- Ορισμός του τύπου της συνδεδεμένης λίστας χαρακτήρων
- Επιστρέφεται μια άδεια συνδεδεμένη λίστα
-
char_list char_list_new(void); - Επιστρέφεται μια συνδεδεμένη λίστα με το στοιχείο c στην αρχή της
-
char_list char_list_add(char_list l, char c); - Καλεί τη συνάρτηση process για κάθε στοιχείο της λίστας
-
void char_list_traverse(char_list l, void (*process)(char c)); - Επιστρέφεται αληθές αν η λίστα είναι κενή
-
int char_list_isempty(char_list l); - Διαγράφει όλα τα στοιχεία της λίστας l
-
void char_list_delete(char_list l);
-
Παράδειγμα:
L I V E . E V I L
Ουρές
Ορισμός
- Η ουρά (queue) είναι μια γραμμική διάταξη στοιχείων στην οποία κάθε πρόσθεση στοιχείων γίνεται στο τέλος της και κάθε αφαίρεση στοιχείων γίνεται από την αρχή της.
- Η μέθοδος φύλαξης που υλοποιεί η ουρά λέγεται FIFO (First In First Out).
- Συνδιασμός ουράς και στοίβας (επιτρέπει την εισαγωγή και εξαγωγή και από τα δύο άκρα) καλείται ουρά με δύο άκρα (dequeue (double ended queue)).
Υλοποίηση στη μνήμη
- Τα στοιχεία φυλάσσονται σε διαδοχικές θέσεις.
- Ένας δείκτης ή καταχωρητής δείχνει την αρχή της ουράς.
- Ένας δείκτης ή καταχωρητής δείχνει το τέλος της ουράς.
- Το μέγεθος της ουράς ορίζεται με σύμβαση.
- Μπορούμε να ορίσουμε ότι η ουρά είναι άδεια όταν η αρχή είναι ίδια με το τέλος.
- Όταν η αρχή ή το τέλος φτάσουν το μέγεθος της ουράς πρέπει να επιστρέψουν στην αρχή της (κυκλική ουρά).
Υλοποίηση σε C
Υλοποίηση με πίνακα
- Η ουρά μπορεί να υλοποιηθεί με τη χρήση ενός πίνακα.
- Δύο ξεχωριστές μεταβλητές δείχνουν την αρχή και το τέλος της ουράς.
- Απαραίτητοι οι έλεγχοι για υπερχείλιση και υποχείλιση.
- Ο πίνακας (ή δείκτης σε αυτόν) καθώς και οι μεταβλητές της αρχής και του τέλους μπορούν να ομαδοποιηθούν σε μια εγγραφή.
Παράδειγμα 1
struct s_int_queue {
int values[20]; /* Array of values */
int head; /* Head of queue (values[head]) */
int tail; /* Tail of queue (values[tail]) */
};
Παράδειγμα 2
struct s_int_queue {
int *values; /* Allocated array of values */
int values_size; /* Number of values allocated */
int head; /* Head of queue (values[head]) */
int tail; /* Tail of queue (values[tail]) */
};
Παράδειγμα 3
struct s_int_queue {
int *values_start; /* Start of allocated array of values */
int *values_end; /* End of allocated array of values */
int *head; /* Head of queue */
int *tail; /* Tail of queue */
};
Υλοποίηση με συνδεδεμένη λίστα
- Η ουρά μπορεί να υλοποιηθεί με τη μιας συνδεδεμένης λίστας
- Δύο ξεχωριστές μεταβλητές δείχνουν τα στοιχεία της λίστας που αποτελούν την αρχή και το τέλος της ουράς. Η αρχή της ουράς (queue head) (το σημείο από το οποίο αφαιρούνται τα στοιχεία) είναι η αρχή της λίστας, το τέλος της ουράς (queue tail) είναι το τέλος της λίστας.
- Οι δείκτες στην αρχή το τέλος της λίστας μπορούν να ομαδοποιηθούν σε μια εγγραφή.
