code reading dds
 The Making of
The Making of
The book is written in 10.5 point Times-Roman, with code text set in 10.5 point
Lucida Sans Typewriter.
Code examples in the text appear in 8 point Lucida Sans
Typewriter, and in figures in 6 point Lucida Sans Typewriter.
Annotations are set in
8 point Helvetica in diagrams, and in 7 point Helvetica in the code listings.
I selected Lucida over Courier for the code listings, to avoid the problem
Courier fonts have with similar characters, for example the letter ell (l) and
the number one (1).
The text was written using the elvis, vim, and nvi
editors on several computers:
a Mitac 6020 running Microsoft Windows 98 and RedHat Linux 6.1;
a Toshiba Satellite 35 running Microsoft Windows 2000 and
RedHat Linux 7.1;
an IBM PC-340 running FreeBSD 4.1-RELEASE and later 4.6 and 4.8;
and a Digital DNARD (Shark) running NetBSD 1.5-ALPHA.
My impression is that the final production typesetting was performed in a Mac.
Text was processed using LaTeX (MiKTeX 1.11 and 2.1) and converted into
Postscript using dvips 5.86.
Bibliographic references were integrated with the text by
MiKTeX-BibTeX 1.7 (BibTeX 0.99c).
Diagrams were specified in a declarative, textual form
(using a custom Perl script for annotated code diagrams, and in some cases
using the UMLGraph tool I developed
during the process) and converted into
encapsulated Postscript by the GraphViz system dot program,
version 1.8.6
(see http://www.graphviz.org).
Screen dumps were converted into encapsulated Postscript using
programs from the outwit
and netpbm systems.
I also used GNU make to coordinate the build process,
and RCS to manage file revisions (544 revisions on last count):
$ for i in RCS/* ; do ; rlog $i ; done | grep '^revision' | wc -l
I wrote a number of Perl scripts to automate parts of the
production process.
Most were processed by Perl 5.6.1.
All the annotated code examples were specified textually with commented
code delimited by special character sequences.
A Perl script converted the annotated code into encapsulated Postscript.
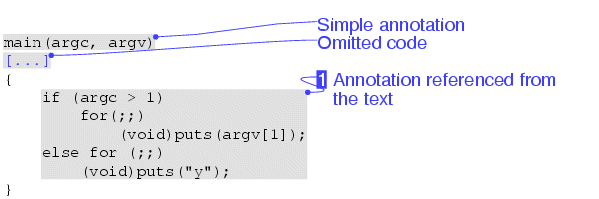
As an example, the code
$.
$(main(argc, argv)$)|Simple annotation|
$([...]$)|Omitted code|
{
$(if (argc > 1)
for(;;)
(void)puts(argv[1]);
else for (;;)
(void)puts("y");$)|{l:egano:txt}Annotation referenced from#the text|
}
would be converted into:
 Similarly, the code reading maxims, the book's index, and the source code
list were generated by LaTeX macro output post-processed by Perl scripts.
Another script converted the manuscript's initial British spelling into
American spelling through OLE calls to the Microsoft Word spell checker.
I also wrote a Perl script (now part of the GraphViz distribution)
to visualize a directory's structure as a dot diagram.
Its output was hand-tuned to create figures such as
the ones comparing
the NetBSD vs the Linux kernel source tree.
Writing a book can be a lot more enjoyable
if it involves some coding.
Similarly, the code reading maxims, the book's index, and the source code
list were generated by LaTeX macro output post-processed by Perl scripts.
Another script converted the manuscript's initial British spelling into
American spelling through OLE calls to the Microsoft Word spell checker.
I also wrote a Perl script (now part of the GraphViz distribution)
to visualize a directory's structure as a dot diagram.
Its output was hand-tuned to create figures such as
the ones comparing
the NetBSD vs the Linux kernel source tree.
Writing a book can be a lot more enjoyable
if it involves some coding.
The Typesetting Process
The book contains around 7000 interlinked elements
(more than
3600 subject index entries,
600 source code reference footnotes,
600 author index entries,
500 source code use pointers,
320 citations,
260 figure references,
230 bibliography elements,
200 chapter or section references,
190 chapters or sections,
120 marked figure annotations,
130 figures,
100 figure annotation references,
40 table references, and
20 tables).
Until the last possible moment these were automatically generated and
maintained;
during the last stages with heroic efforts from the typesetting team.
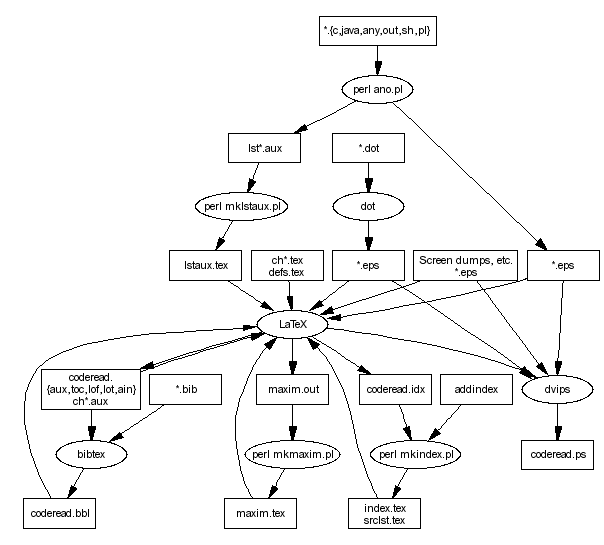
Figure 1: The manuscript production process
The process for typesetting the manuscript into Postscript
from the sources is outlined in Figure 1.
