thrashing will occur.
Why can't I see SVG call graphs in my browser?
Make sure your browser supports SVG viewing.
For instance, Firefox and Internet Explorer work fine; SeaMonkey doesn't.
Why doesn't the Tab key in the Safari browser allow me to move to each identifier definition?
Press Option (or Alt) Tab, instead of
Tab.
You can also permanently change Safari's behavior under
Safari - Preferences - Advanced.
Isn't the CScout logo infringing the intellectual property of the International Scout movement?
The emblem of the International Scout movement is based on
the fleur de lys,
a traditional design of the 11th century that was later used
to decorate maps and compass cards.
CScout acts as a compass and a map for C code, so the association
with the fleur de lys is particularly relevant.
You can read more about the fleur de lys symbol at the
Wikipedia (http://www.wikipedia.org/wiki/Fleur-de-lis)
web site entry.
Places or institutions
that use the symbol informally or as part of their heraldic arms are:
Quebec; Canada; Augsburg, Germany; Florence, Italy; Slovenia; the
Fuggers medieval banking family; Bosnia and Herzegovina; and Louisville,
Kentucky; the Prince of Wales also has a fleur de lys on his coat of
arms.
A
Google image search (http://images.google.com.gr/images?q=fleur+de+lys&hl=en&lr=&ie=ISO-8859-1&safe=on) for the image
will also show you tens of similar designs.
Finally, note that the International Scout movement's
rendering of the image includes two stars on the left and right leaves.
CScout's logo does not contain this distinctive feature.
The cscc Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
EXAMPLE
SEE ALSO
AUTHOR
NAME
cscc -
CScout C compiler front end
SYNOPSIS
cscc
[gcc(1) options]
DESCRIPTION
cscc is
a wrapper around gcc. commands. When invoked instead
of gcc, it will compile the specified file(s) in the
same way as gcc would do. As a side-effect it will
monitor the invocation of gcc(1) and record its
environment and arguments. With those data it will generate
a CScout project specification that can be used to
process the file(s) that were compiled. The project
specification is saved into a file named make.cs.
EXAMPLE
The following
commands are often the only ones required to process a few C
files.
cscc example.c
cscout make.cs
If you want to
use cscc with another C compiler, prepend
CC=compiler-name to the cscc
invocation, as shown in the following example.
CC=x86_64-w64-gcc cscc
SEE ALSO
cscout(1),
csmake(1)
AUTHOR
(C) Copyright
2006-2019 Diomidis Spinellis.
The cscout Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
OPTIONS
EXAMPLE
SEE ALSO
AUTHOR
NAME
cscout - C
code analyzer and refactoring browser
SYNOPSIS
cscout
[-bCcrv3] [-d D] [-d
H] [-E file specification]
[-l log file] [-p
port] [-R specification]
[-M files] [-m
specification] [-t sname]
[-o | -S db |
-s db | -M files]
file
DESCRIPTION
CScout is
a source code analyzer and refactoring browser for
collections of C programs. It can process workspaces of
multiple projects (we define a project as a collection of C
source files that are linked together) mapping the
complexity introduced by the C preprocessor back into the
original C source code files. CScout takes advantage
of modern hardware advances (fast processors and large
memory capacities) to analyze C source code beyond the level
of detail and accuracy provided by current compilers and
linkers. The analysis CScout performs takes into
account the identifier scopes introduced by the C
preprocessor and the C language proper scopes and
namespaces.
CScout as
a source code analyzer can:
|
• |
|
annotate source code with hyperlinks to each
identifier |
|
• |
|
list files that would be affected by changing a specific
identifier |
|
• |
|
determine whether a given identifier belongs to the
application or to an external library based on the
accessibility and location of the header files that declare
or define it |
|
• |
|
locate unused identifiers taking into account
inter-project dependencies |
|
• |
|
perform queries for identifiers based on their
namespace, scope, reachability, and regular expressions of
their name and the filename(s) they are found in, |
|
• |
|
perform queries for files, based on their metrics, or
properties of the identifiers they contain |
|
• |
|
monitor and report superfluously included header
files |
|
• |
|
provide accurate metrics on identifiers and files |
More
importantly, CScout helps you in refactoring code by
identifying dead objects to remove, and can automatically
perform accurate global rename identifier
refactorings. CScout will automatically rename
identifiers
|
• |
|
taking into account the
namespace of each identifier: a renaming of a structure tag,
member, or a statement label will not affect variables with
the same name |
|
• |
|
respecting the scope of the renamed identifier: a rename
can affect multiple files, or variables within a single
block, exactly matching the semantics the C compiler would
enforce |
|
• |
|
across multiple projects when the same identifier is
defined in common shared include files |
|
• |
|
occuring in macro bodies and parts of other
identifiers, when these are created through the C
preprocessor’s token concatenation feature |
This manual page
describes the CScout invocation and command-line
options. Details about its web interface, setup, and
configuration can be found in the online hypertext
documentation and at the project’s home page
http://www.spinellis.gr/cscout.
OPTIONS
|
-C |
|
Create a ctags-compatible
tags file. Tens of editors and other tools can utilize tags
to help you navigate through the code. In contrast to other
tag generation tools, the file that CScout creates
also includes information about entities dynamically
generated through macros. |
|
-c |
|
Exit immediately after processing the specified files.
Useful, when you simply want to check the source code for
errors or when you want to create a tags file. |
|
-d D |
|
Display the #define directives being processed
on the standard output. |
|
-d H |
|
Display the (mainly header) files being included on the
standard output. Each line is prefixed by a number of dots
indicating the depth of the included file stack. |
-E file
specification
Preprocess the file specified
with the regular expression given as the option’s
argument and send the result to the standard output.