Παράδειγμα
struct s_int_list {
int val;
struct s_int_list *next;
};
struct s_int_queue {
struct s_int_list *head;
struct s_int_list *tail;
};
/* Add an element to the queue */
void
int_queue_put(struct s_int_queue *q, int v)
{
struct s_int_list *p;
p = (struct s_int_list *)malloc(sizeof(struct s_int_list));
p->next = NULL;
p->val = v;
if (q->tail != NULL)
q->tail->next = p; /* Add element to queue tail */
else
q->head = p; /* Special case for empty queue */
q->tail = p;
}
/* Remove and return an element from a non-empty queue */
int
int_queue_get(struct s_int_queue *q)
{
int v;
struct s_int_list *tmp;
assert(q->head != NULL);
v = q->head->val;
if (q->head->next == NULL)
q->tail = NULL; /* Special case for empty queue */
tmp = q->head->next;
free(q->head);
q->head = tmp;
return (v);
}
Αφηρημένος τύπος
- Ορισμός του τύπου της ουράς λίστας ακεραίων
-
typedef struct s_int_queue *int_queue; - Επιστρέφει μια άδεια ουρά
-
int_queue new_int_queue(void); - Το στοιχείο i εισάγεται στο τέλος της ουράς
-
void put_int_queue(int_queue q, int i); - Το στοιχείο από την αρχή της μη κενής ουράς αφαιρείται και επιστρέφεται
-
int get_int_queue(int_queue q); - Επιστρέφεται αληθές αν η ουρά είναι κενή
-
int isempty_int_queue(int_queue q); - Διαγράφει την ουρά
-
void delete_int_queue(int_queue q);
Εφαρμογές
- Υλοποίηση ουράς προτεραιότητας
- Επίσκεψη κλάδων δέντρου κατά βάθος
- Αναγνώριση συμβολοσειρών
- Εύρεση στοιχείων σε γράφο με ανίχνευση κατά πλάτος
Βιβλιογραφία
- Χρήστος Κοίλιας
Δομές Δεδομένων και Οργανώσεις Αρχείων. σ. 56-62, 72-75
Εκδόσεις Νέων Τεχνολογιών, 1993.
- Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman. Data Structures and Algorithms, pages 56–60. Addison-Wesley, 1983.
- Donald E. Knuth. The Art of Computer Programming, volume 1 / Fundamental Algorithms, pages 235–241. Addison-Wesley, second edition, 1973.
- Robert Sedgewick. Algorithms in C, pages 30–31, 300–301, 431, 457. Addison-Wesley, 1990.
Ασκήσεις
Άσκηση 4
- Να υλοποιηθεί σε C ο αφηρημένος τύπος της ουράς ακεραίων
σύμφωνα με τις παρακάτω συναρτήσεις:
- Επιστρέφει μια άδεια ουρά
-
int_queue new_int_queue(void); - Το στοιχείο i εισάγεται στο τέλος της ουράς
-
void put_int_queue(int_queue q, int i); - Το στοιχείο από την αρχή της μη κενής ουράς αφαιρείται και επιστρέφεται
-
int get_int_queue(int_queue q); - Επιστρέφεται αληθές αν η ουρά είναι κενή
-
int isempty_int_queue(int_queue q);
- Με βάση τον αφηρημένο αυτό τύπο και μονοτονικά αυξανόμενη μεταβλητή
να υλοποιηθεί πρόγραμμα το οποίο να υλοποιεί ουρά εξυπηρέτησης πελατών
ως εξής:
- Όταν εισάγεται ο χαρακτήρας I (In) το πρόγραμμα τυπώνει τον αριθμό προτεραιότητας του νέου πελάτη.
- Όταν εισάγεται ο χαρακτήρας O (Out) το πρόγραμμα τυπώνει τον αριθμό προτεραιότητας του επόμενου πελάτη που θα εξυπηρετηθεί.
I 1 I 2 I 3 O 1 I 4 O 2 ...
Δένδρα
Ορισμοί
- Ένα δένδρο (tree) είναι ένα σύνολο από
κόμβους (nodes) που ενώνονται με
ακμές (edges) και εκπληρεί την παρακάτω
ιδιότητα:
- Αν ορίσουμε ως μονοπάτι (path) ένα σύνολο κόμβων ενωμένων με ακμές και ένα συγκεκριμένο κόμβο ως ρίζα (root) του δέδρου τότε κάθε άλλος κόμβος ενώνεται με τη ρίζα με ένα και μόνο ένα μονοπάτι.