Some elements of the process were also described as
rules in a Makefile, but they were mainly there as
a mnemonic aid;
the Makefile never expressed all dependencies.
Although the process appears complex,
textual modifications
(as opposed to changes in the diagrams, the maxims,
the index, and the annotated code)
simply required re-running LaTeX on the main
file.
Commenting (or not) three lines at the top of main file
allowed me to create single or double-spaced output,
omit the revision identifier marks at the start of each chapter,
and process only a single chapter (specified later in the same file).
The four main categories of input were:
- Text files
- (ch*.tex) containing the text for each
chapter in LaTeX markup,
and a separate file defs.tex containing about 50 macro definitions
specific to this book.
These were processed by LaTeX to generate device independent
output and then by dvips to generate Postscript.
- Annotated code
- (*.c, *.java, *.any, *.sh, *.out ...)
These files contained source code with embedded annotations.
The annotations were bracketed in $( and $) pairs.
These were processed by the ano.pl Perl script to generate
encapsulated Postscript.
- Dot diagrams
- (*.dot) containing the descriptions
for all diagrams.
These were processed by the AT&T GraphViz dot program
to generate Postscript.
- Postscript diagrams
- (*.ps) various figures such as
screen dumps provided in encapsulated Postscript.
LaTeX, after processing the above files, generated a number of
auxiliary files, that we postprocessed to create
additional book elements.
For this reason LaTeX had to run multiple times to get the book
into a stable state.
The files generated for the second pass were:
- maxim.out
- A list of all maxims embedded in the chapters.
This was postprocessed by the Perl script mkmaxim.pl to
generate the maxim.tex file.
- coderead.aux, ch*.aux
-
These contained the page number of all labeled items and bibliography
references, and was
used for updating page references and the various tables.
In addition, the BibTeX program
read the aux files and the database of bibliography
files I maintained (*.bib),
to generate the coderead.bbl
bibliography that appears at the end of the book.
The author index was generated using the LaTeX authorindex package.
- coderead.toc,lot,lof
-
Table of contents, and list of tables and figures.
- coderead.idx
-
Index elements.
These, together with the list of hand-created list of
"see", and "see also"
entries in addindex was processed by the Perl script mkindex.pl to
generate the index index.tex.
- lst*.aux
-
The names of these files, generated by the code annotation script ano.pl,
were merged by the Perl script mklstaux.pl into a single file
lstaux.tex that was read by LaTeX to
obtain information on all labels used on the annotated code files.
Indexing
Being a control freak I decided early-on to handle indexing on my own,
marking indexed entries as I wrote the text.
I hoped this method would create a more useful and complete index.
As the manuscript evolved I would periodically generate an index
and peruse it to identify entries
that should be added, removed, or merged.
Thus, together with the manuscript an indexing crib sheet evolved;
I was using the crib sheet as a guide to create new index entries.
To improve the consistency of the index, I devised primary classifications
of terms, and used a special LaTeX macro to mark these up while I wrote the text.
I used the following term classification:
- Ada keyword
- C library
- keyword
- operator
- directory name
- editor command
- file name
- file extension
- file name
- identifier name
- Hungarian prefix
- Java class
- javadoc tag
- Java method
- Java package
- Java keyword
- Java interface
- Java operator
- Modula keyword
- pseudo-target
- Perl keyword
- C++ library
- Perl module
- Perl identifier
- regular expression
- revision-id tag
- troff command
- Texinfo command
- Unix-specific function
- Unix-specific identifier
- Win32 SDK
- X-Windows library
In retrospect I realize I should have also marked command names
(for example grep); I had to mark all these by hand close to the
end of the production process.
The End Result
In the end, not everything went as smoothly as I was expecting.
The typesetting team worked on a different architecture and operating
system, and some of the Perl scripts could not be easily executed in their
environment.
In addition, page layout needed to be hand-tweaked (for
example slightly adjusting line breaks and inter-line spacing)
to create optimal line and page breaks;
the auto-regenerated files would of course not retain those tweaks.
However, during most of the process I was able to substitute a lot
of boring and repetitive work with the intellectually simulating task
of automating the process.
I had followed a
similar avenue
when writing my PhD thesis, and I am also often implementing
custom languages and tools
when developing software
using domain-specific languages.
In all these cases, my feeling is that I cut the development effort by
at least 50%.
Book homepage | Author homepage


|
(C) Copyright 2000-2003 D. Spinellis.
May be freely uploaded by WWW viewers and similar programs.
All other rights reserved.
Last modified: 2003.10.24
|