-p port
The web server will listen for
requests on the TCP port number specified. By default the
CScout server will listen at port 8081. The port
number must be in the range 1024-32767.
-M files
Specify names of CSV input
files to merge into specified generated output files. These
merge sharded database tables involving equivalence classes.
Further details can be found in the file
eclasses.sql, which utilizes this feature.
-m
specification
Specify the type of identifiers
that CScout will monitor. The identifier attribute
specification is given using the syntax:
Y|L|E|T[:attr1][:attr2]...
The meaning of the first letter is:
|
Y: |
|
Match anY of the specified attributes |
|
|
L: |
|
Match alL of the specified attributes |
|
|
E: |
|
ExcludE the specified attributes matched |
|
|
T: |
|
ExacT match of the specified attributes |
|
Allowable
attribute names and their corresponding meanings are:
unused:
Unused identifier
writable:
Writable identifier
idmtoken:
Identifier stored in a
macro
funmacro:
Defined as a function-like
macro
cppconst:
Used to derive a preprocessor
constant, i.e. used in a #if or #include
directive or in a defined() expression
cppstrval:
Macro’s value is used as
a string (pasting or stringization) in the preprocessor
defcconst:
Macro value seen as a C
compile-time constant
defnotcconst:
Macro value seen as not a C
compile-time constant
expcconst:
Macro value seen as a C
compile-time constant
expnotcconst:
Macro value seen as not a C
compile-time constant
|
tag: |
|
Tag for a struct/union/enum |
|
member:
Member of a struct/union
|
label: |
|
Label |
|
obj: |
|
Ordinary identifier (note that enumeration constants and
typedefs belong to the ordinary identifier namespace) |
|
macro: |
|
Preprocessor macro |
umacro:
Undefined preprocessor
macro
macroarg:
Preprocessor macro argument
fscope:
Identifier with file scope
pscope:
Identifier with project
scope
typedef:
Typedef
enumconst:
Enumeration constant
function:
C function
The -m
flag can provide enormous savings on the memory
CScout uses (specify e.g. -m Y:pscope to only
track project-global identifiers), but the processing
CScout performs under this flag is unsound.
The flag should therefore be used only if you are running
short of memory. There are cases where the use of
preprocessor macros can change the attributes of a given
identifier shared between different files. Since the
-m optimization is performed after each single file
is processed, the locations where an identifier is found may
be misrepresented.
|
-r |
|
Report on the standard error output warnings about
unused and wrongly scoped identifiers and unused included
files. The error message format is compatible with
gcc and can therefore be automatically processed by
editors that recognize this format. |
|
-v |
|
Display the CScout version and copyright
information and exit. |
|
-3 |
|
Implement support for trigraph characters. |
|
-b |
|
Operate in multiuser browse-only mode. In this mode the
web server can concurrently process multiple requests. All
web operations that can affect the server’s
functioning (such as setting the various options, renaming
identifiers, refactoring function arguments, selecting a
project, editing a file, or terminating the server) are
prohibited. Call graphs are truncated to 1000 elements
(nodes or edges). |
-S database
dialect
Output the database schema as
an SQL script. Specify help as the database dialect
to obtain a list of supported database back-ends.
-s database
dialect
Dump the workspace contents as
an SQL script. Specify help as the database dialect
to obtain a list of supported database back-ends.
-M files
Merge the specified
eclasses, ids, and functionids files
that contain token, id, and functionid, details into new
records saved in three further corresponding files. These
can be directly imported into the tokens, ids,
and functionids tables.
-l log
file
Specify the location of a file
where web requests will be logged.
-R
specification
Generate call graphs and exit.
The option can be specified multiple times. The
specification is the type of desired graph
(fgraph.txt for a file dependency graph or
cgraph.txt for a function and macro call graph),
optionally followed by parameters appearing in the
corresponding URL of the CScout web interface. The
generated text file contains one space-delimited
relationship per line. It can be further processed by tools
such sas awk and dot to produce graphical
output as shown in the following examples.
# Create a function call graph and a compile-time file dependency graph
cscout -R cgraph.txt -R fgraph.txt?gtype=C.
# Convert the generated call graph into an SVG diagram
awk ’
BEGIN { print "digraph G {" }
{print $1 "->" $2}
END { print "}" }’ cgraph.txt |
dot -Tsvg >cgraph.svg
-t name
Generate SQL output for the
named table. By default SQL output for all tables is
generated. If this option is provided, then output only for
the specified tables will be generated. It is the
user’s responsibility to list the tables required to
avoid breaking integrity constraints. The option can be
specified multiple times.
|
-o |
|
Create obfuscated versions of all the writable files of
the workspace. |
EXAMPLE
Assume you want
to analyze three programs in /usr/src/bin. You
first create the following project definition file,
bin.prj.
# Some small tools from the src/bin directory
workspace bin {
ro_prefix "/usr/include"
cd "/usr/src/bin"
project cp {
cd "cp"
file cp.c utils.c
}
project echo {
cd "echo"
file echo.c
}
project date {
cd "date"
file date.c
}
}
Then you compile
the workspace file bin.prj by running the
CScout workspace compiler cswc on it, and
finally you run cscout on the compiled workspace
file. At that point you are ready to analyze your code and
rename its identifiers through your web browser.
$ cswc bin.prj >bin.cs
$ cscout bin.cs
Processing workspace bin
Entering directory /usr/src/bin
Processing project cp
Entering directory cp
Processing file cp.c
Done processing file cp.c
Processing file utils.c
Done processing file utils.c
Exiting directory cp
Done processing project cp
Processing project echo
Entering directory echo
Processing file echo.c
Done processing file echo.c
Exiting directory echo
Done processing project echo
Processing project date
Entering directory date
Processing file date.c
Done processing file date.c
Exiting directory date
Done processing project date
Exiting directory /usr/src/bin
Done processing workspace bin
Post-processing /usr/home/dds/src/cscout/bin.c
[...]