- Αν παραστήσουμε το δένδρο με τη ρίζα προς τα πάνω τότε κάθε κόμβος - εκτός από τη ρίζα - θα έχει ακριβώς ένα κόμβο από πάνω του ο οποίος και ονομάζεται πατέρας (father) του.
- Αντίστοιχα οι κόμβοι που βρίσκονται κάτω από τον πατέρα ονομάζονται παιδιά (children) του.
- Βαθμός (Degree) ενός κόμβου ορίζεται ως ο αριθμός των παιδιών του.
- Βαθμός ενός δένδρου είναι ο μεγιστός βαθμός όλων των κόμβων του.
- Κόμβοι χωρίς παιδιά ονομάζονται τερματικοί κόμβοι (terminal nodes) ή εξωτερικοί κόμβοι (external nodes) ή φύλλα (leaves).
- Κόμβοι με παιδιά ονομάζονται μη τερματικοί κόμβοι (non-terminal nodes) ή εσωτερικοί κόμβοι (internal nodes) ή κλαδιά (branches).
- Επίπεδο (Level) ενός κόμβου ορίζεται ως ο αριθμός των κόμβων στο μονοπάτι από τον κόμβο μέχρι τη ρίζα.
- Το μέγιστο επίπεδο των κόμβων του δδένδρου ονομάζεται βάθος (depth) ή ύψος (height) του δένδρου.
- Υπόδενδρο (Subtree) είναι ένα δένδρο το οποίο σχηματίζεται έχοντας ως ρίζα κάποιον άλλο κόμβο.
- Δάσος (Forest) είναι ένα σύνολο από δένδρα και σχηματίζεται αν κόψουμε ένα δένδρο σε έναν κόμβο με παιδιά.
- Ένα δένδρο του οποίου κάθε κόμβος έχει δύο το πολύ ακμές ονομάζεται δυαδικό δένδρο (binary tree).
Ιδιότητες
- Δύο κόμβοι ενώνονται από ένα ακριβώς μονοπάτι
- Ένα δένδρο με Ν κόμβους έχει Ν - 1 ακμές
- Ένα δένδρο βαθμού d και ύψους h μπορεί να έχει sum(0, h-1, d^i) κόμβους.
- Ένα πλήρες δυαδικό δένδρο ύψους h θα έχει 2^h - 1 κόμβους.
- Ένα πλήρες δυαδικό δένδρο με n κόμβους θα έχει log n ύψος.
Υλοποίηση σε C
- Οι ακμές υλοποιούνται με τη χρήση δεικτών.
- Τα στοιχεία ομαδοποιούνται με τους δείκτες ως μια εγγραφή.
- Οι εξωτερικοί κόμβοι συμβολίζονται με την ειδική τιμή δείκτη
NULL. - Μνήμη για κάθε στοιχείο αποκτούμε με τη χρήση της διαδικασίας
malloc.
#include <stdlib.h>
/*
* Declare a binary tree of integers
*/
struct s_tree {
int val;
struct s_tree *left, *right;
};
main()
{
struct s_tree *tree, *node;
node = (struct s_tree *)malloc(sizeof(struct s_tree));
node->val = 5;
node->left = node->right = NULL;
tree = node;
node = (struct s_tree *)malloc(sizeof(struct s_tree));
node->val = 12;
node->left = node->right = NULL;
tree->right = node;
}
Δένδρα αναζήτησης
- Διατεταγμένο είναι ένα δένδρο στο οποίο η διάταξη των κόμβων έχει σημασία
- Σε ένα δυαδικό δένδρο αναζήτησης η τιμή κάθε κόμβου είναι μεγαλύτερη ή ίση από τις τιμές των κόμβων του αριστερού υποδένδρου και μικρότερη ή ίση από τις τιμές των κόμβων του δεξιού υποδένδρου.
- Σε ένα τέτοιο δένδρο η αναζήτηση για μια τιμή απαιτεί τόσες συγκρίσεις όσο είναι και το μέγιστο μήκος μονοπατιού.
Παράδειγμα αναζήτησης
/*
* Search for the integer i in the ordered binary tree t
* If found return its node; otherwise return NULL
*/
struct s_tree
search(struct s_tree *t, int i)
{
if (t == NULL)
return (NULL);
else if (t->val == i)
return (t);
else if (i < t->val)
return (search(t->left, i));
else
return (search(t->right, i));
}
Διάσχιση δένδρων
Η διάσχιση ενός δένδρου μπορεί να γίνει με τους παρακάτω τρόπους ανάλογα με τη σειρά επίσκεψης των κόμβων:- Προδιαταγμένη διάσχιση (preorder traversal)
-
- επίσκεψη της ρίζας
- επίσκεψη του αριστερού υποδένδρου
- επίσκεψη του δεξιού υποδένδρου
- Μεταδιαταγμένη διάσχιση (postorder traversal)
-
- επίσκεψη του αριστερού υποδένδρου
- επίσκεψη του δεξιού υποδένδρου
- επίσκεψη της ρίζας
- Ενδοδιαταγμένη διάσχιση (inorder traversal)
-
- επίσκεψη του αριστερού υποδένδρου
- επίσκεψη της ρίζας
- επίσκεψη του δεξιού υποδένδρου
- Επιπεδοδιαταγμένη διάσχιση (level order traversal)
-
- επίσκεψη των κόμβων από πάνω προς τα κάτω
Οι αντίστοιχες διασχίσεις διάσχισης υλοποιούνται αναδρομικά ως εξής:
- Προδιαταγμένη διάσχιση
-
void visit(struct s_tree *t, void(*process)(int val)) { if (t == NULL) return; process(t->val); visit(t->left); visit(t->right); } - Μεταδιαταγμένη διάσχιση
-
void visit(struct s_tree *t, void(*process)(int val)) { if (t == NULL) return; visit(t->left); visit(t->right); process(t->val); } - Ενδοδιαταγμένη διάσχιση
-
void visit(struct s_tree *t, void(*process)(int val)) { if (t == NULL) return; visit(t->left); process(t->val); visit(t->right); } - Επιπεδοδιαταγμένη διάσχιση
-
/* * Process all nodes at taget level given a tree t and its current depth level * Return the number of nodes processed * (Used by the visit function) */ static int visit_level(struct s_tree *t, int current_level, int target_level, void(*process)(int val)) { if (t == NULL || current_level > target_level) return (0); else if (current_level == target_level) { process(t->val); return (1); } else return ( visit_level(t->left, current_level + 1, target_level, process) + visit_level(t->left, current_level + 1, target_level, process)); } void visit(struct s_tree *t, void(*process)(int val)) { int i = 0; int nodes_processed; do { nodes_processed = visit_level(t, 0, i, process); i++; } while (nodes_processed > 0); }
Εφαρμογές
- Υλοποίηση δομών αναζήτησης
- Παράσταση συντακτικών δομών (γλώσσες προγραμματισμού και φυσικές γλώσσες)
- Παράσταση ιεραρχικών δομών (κατανεμημένες βάσεις, μοντελοποίηση)
Βιβλιογραφία
- Χρήστος Κοίλιας
Δομές Δεδομένων και Οργανώσεις Αρχείων. σ. 81-97
Εκδόσεις Νέων Τεχνολογιών, 1993.
- Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman. Data Structures and Algorithms, pages 75–106. Addison-Wesley, 1983.
- Donald E. Knuth. The Art of Computer Programming, volume 1 / Fundamental Algorithms, pages 305–422. Addison-Wesley, second edition, 1973.
- Robert Sedgewick. Algorithms in C, pages 35–49. Addison-Wesley, 1990.
- Niklaus Wirth. Algorithms and Data Structures, pages 196–217. Prentice–Hall, 1986.
Ασκήσεις
Άσκηση 5
- Να υλοποιηθεί σε C πρόγραμμα το οποίο με τη
χρήση διατεταγμένου δυαδικού δένδρου διαβάζει από το
χρήστη μια σειρά από ονόματα μέχρι να τελειώσει το
αρχείο που διαβάζει (π.χ. ο χρήστης πληκτρολογήσει CTRL-Z)
και τα εκτυπώνει με αλφαβητική σειρά.