Post-processing /vol/src/bin/cp/cp.c
Post-processing /vol/src/bin/cp/extern.h
Post-processing /vol/src/bin/cp/utils.c
Post-processing /vol/src/bin/date/date.c
Post-processing /vol/src/bin/date/extern.h
Post-processing /vol/src/bin/date/vary.h
Post-processing /vol/src/bin/echo/echo.c
Processing identifiers
100%
We are now ready to serve you at http://localhost:8081
SEE ALSO
cscc(1),
cscut(1), csmake(1), csreconst(1),
cssplit(1), cswc(1).
AUTHOR
(c) Copyright
2003-2024 Diomidis Spinellis.
The cscut Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
EXAMPLE
SEE ALSO
AUTHOR
NAME
cscut -
Extract portions of a CScout processing script
SYNOPSIS
cscut
[-b] [-e] [-F file-list |
-f file | -p project]
cscout-file
DESCRIPTION
The cscut
command-line tool extracts specific portions of a
CScout processing script. It provides a flexible way
to select parts of the CScout processing script based
on files or projects.
The following
options are available:
|
-b |
|
Output from the file’s beginning until the
specified point. |
|
|
-e |
|
Output from the specified point to the end of the
file. |
|
-F file-list
Output a script to process only
the files specified in file-list, where
file-list is a file containing a list of
filenames.
-f file
Output a script to process only
the specified file.
-p project
Output a script to process only
the specified project.
The last
argument, cscout-file, specifies the CScout
processing script to be processed.
EXAMPLE
Below are some
typical use cases for cscut.
Extract a script
to process the file x86.cs:
cscut -f /home/dds/src/linux/arch/x86/kvm/x86.c make.cs >x86.cs
Extract a script
to process the files listed in file-list.txt:
cscut -F file-list.txt make.cs >files.cs
Extract a script
to process only the project .tmp_vmlinux3:
cscut -p /home/dds/src/linux/.tmp_vmlinux3 >linux.cs
Extract a script
to process from the file export.c and onward:
cscut -f /home/dds/src/linux/fs/ocfs2/export.c linux.cs >ocfs2-export.cs
SEE ALSO
cscout(1),
cssplit(1), csmake(1)
AUTHOR
(C) Copyright
2024 Diomidis Spinellis.
The csmake Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
OPTIONS
EXAMPLES
SEE ALSO
AUTHOR
NAME
csmake -
CScout make
SYNOPSIS
csmake [
[-d] [-h] [-k]
[-o output-file] [-s
cs-files-directory] [-A]
[-T temporary-directory]
[-t time-file] [-N
rules-file] -- ] [make(1) options]
DESCRIPTION
csmake is
a wrapper around make and typical C compilation
commands. When invoked instead of make on a clean
(unbuilt) system, it will build the system in the same way
as make. As a side-effect it will monitor the
invocations of cc(1), gcc(1), clang(1),
ar(1), ld(1), and mv(1) commands and
record their environment and arguments. With those data it
will generate a CScout project specification that can
be used to process the project that was compiled. The
project specification is saved into a file named
make.cs. Moreover, a separate CScout .cs file can be
generated for each executable in a specified
cs_files_directory.
To allow
csmake to be used as a drop in replacement in build
sequences that execute multiple make commands, you
can create a /tmp/csmake-spy, which will be used to
create rules for the superset of all make-generated
executables.
csmake
options can be passed through CSMAKEFLAGS environment
variable.
OPTIONS
|
-d |
|
Run in debug mode (it also keeps
spy directory in place). |
|
|
-h |
|
Print help message. |
|
|
-k |
|
Keep temporary directory in place. |
|
-o
output-file
Specify the name of the
generated specification file, which is by default make.cs
. A name of - will output the file on the standard
output.
-p
toolchain-prefix
Specify the cross-compilation
toolchain prefix, e.g. aarch64-linux-gnu-. This
changes the names of monitored toolchain commands by
prefixing their name as specified, e.g. .
aarch64-linux-gnu-gcc and thus allows csmake
to be applied in a cross-compilation environment.
-s
cs-files-directory
Create a separate CScout .cs
file for each real executable. Save the .cs files into
cs-files-directory in the current directory.
|
-A |
|
Generate cs projects for static libraries. |
|
-N
rules-file
Run on an existing rules
file.
-T
temporary-directory
Set temporary directory. Use
temporary-directory as temporary directory, remember
to clear it if you use it multiple times.
-t
time-file
Record C compiler timing
information in the specified file. The information recorded
is the output of time(1) with format ’%D %e
%F %I %K %M %O %S %U.
EXAMPLES
The following
commands are often the only ones required to process a
typical C project.
make clean
csmake
cscout make.cs
If you want to
use csmake with another C compiler, prepend
CC=compiler-name to the csmake
invocation, as shown in the following example.
CC=x86_64-w64-gcc csmake
The following
commands create an inspectable rules file, and then
use that to creat the final make.cs file. (Note the
obligatory -- sequence used to terminate the
csmake arguments.)
mkdir csmake-tmp
csmake -k -T csmake-tmp --
csmake -N csmake-tmp/rules --
The following
commands can be used to run csmake for a Debian
package using the dpkg-buildpackage command.
rm -rf tmp_dir && mkdir -p tmp_dir
CSMAKEFLAGS=’-T tmp_dir -A -s cscout_projects -k --’ \
MAKE=/usr/local/bin/csmake dpkg-buildpackage -b
SEE ALSO
cscout(1),
cscut(1), cssplit(1).
AUTHOR
(C) Copyright
2006-2024 Diomidis Spinellis.
The csreconst Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
EXAMPLES
EXIT STATUS
SEE ALSO
AUTHOR
NAME
csreconst
- Test the reconstitution of files from a CScout
database
SYNOPSIS
csreconst
-t [-ckqs] database.db
csreconst -f file [-o] [-b
line] [-e line] ...
database.db
DESCRIPTION
csreconst
is a utility for testing the reconstitution of files stored
in a CScout database or reconstituting specific
files.
The program
provides two modes of operation:
|
-t |
|
Test the reconstitution of all files in the specified
SQLite database.db. Additional options can be
specified to refine the behavior of the testing: |
|
-c |
|
Count the number of correct and incorrect files. |
|
-k |
|
Keep comparing after finding a difference. |
|
-q |
|
Run a quick diff without listing the full
differences. |
|
-s |
|
Provide a summary of each file’s reconstitution
result. |
-f
Reconstitute a specified file stored in SQLite
database.db. Additional options allow fine-grained
control of the reconstitution:
-b line
Reconstitute starting from the
specified beginning line number.
-e line
Reconstitute up to the
specified ending line number.
|
-o |
|
Prefix each reconstituted part with its file offset
value. |
|
EXAMPLES
Test all files
in a CScout database and provide a summary:
csreconst -tckqs result.db
Reconstitute the
file main.c from a CScout database:
csreconst -f main.c result.db
Reconstitute
file main.c from line 10 to line 50, listing the
offset of each part:
csreconst -f main.c -b 10 -e 50 -o result.db
EXIT STATUS
The exit code
indicates the result of the comparison operation:
|
0 |
|
All files compare equal (no
differences found). |
|
1 |
|
Differences were found between the reconstituted and
original files. |
SEE ALSO
cscout(1),
csmake(1)
AUTHOR
(C) Copyright
2024 Diomidis Spinellis.
The cssplit Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
OPTIONS
EXAMPLE
SEE ALSO
AUTHOR
NAME
cssplit -
Split a CScout processing script into smaller scripts
SYNOPSIS
cssplit
[-h] -s N file
[file ...]
DESCRIPTION
The
cssplit command-line program splits a CScout
processing script into N smaller scripts for parallel
or distributed processing. Each output script is named using
a zero-padded sequence, starting with
file-0000.cs.
The input is
read from the specified file(s), and the output files are
written into the current working directory.
This tool is
useful for distributing the workload of a large
CScout analysis across multiple scripts for
efficiency or manageability.
OPTIONS
-s,
--shards N
Specifies the number of output
scripts to generate. The input processing script is divided
into N approximately equal parts. Each output script
contains the appropriate subset of the input commands to
ensure no loss of information during the split. Compilation
units from multiple inter-dependent projects (e.g. different
configurations of the same executable) are distributed to
the scripts so as to maximize locality of reference.
-h,
--help
Display a brief usage message
and exit.
EXAMPLE
To split an
input processing script into 4 smaller scripts:
cssplit -s 4 make.cs
This will create
the following files in the current directory:
file-0000.cs
file-0001.cs
file-0002.cs
file-0003.cs
Each file
contains a portion of the original processing script.
SEE ALSO
cscout(1),
cscut(1), csmake(1)
AUTHOR
(C) Copyright
2024-2025 Diomidis Spinellis.
The cswc Command Manual Page
NAME
SYNOPSIS
DESCRIPTION
OPTIONS
EXAMPLE
SEE ALSO
AUTHOR
NAME
cswc -
CScout workspace compiler
SYNOPSIS
cswc
[-gv] [-d directory]
[file]
DESCRIPTION
cswc is
a workspace compiler for the CScout C source code
analyzer and refactoring browser. CScout integrates
in a single process the functionality of a multi-project
build engine, an ANSI C preprocessor, and the parts of a C
compiler up to and including the semantic analysis based on
types. The build engine functionality is required to allow
the user to process multiple compilation and link units as a
single batch. Only thus can CScout detect
dependencies across different files and projects. Each
compilation unit can reside in a different directory and can
require processing using different macro definitions or a
different include file path. In a normal build process these
options are typically specified in a Makefile. The
CScout operation is similarly guided by a declarative
workspace definition file. To decouple the complexity of the
CScout workspace processing specification from its
actual operation, and to encouriage experimentation with
alternative (e.g. IDE-based) workspace specification
mechanisms, CScout is guided by a very simple
imperative script typically generated from more
sophisticated workspace definitions by cswc, the
CScout workspace compiler.
This manual
page describes the cswc invocation and command-line
options. Details about its input and output formats, setup,
and configuration can be found in the online hypertext
documentation and at the project’s home page
http://www.spinellis.gr/cscout.
OPTIONS
-d
directory
Specify the directory to use
for locating the CScout configuration files.
|
-g |
|
Compile the project as generic rather than host-specific
C code. This means that the generated files will include
CScout’s standard-C include and macro definition files
(stdc-incs.h and stdc-defs.h), rather than the
host-specific ones (host-incs.h and
host-defs.h). |
|
-v |
|
Display the cswc version and copyright
information and exit. |
EXAMPLE
The following
is a configuration file used for processing the
apache web server.