Παράδειγμα:
Verdi Strauss Mozart Wagner Adams Gounod Bellini Gauss Bizet Donizetti Mascagni Puccini Rossini ^Z Adams Bellini Bizet Donizetti Gauss Gounod Mascagni Mozart Puccini Rossini Strauss Verdi Wagner
Σημείωση 1: Η συνάρτηση strcmp συγκρίνει αλφαβητικά δύο συμβολοσειρές (α, β), και επιστρέφει ανάλογα -1 (α < β), 0 (α = β), ή 1 (α > β). Ορίζεται στην string.h.Σημείωση 2: Ανάγνωση των συμβολοσειρών μέχρι το τέλος του αρχείου, αντιγραφή τους σε χώρο που έχει επιστραφεί από τη malloc, και αποθήκευσή του δείκτη σε μεταβλητή p τύπου char * μπορεί να γίνει ως εξής:
char buff[80]; while (fgets(buff, sizeof(buff), stdin)) { p = strdup(buff); ... }Η δήλωση της strdup βρίσκεται στην επικεφαλίδα string.h.Σημείωση 3: Ο ορισμός των παρακάτω δύο συναρτήσεων μπορεί να σας βοηθήσει στη δομή του προγράμματος:
static void add_tree(struct s_btree **t, char *name); static void print_tree(struct s_btree *t);
Γράφοι
Ορισμοί
- Ένας γράφος (graph) είναι ένα σύνολο από κόμβους που ενώνονται με ακμές.
- Ο γράφος ορίζεται πλήρως από τους κόμβους και τη συνδεσμολογία τους.
- Αν οι ακμές είναι προσανατολισμένες (ορίζονται δηλαδή από διατεταγμένα ζεύγη κόμβων) τότε ο γράφος λέγεται κατευθυνόμενος (directed).
- Αν οι ακμές δεν είναι προσανατολισμένες (ορίζονται δηλαδή από μη διατεταγμένα ζεύγη κόμβων) τότε ο γράφος λέγεται μη κατευθυνόμενος (undirected).
- Αν οι ακμές είναι συνδεδεμένς με κάποια αξία (βάρος) τότε ο γράφος λέγεται σταθμισμένος (weighted).
- Πλήρης (Complete) ορίζεται ο μη κατευθυνόμενος γράφος που περιέχει ακμές που ενώνουν κάθε ζεύγος κόμβων.
- Αραιός καλείται ο γράφος που περιέχει λίγες σχετικά ακμές (λ.χ. για ν κόμβους ο αριθμός των ακμών < ν log ν).
- Πυκνός (Dense) καλείται ο γράφος από τον οποίο απουσιάζουν λίγες σχετικά ακμές.
Παράσταση
Ένας γράφος μπορεί εύκολα να παρασταθεί με δύο διαφορετικούς τρόπους: Και οι δύο τρόποι προϋποθέτουν ένα μονοσήμαντο σύστημα αρίθμησης των κόμβων.Πίνακας γειτνίασης
Σε έναν γράφο με ν κόμβους ο πίνακας ν*ν γειτνίασης περιέχει 1 στις θέσεις (κ,λ) όπου υπάρχει ακμή από τον κόμβο κ στον κόμβο λ.Παράδειγμα για γράφο 100 κόμβων:
/*
* Adjacency matrix for a graph of 100 nodes
*/
static int adjmatrix[100][100];
main()
{
int a, b;
/* Read edges and connect them */
while (scanf(%d %d", &a, &b) == 2)
adjmatrix[a][b] = adjmatrix[b][a] = 1;
}
Λίστα γειτνίασης
Κάθε κόμβος συσχετίζεται με μια συνδεδεμένη λίστα γειτνίασης η οποία περιέχει τα ονόματα των άλλων κόμβων με τους οποίους συνδέεται ο συγκεκριμένος κόμβος. Οι λίστες για όλους τους κόμβους ν μπορούν να ξεκινούν από έναν μονοδιάστατο πίνακα μήκους ν ή από μια άλλη συνδεδεμένη λίστα.Παράδειγμα για γράφο 10 κόμβων:
#include <stdlib.h>
#include <stdio.h>
/*
* Adjacency list for a graph of 10 nodes
*/
struct s_adjlist {
int node;
struct s_adjlist *next;
};
static struct s_adjlist *adj[10];
main()
{
int a, b;
struct s_adjlist *p;
int i;
/* Read edges and connect them */
while (scanf("%d %d", &a, &b) == 2) {
p = (struct s_adjlist *)malloc(sizeof(struct s_adjlist));
p->node = b;
p->next = adj[a];
adj[a] = p;
p = (struct s_adjlist *)malloc(sizeof(struct s_adjlist));
p->node = a;
p->next = adj[b];
adj[b] = p;
}
}
Πρόσθετοι ορισμοί
- Διαδρομή (path) καλείται μια διάταξη κόμβων οι οποίοι ενώνονται με ακμές.