workspace apache {
cd "/usr/local/src/apache/src"
ro_prefix "/usr/local/src/apache/src/include/ap_config"
# Global project definitions
define HTTPD_ROOT "/usr/local/apache"
define SUEXEC_BIN "/usr/local/apache/bin/suexec"
define SHARED_CORE_DIR "/usr/local/apache/libexec"
define DEFAULT_PIDLOG "logs/httpd.pid"
define DEFAULT_SCOREBOARD "logs/httpd.scoreboard"
define DEFAULT_LOCKFILE "logs/httpd.lock"
define DEFAULT_XFERLOG "logs/access_log"
define DEFAULT_ERRORLOG "logs/error_log"
define TYPES_CONFIG_FILE "conf/mime.types"
define SERVER_CONFIG_FILE "conf/httpd.conf"
define ACCESS_CONFIG_FILE "conf/access.conf"
define RESOURCE_CONFIG_FILE "conf/srm.conf"
define AUX_CFLAGS
define LINUX 22
define USE_HSREGEX
define NO_DL_NEEDED
# Give project-specific directory and include path properties
project gen_uri_delims {
cd "main"
ipath "../os/unix"
ipath "../include"
file gen_uri_delims.c
}
# Alternative formulation; specify per-file properties
project gen_test_char {
file gen_test_char.c {
cd "main"
ipath "../os/unix"
ipath "../include"
}
}
# httpd executable; specify directory-based properties
project httpd {
directory main {
ipath "../os/unix"
ipath "../include"
file alloc.c buff.c http_config.c http_core.c
file http_log.c http_main.c http_protocol.c
file http_request.c http_vhost.c util.c util_date.c
file util_script.c util_uri.c util_md5.c rfc1413.c
}
directory regex {
ipath "."
ipath "../os/unix"
ipath "../include"
define POSIX_MISTAKE
file regcomp.c regexec.c regerror.c regfree.c
}
directory os/unix {
ipath "../../os/unix"
ipath "../../include"
file os.c os-inline.c
}
directory ap {
ipath "../os/unix"
ipath "../include"
file ap_cpystrn.c ap_execve.c ap_fnmatch.c ap_getpass.c
file ap_md5c.c ap_signal.c ap_slack.c ap_snprintf.c
file ap_sha1.c ap_checkpass.c ap_base64.c ap_ebcdic.c
}
directory modules/standard {
ipath "../../os/unix"
ipath "../../include"
file mod_env.c mod_log_config.c mod_mime.c
file mod_negotiation.c mod_status.c mod_include.c
file mod_autoindex.c mod_dir.c mod_cgi.c mod_asis.c
file mod_imap.c mod_actions.c mod_userdir.c
file mod_alias.c mod_access.c mod_auth.c mod_setenvif.c
}
directory . {
ipath "./os/unix"
ipath "./include"
file modules.c buildmark.c
}
}
}
SEE ALSO
cscout(1)
AUTHOR
(C) Copyright
2003 Diomidis Spinellis.
Bibliography
- American National
Standard for Information Systems — programming language — C:
ANSI X3.159–1989, December 1989.
(Also ISO/IEC 9899:1990).
- Darren C. Atkinson and
William G. Griswold.
The
design of whole-program analysis tools.
In 18th International Conference on Software Engineering, ICSE
'96, pages 16–27, New York, 1996. ACM, ACM Press.
- Greg J.
Badros and David Notkin.
A framework for preprocessor-aware C source code analyses.
Software: Practice and Experience, 30(8):907–924, July 2000.
- Michael D.
Ernst, Greg J. Badros, and David Notkin.
An empirical
analysis of C preprocessor use.
IEEE Transactions on Software Engineering, 28(12):1146–1170,
December 2002.
- Martin Fowler.
Refactoring: Improving the Design of Existing Code.
Addison-Wesley, Boston, MA, 2000.
With contributions by Kent Beck, John Brant, William Opdyke, and Don
Roberts.
- International Organization for
Standardization.
Programming Languages — C.
ISO, Geneva, Switzerland, 1999.
ISO/IEC 9899:1999.
- Brian W. Kernighan and
Dennis M. Ritchie.
The C Programming Language.
Prentice-Hall, Englewood Cliffs, NJ, second edition, 1988.
- James R.
Larus, Thomas Ball, Manuvir Das,
Robert DeLine, Manuel Fähndrich,
Jon Pincus, Sriram K. Rajamani, and
Ramanathan Venkatapathy.
Righting software.
IEEE Software, 21(3):92–100, May/June 2004.
- Diomidis
Spinellis.
Global
analysis and transformations in preprocessed languages.
IEEE Transactions on Software Engineering, 29(11):1019–1030,
November 2003.
- Diomidis
Spinellis.
A
tale of four kernels.
In Wilhem Schäfer, Matthew B. Dwyer, and
Volker Gruhn, editors, ICSE '08: Proceedings of the
30th International Conference on Software Engineering, pages 381–390,
New York, May 2008. Association for Computing Machinery.
(doi:10.1145/1368088.1368140 (http://dx.doi.org/10.1145/1368088.1368140))
- Diomidis
Spinellis.
Optimizing
header file include directives.
Journal of Software Maintenance and Evolution: Research and
Practice, 21(4):233–251, July/August 2009.
(doi:10.1002/smr.369 (http://dx.doi.org/10.1002/smr.369))
- Diomidis
Spinellis.
CScout:
A refactoring browser for C.
Science of Computer Programming, 75(4):216–231, April 2010.
(doi:10.1016/j.scico.2009.09.003 (http://dx.doi.org/10.1016/j.scico.2009.09.003))
- Jonathan Yavner.
Back-propagation of knowledge from syntax tree to C source code.
ACM SIGPLAN Notices, 39(3):31–37, March 2004.
Change History
- Version 3.1 (under development)
- Version 3.0 (2016-01-17)
-
- Source code, repository, build process, and installation procedures were polished for distribution and released through GitHub licensed under GPL.
- Changes and features are from now on tracked through the publicly available Git commit log.
- Version 2.8 (2011-10-23)
-
- New
-C option will create a ctags compatible
tags file, which many editors can use to navigate through the code.
- New
-d D option will dump on the standard output
the #define directives that get processed.
- New
-d H option will dump on the standard output
the (mostly header) files getting included.
- Correct appearance of page labels whene these span more than one line.
- Functions defined through macro calls get a more precise location of
the point where they are defined.
- Version 2.7 (2009-07-08)
-
- New call graph for functions showing a function in context:
with all the paths from its callers and all called functions.
- When saving refactored code CScout will verify that the
renamed identifiers do not clash with other existing identifiers.
This requires a complete re-processing of the code.
A corresponding option can disable this feature.
- Added function argument refactorings page through which
function argument refactorings can be reviewed, changed, and
deactivated.
- Optimize file handling during the post-processing phase.
In a typical use case this results in a 37% reduction in
processing time.
- Correct handling of function names appearing as function pointers,
when refactoring function arguments.
- Corrected dot syntax error when generating graphs with no global options set.
- Better error handling when refactored files cannot be renamed or unlinked.
- Preprocessor expressions are evaluated as if the have the same
representation intmax_t/uintmax_t, rather than long.
- Fix a crash that occurred when processing Apache httpd 1.3.27.
- Fix to avoid csmake getting confused by ccache.
- Version 2.6 (2008-12-05)
-
- Add support for the display of graph files in PDF and PNG format.
- Add options for passing graph, node, and edge properties to dot.
- cswc now deals correctly with scoped definitions for files.
- Correct the generation of obfuscated identifiers in platforms
where they were invalid.
- Support the unification of yacc terminal symbols with the
corresponding
y.tab.h macros.
- Correct extraneous line spacing in source code listings of files
containing carriage returns.
- Fix the display of graphs with empty nodes.
- Correct the handling of identifiers declaring a function at
an inner scope with no storage-class specifier (ISO C 6.2.2-5.)
- Version 2.5 (2008/11/17)
-
- Each file's web page now provides links for generating
compile-time, control, and data dependency graphs.
- Identifier queries can now provide the functions where an identifier
appears.
- Bring in line the semantics of the
include_next
preprocessor directive with those of gcc.
- Yacc identifiers now live in a separate namespace.
Terminal symbols are still visible in C code as ordinary identifiers,
but the potential for clashes between non-terminal names and C identifiers
has been eliminated.
This change also fixes the handling of rules for yacc untyped non-terminals,
and the calculation of file-local identifier metric in yacc files.
- The provided definition files match closer the gcc builtins.
- The file details page now provides links for listing functions defined
in the file and their call graph.
- The main page and the individual file details pages now provide options
for generating include graphs.
-
In file, function, and identifier queries one can now specify to
exclude results from filenames matching a particular regular expression.
- Take into account the appropriate order of CScout configuration
directories when saving options.
- CScout's web interface received a facelift, and many pages should now
be clearer and easier to navigate.
- The second tab appearing in a source code's line is now correctly expanded.
- An option allows the addition of URLs in dot output.
- Remove redundancy from the saved options file.
- Version 2.4 (2008/07/15)
-
- The web front-end now includes support for a multiuser read-only
browsing mode, and a log file.
- The web front end now includes support for directory browsing.
-
The
include_next gcc-specific directive now
works correctly, even when preceded in its file by other include
directives.
-
Allow macro directives inside a macro-function call.
According to the C standard the behavior of this is undefined,
but gcc preprocessor does the right thing.
- The web front-end now provides functionality for refactoring
the arguments of function calls.
A template mechanism allows changing the order of function arguments,
removing arguments, and introducing new ones.
- The web front-end now provides functionality for hand-editing files.
- Under Windows the specified read-only prefix is case and path separator
insensitive.
- Elements defined through the CScout definition file are now considered
read-only.
- Workspace compiler: Correctly handle scoping in nested units.
- Workspace compiler: New readonly command for units other than files.
- A new option controls the depth of call graphs.
- Added functionality to interactively explore the tree of
a function's calling and called functions.
- The MIME type of SVG call graphs is now compatible Firefox's builtin
SVG viewer.
- Version 2.3 (2008/04/07)
-
- Each defined function is now associated with a comprehensive
set of metrics. These appear in the function's page, can be queried
against all functions, and are also summarized.
This is a list of maintained function metrics.
- Number of characters
- Number of comment characters
- Number of space characters
- Number of line comments
- Number of block comments
- Number of lines
- Maximum number of characters in a line
- Number of character strings
- Number of unprocessed lines
- Number of C preprocessor directives
- Number of processed C preprocessor conditionals (ifdef, if, elif)
- Number of defined C preprocessor function-like macros
- Number of defined C preprocessor object-like macros
- Number of preprocessed tokens
- Number of compiled tokens
- Number of statements or declarations
- Number of operators
- Number of unique operators
- Number of numeric constants
- Number of character literals
- Number of if statements
- Number of else clauses
- Number of switch statements
- Number of case labels
- Number of default labels
- Number of break statements
- Number of for statements
- Number of while statements
- Number of do statements
- Number of continue statements
- Number of goto statements
- Number of return statements
- Number of project-scope identifiers
- Number of file-scope (static) identifiers
- Number of macro identifiers
- Total number of object and object-like identifiers
- Number of unique project-scope identifiers
- Number of unique file-scope (static) identifiers
- Number of unique macro identifiers
- Number of unique object and object-like identifiers
- Number of global namespace occupants at function's top
- Number of parameters
- Maximum level of statement nesting
- Number of goto labels
- Fan-in (number of calling functions)
- Fan-out (number of called functions)
- Cyclomatic complexity (control statements)
- Extended cyclomatic complexity (includes branching operators)
- Maximum cyclomatic complexity (includes branching operators and all switch branches)
- Structure complexity (Henry and Kafura)
- Halstead volume
- Information flow metric (Henry and Selig)
- A number of file-related metrics have been added:
- Number of defined project-scope functions
- Number of defined file-scope (static) functions
- Number of defined project-scope variables
- Number of defined file-scope (static) variables
- Number of declared aggregate (struct/union) members
- Number of declared aggregate (struct/union) members
- Number of complete enumeration declarations
- Number of declared enumeration elements
- Number of processed C preprocessor conditionals (ifdef, if, elif)
- Number of defined C preprocessor function-like macros
- Number of defined C preprocessor object-like macros
- A new identifier query in the web interface lists function identifiers that should be made static.