- Απλή διαδρομή (simple path) καλείται η παραπάνω διάταξη όταν κάθε κόμβος εμφανίζεται μια μόνο φορά.
- Κύκλος (cycle) καλείται η διαδρομή δύο ή περισσοτέρων κόμβων που καταλήγει στον κόμβο αρχής.
- Απόσταση (distance) μεταξύ δύο κόμβων καλείται το μήκος της συντομότερης διαδρομής που τους ενώνει.
- Διαδρομή Euler (Euler path) καλείται η διαδρομή ή οποία περνάει από όλες τις ακμές του γράφου ακριβώς μια φορά.
- Διαδρομή Hamilton (Hamilton path) καλείται η διαδρομή ή οποία περνάει από όλους τους κόμβους του γράφου ακριβώς μια φορά.
- Γράφοι που περιέχουν τις παραπάνω διαδρομές ονομάζονται αντίστοιχα.
- Συνεκτικός (connected) ονομάζεται ο γράφος για τον οποίο υπάρχει διαδρομή από κάθε κόμβο σε κάθε άλλο κόμβο.
- Βαθμός ενός κόμβου σε έναν μη κατευθυνόμενο γράφο καλείται ο αριθμός των συνδεδεμένων με αυτόν ακμών.
- Βαθμός εισόδου (in-degree) σε έναν κατευθυνόμενο γράφο καλείται ο αριθμός των ακμών που καταλήγουν σε αυτόν.
- Βαθμός εξόδου (out-degree) σε έναν κατευθυνόμενο γράφο καλείται ο αριθμός των ακμών που ξεκινούν από αυτόν.
- Υπογράφος (subgraph) Β ενός γράφου Α καλείται ο γράφος του οποίου όλες οι ακμές και οι κόμβοι περιέχονται στον Α.
- Δένδρο σκελετός (spanning tree) ενός γράφου καλείται ο υπογράφος που περιέχει όλους του κόμβους αλλά μόνο όσες ακμές απαιτούνται για να σχηματιστεί δένδρο.
Προτάσεις σε συνεκτικούς μη κυκλικούς γράφους
Οι παρακάτω προτάσεις είναι ισοδύναμες για πεπερασμένους γράφους με ν > 0 κόμβους:- Ο γράφος Γ είναι συνεκτικός και μη κυκλικός.
- Αν διαγραφεί οποιαδήποτε ακμή ο γράφος θα πάψει να είναι συνεκτικός.
- Δύο διαφορετικοί κόμβοι συνδέονται από μια και μόνο μια απλή διαδρομή.
- Ο γράφος είναι μη κυκλικός και περιέχει ν - 1 ακμές.
- Ο γράφος είναι συνεκτικός και περιέχει ν - 1 ακμές.
Ψάξιμο κατά βάθος
Για να επισκευθούμε όλους τους κόμβους ενός γράφου με ν κόμβους χρειαζόμαστε έναν πίνακα λογικών μεταβλητών μιας διάστασης και μήκους ν ο οποίος περιέχει την τιμή "αληθές" για τους κόμβους τους οποίους έχουμε επισκευθεί. Η συστηματική επίσκεψη όλων των κόμβων γίνεται σύμφωνα με τα παρακάτω βήματα:- Φυλάμε την τιμή "ψευδές" στον πίνακα επισκέψεων.
- Επισκεπτόμαστε όλους τους κόμβους που δεν έχουμε επισκευτεί.
- Σημειώνουμε στον πίνακα ότι έχουμε επισκευθεί τον κόμβο.
- Επισκεπτόμαστε όλους τους συνδεδεμένους κόμβους που δεν έχουμε επισκευθεί.