- Newlines in string literals are now reported as errors.
-
Trigraph support now disabled by default. It can be explicitly enabled
through the new -3 switch.
- The contents of the columns BASEFILEID and DEFINERID of the SQL table
INCTRIGGERS were reversed.
Their contents now correspond to their definitions.
-
Correct support for initializer designators in conjunction with serial
initialization of aggregate elements.
- Correctly unify identifiers in function declarations that are
declared as static, and are subsequently defined without a storage
class specifier.
- Fixed a relatively rare error in the ordinal numbering of function name
elements in the FUNCTIONID table.
- The
__alignof__ gcc extension now also supports expressions,
in addition to types.
- On 64-bit architectures fields containing pointers are stored in a
BIGINT database field.
- MySQL dumps now start with SET SESSION sql_mode=NO_BACKSLASH_ESCAPES.
This prevents problems with the interpretation of backslashes stored in
strings and comments.
- Fixed syntax error when a
typedef followed a structure
initializer.
- Put number of unprocessed lines in the database and print it as a warning.
- Added support for Microsoft's __try __except __finally __leave extensions.
- Correctly parse a labeled statement appearing in the then
clause of an if statement.
This change tightens-up the use of the (deprecated) gcc extension
of allowing a label at the end of compound statement.
Following the change, only a single label is allowed.
- Type definitions in an
else block are now correctly
handled.
- An enumeration list can be empty (Microsoft extension).
- Correct processing of assembly line comments (starting with a ;)
inside Microsoft inline assembly blocks.
- Fix a potential crash when processing a project
under the
-r option.
- Version 2.2 (2006/09/29)
-
- An new accompanying command, csmake can automatically
generate CScout processing scripts by monitoring a project's
build process.
- Identical files in different locations are identified and presented in the file information page and through the file metrics.
- Facility to display the call path from one function to another.
- Identifiers occuring at the same place in identical files are considered to be the same.
- All query results are presented through a page selection interface.
- New option to display call graphs as GIF images avoiding the need for an SVG plugin for medium-sized graphs.
- The SQL backend supports four additional tables: STRINGS, COMMENTS, FILEPOS, FILECOPIES.
- Allow attribute declarations to follow labels (gcc extension).
- Support indirect
goto labels (gcc extension).
- Support (ANSI-style) nested function definitions (gcc extension).
- The macro expansion algorithm follows more closely
the C standard specification.
- Allow braces around scalar initializers (common extension).
- Macro calls in function arguments now get recorded as calls from the
enclosing function, rather than the function being called.
- Significantly faster file post-processing for the web and the SQL interface in large
projects.
- Array designators can be denoted through a range (gcc extension).
- Support for symbolic operands in gcc asm constructs.
- Allow
__typeof__ declarations to be preceded by type qualifiers.
- Correctly handle
__typeof__ of objects with a storage class within typedef declarations.
- The order of include file searching now matches more closely
that of other compilers: absolute file names are never searched in
the include file path, and non-system files are first searched relative
to the directory of the including file.
- Allow empty initializers and compound literals. (gcc extension)
- Support for the
alignof operator (gcc extension)
- The equals sign following an initializer designator is optional
(gcc extension).
- A declaration expression can be used as the first expression of a for
statement. (C99)
-
__typeof can also have as its argument a type name
- Support for designators in compound literals. (C99)
- Correctly handle preprocessing tokens with values close to UINT_MAX.
- Correctly evaluate preprocessor expressions involving a mixture of
signed and unsigned values.
- Correct handling of logical OR and logical AND preprocessor expressions.
- In query results of files sorted by a metric, groups of files with the same
value had only one member of the group displayed. This has now been fixed.
- Correct handling of implicit function declarations.
- Correct handling of character constants containg a
double-quote character when collecting metrics, database
dumping, and obfuscating.
- Function declarations appearing in multiple identical files now appear as a
single function.
-
Correct operation when the same project is encountered in the input
more than once.
- Correctly support the
index[array] construct.
- Correct typing of arithmetic involving arrays.
- Will not register function typedefs as function declarations.
- Don't issue an error message when a # appears in a skipped #error message
- Correct handling of C99 nested initialization designators.
- More consistent support for gcc keyword synonyms,
such as
__inline and __restrict__.
- Correct expansion of a macro following a token named after a
function-like macro.
- The supplied gcc definition files contain support for
the
__builtin_expect function.
- Correct operation of
typedefs involving a
__typeof construct.
- Will not report unneeded included files for (the rare case of)
compilation unit source files that are also included in other compilation units.
The unused included file report for such cases could incorrectly identify
files that were required for compilation as unneeded.
- Support for the C99
_Bool data type.
- Version 2.1 (2005/05/14)
-
-
The mixing of NULL with object pointers in conditional expressions
is now closer to the ANSI C rules.
- Support for the C99
restrict and inline keywords.
- An identifier declared with an extern storage-class specifier in
a scope in which a static declaration of that identifier is visible
will inherit that static declaration without an error.
- Allow struct/union declarations with only an empty declaration list (gcc extension).
- Correct preprocessing of floating-point numbers starting with a decimal point.
- Correctly handle the remainder operator in C preprocessor expressions.
- Allow absolute filename specifications in all #include directives.
- Report writable files that a given file must include.
- Facility to review and selectively deactivate identifier substitutions.
- A new option allows a regular expression to control the location where
modified files will be written.