#include <stdlib.h>
#include <stdio.h>
/*
* Adjacency list for a graph of 10 nodes
*/
struct s_adjlist {
int node;
struct s_adjlist *next;
};
static struct s_adjlist *adj[10];
static int visited[10];
/*
* Visit the nodes starting from node printing their value using
* depth first search
*/
static void
visit(int node)
{
struct s_adjlist *p;
visited[node] = 1;
printf("%d\n", node);
for (p = adj[node]; p != NULL; p = p->next)
if (!visited[p->node])
visit(p->node);
}
main()
{
int a, b;
struct s_adjlist *p;
int i;
/* Read edges and connect them */
while (scanf("%d %d", &a, &b) == 2) {
p = (struct s_adjlist *)malloc(sizeof(struct s_adjlist));
p->node = b;
p->next = adj[a];
adj[a] = p;
p = (struct s_adjlist *)malloc(sizeof(struct s_adjlist));
p->node = a;
p->next = adj[b];
adj[b] = p;
}
/* Depth first search/print of the graph */
for (i = 0; i < 10; i++)
visited[i] = 0;
for (i = 0; i < 10; i++)
if (!visited[i])
visit(i);
}
Αν το πρόγραμμα διαβάσει το γράφο:
2 3 3 8 8 6 4 9θα τυπώσει την παρακάτω σειρά επίσκεψης:
0 1 2 3 8 6 4 9 5 7
Εφαρμογές
- Παράσταση διασυνδέσεων ανάμεσα σε αντικείμενα
- Ταξίδια ανάμεσα σε πόλεις
- Συνδέσεις υπολογιστών σε δίκτυο
- Συνδέσεις σελίδων σε υπερκείμενο
- Ανθρώπινες σχέσεις
- Παράσταση ηλεκτρονικών διαγραμμάτων
- Προγραμματισμός εργασιών
Βιβλιογραφία
- Χρήστος Κοίλιας
Δομές Δεδομένων και Οργανώσεις Αρχείων. σ. 98-105
Εκδόσεις Νέων Τεχνολογιών, 1993.
- Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman. The Design and Analysis of Computer Algorithms, pages 172–309. Addison-Wesley, 1974.
- Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman. Data Structures and Algorithms, pages 198–252. Addison-Wesley, 1983.
- Donald E. Knuth. The Art of Computer Programming, volume 1 / Fundamental Algorithms, pages 362–378. Addison-Wesley, second edition, 1973.
- Robert Sedgewick. Algorithms in C, pages 415–508. Addison-Wesley, 1990.
Αναζήτηση και ταξινόμηση
Ταξινόμηση
- Οι αλγόριθμοι ταξινόμησης (sorting algorithms) θέτουν τα στοιχεία μιας δομής δεδομένων σε σειρά σύμφωνα με μια ορισμένη σχέση διάταξης.
- Αν τα στοιχεία είναι οργανωμένα σε εγγραφές και κάθε μια από αυτές απαρτίζεται από πεδία τότε το πεδίο με βάση το οποίο γίνεται η ταξινόμηση ονομάζεται κλειδί (key) της ταξινόμησης.
- Το κόστος μιας ταξινόμησης εκφράζεται ανάλογα με τον αριθμό συγκρίσεων και μετακινήσεων που απαιτούνται κατ' ελάχιστο, μέγιστο και κατά μέσο όρο.
- Συχνά για να αποφευχθεί το κόστος των μετακινήσεων αντί για τα στοιχεία, ταξινομήται ένας πίνακας με δείκτες στα αντίστοιχα στοιχεία.
Ταξινόμηση με παρεμβολή
- Στη ταξινόμηση με παρεμβολή (insertion sort) τα
στοιχεία χωρίζονται σε:
- αυτά τα οποία έχουν ταξινομηθεί,
- αυτό τα οποία θα ταξινομηθεί, και
- αυτά τα οποία δεν έχουν ταξινομηθεί.
- Σε κάθε βήμα το στοιχείο που πρέπει να ταξινομηθεί εισάγεται στη σωστή θέση αυτών που έχουν ταξινομηθεί.
- Για την εύρεση του σημείου εισαγωγής μπορεί να χρησιμοποιηθεί και ο αλγόριθμος της δυαδικής αναζήτησης.