- File, identifier, and function queries, display the number of elements
matched.
- Correct handling of the read-only pragma under Win32 platforms.
- Will not report (erroneous) file metrics for empty file sets.
- Accept gcc synonyms __typeof__, __label, and __attribute.
- Correctly handle structure initializations through typedefs that were
initially declared with an incomplete structure tag.
- Correctly calculate metrics in files with *-decorated block comments.
- Correctly deduce writable Unix files.
- Correctly identify as the same a function whose name is composed
through token concatenation, and occurs in two projects.
- Version 2.0 (2004/07/31)
-
- Monitor calls across functions and macros,
generating call graphs in various formats,
including hyperlinked SVGs.
A new category provides canned and customized queries on functions
and macros.
- Monitor parts of files not processed due to conditional
compilation.
The results are available as a new file metric category.
In addition, unprocessed parts can be identified in
source listings in a different color.
- Global options can be saved to a file, and loaded from it
on startup.
- File queries can now specify a sorting order for the file results.
- A new file query lists files with unprocessed lines, ordered
by the number of unprocessed lines.
- The presentation of file lists has been improved
- Will not report unused included files that are included with the
same directive that also includes used files.
This can happen when the same file is compiled multiple times with different
include paths or when a file is included by expanding a macro.
Problem spotted by Alexios Zavras in the FreeBSD kernel report.
- Allow
typedefed pointers and arrays to be further
qualified with e.g. const or volatile.
Problem reported by Walter Briscoe.
- The second argument of a conditional expression can be
omitted (gcc extension).
- Fix assertion generated when processing a yacc file without having
defined a yyparse function.
- Version 1.16 (2003/08/27)
-
- Declarations can be intermixed with statements (C99).
-
__typeof can have as its argument an expression
and not only an identifier.
- Support for C99 variable number of arguments preprocessor macros.
- Allow
case expression ranges (gcc extension).
- Recognise
__atribute__(__unused__) for determining which
identifiers should not be reported as unused (gcc extension).
- Command-line option to generate a wrongly scoped identifier and unused
include file and identifier warning report.
- Separate identifier attribute for enumeration constants.
This allows us stop incorrectly categorizing them as having global
(compilation unit) visibility.
- Error reporting format is now compatible with gcc.
- Dereferencing a function yields a function (common extension).
- Command-line option to process the file and exit.
- Document processing of the FreeBSD kernel.
- Correct typing of assembly-annotated declarators.
- Fixed assertion failure that could be caused when parts of concatenated
identifiers were no longer available (e.g. when processing files
with the
-m T option.)
- Correct handling of macro parameters that match other macros and
are followed by a concatenation operator (they were erroneously replaced).
- Add workaround for gcc
__builtin_va_copy in the provided
definition files.
- Corrected the handling of
main() in the example definition
files.
- Version 1.15 (2003/08/06)
-
- Plugged another memory leak.
All remaining memory leaks are caused by STL caching and should be of a
constant overhead.
- Version 1.14 (2003/08/03)
-
- Support locally declared labels (
__label__) (gcc extension).
- Allow statement labels without a following statement (gcc extension).
- Allow assignment to case expressions (common extension)
- Support C99 initialization designators.
- Support aggregate member initialization using the member: value syntax (gcc extension)
- Major memory leak plugged (a missing virtual destructor).
Cscout will now consume about 7 times less memory.
- In
#if and #elif directives expand macros
before processing the defined operator.
- Support the vararg preprocessor macro syntax (gcc extension).
- Allow empty member declarations in aggregates (gcc extension).
- Allow the declaration of empty structures or unions (gcc extension).
- An
__asm__ declaration can be used instead of a function's body (gcc).
- Correct typing of the conditional operator's return type
when one argument is a pointer and the other NULL.
- New -m option to specify identifiers to track.
Enormous memory savings at the expense of unsound operation.
- Display an error when a file does not end with a newline
- Allow yacc %union declaration to end with a ;
- Accept the #ident preprocessor directive (gcc extension)
- Fixed preprocessor bug:
multiple expansions of the same function-like macro inside another macro would
fail.
- Correctly handle concatenation of empty macro arguments.
- Correctly handle function prototypes inside old-style argument declarations.
- Do not replace strings or characters matching the name of a macro formal argument.
- Accept an empty translation unit (common extension).
- Adding a pointer to an integer now correctly yields a pointer
(adding an integer to a pointer already worked correctly)
- Support C99 compound literals.
- Correct typing of compound statements as expressions (gcc extension)
- Improved configuration definition files for the GNU C compiler
- Version 1.13 (2003/07/07)
-
- Handle GNU
__asm__ extension with a single operand
- -d options to cswc for specifying configuration directory
-
-p command-line option to specify the web server port
- Small corrections in the FreeBSD definition files.
- Intel IA-64 and AMD-64 support
- Version 1.12 (2003/06/23)
-
- New query: writable identifiers that should be made static
- URLs now work on 64-bit architectures
- Improved distribution format
- Sun SPARC-64 support
- Version 1.10 (2003/06/22)
-
- Allow GNU __asm__ statements with a single operand.
- GNU __asm__ statements can also appear at file scope.
- Accept older "name = {action statements}" yacc syntax.
- Can handle untyped yacc specifications.
- Correctly handle struct/union type specifier followed by a type qualifier.
- Small corrections in the supplied definition files.
- Version 1.9 (2003/06/19)
-
- Now distributed with ready-to-run example;
the awk source code.
No setup required, just unpack the distribution and run.
- Can now also process yacc files
- Fixed syntax error in workspace compiler source code
- Correctly documented -P switch as -E
- Added stdlib.h generic header
- Version 1.8 (2003/06/16)
- First public release
Contents
 Scout Main Page
Scout Main Page