Ταξινόμηση με επιλογή
- Στη ταξινόμηση με επιλογή (selection sort) τα
στοιχεία χωρίζονται σε:
- αυτά τα οποία έχουν ταξινομηθεί,
- αυτά τα οποία δεν έχουν ταξινομηθεί.
- Σε κάθε βήμα επιλέγεται το ελάχιστο στοιχείο από αυτά τα οποία δεν έχουν ταξινομηθεί και εισάγεται στο τέλος των στοιχείων που έχουν ταξινομηθεί.
Ταξινόμηση με αντιμετάθεση
- Στη ταξινόμηση με αντιμετάθεση (exchange sort) τα στοιχεία ταξινομούνται με διαδοχική αντιμετάθεση ζευγών που δεν ακολουθούν τη διάταξη της ταξινόμησης.
- Ο αλγόριθμος μπορεί να βελιτωθεί εναλλάσσοντας σε κάθε πέρασμα τη φορά του ελέγχου.
- Στην πρώτη περίπτωση ονομάζεται bubble sort (ταξινόμηση φυσαλίδας), στη δεύτερη shake sort.
Ταξινόμηση με διαμερισμό και αντιμετάθεση
- Στην ταξινόμηση με διαμερισμό (partition exchange sort) (ή γρήγορη ταξινόμηση (quick sort)) επιλέγεται ένα στοιχείο του πίνακα και τα υπόλοιπα στοιχεία μοιράζονται σε δύο υποπίνακες ανάλογα με τη σχέση τους με το στοιχείο αυτό.
- Στη συνέχεια ο αλγόριθμος καλείται αναδρομικά για τους δύο υποπίνακες.
- Η βιβλιοθήκη της C υλοποιεί τον αλγόριθμο αυτό στη συνάρτηση qsort:
#include <stdlib.h> void qsort(void *base, size_t num, size_t width, int (*compare)(const void *elem1, const void *elem2));
- Η συνάρτηση ταξινομεί έναν πίνακα δεδομένων με βάση μια συνάρτηση σύγκρισης.
- Η συνάρτηση έχει τις παρακάτω παραμέτρους:
- base
- Δείκτης στην αρχή του πίνακα των δεδομένων που πρέπει να ταξινομηθούν.
- num
- Αριθμός των δεδομένων που πρέπει να ταξινομηθούν.
- width
- Το μέγεθος κάθε στοιχείου του πίνακα (π.χ. sizeof(int), sizeof(struct s_elem *)).
- compare
- Δείκτης σε συνάρτηση που συγκρίνει δύο στοιχεία με βάση δείκτες σε αυτά.
Η συνάρτηση compare πρέπει να επιστρέφει τις παρακάτω τιμές:
- < 0
- αν το elem1 < elem2,
- 0
- αν το elem1 == elem2 και
- > 0
- αν το elem1 > elem2.
Παράδειγμα
Το παρακάτω παράδειγμα ταξινομεί το πίνακα ακεραίων ivals και τυπώνει το αποτέλεσμα:
#include <stdlib.h>
#include <stdio.h>
/*
* Integer compare function (passed to qsort)
*/
static int
icmp(const void *arg1, const void *arg2)
{
return (*(int *)arg1 - *(int *)arg2);
}
main()
{
int ivals[] = {100, 5, 6, 2, 8, 3, 45, 23};
int i;
qsort((void *)ivals, sizeof(ivals) / sizeof(int), sizeof(int), icmp);
for (i = 0; i < sizeof(ivals) / sizeof(int); i++)
printf("%d\n", ivals[i]);
}
Αναζήτηση
- Οι αλγόριθμοι αναζήτησης (searching algorithms) επιτρέπουν την εύρεση ενός στοιχείου σε μια δομή δεδομένων με βάση ένα χαρακτηριστικό του.
- Αν τα στοιχεία είναι οργανωμένα σε εγγραφές και κάθε μια από αυτές απαρτίζεται από πεδία τότε το πεδίο με βάση το οποίο γίνεται η αναζήτηση ονομάζεται κλειδί της αναζήτησης.
- Το κόστος μιας αναζήτησης εκφράζεται ανάλογα με τον αριθμό συγκρίσεων που απαιτούνται κατά μέσο όρο για την εύρεση της αναζητούμενης εγγραφής.
Σειριακή αναζήτηση
- Στη σειριακή αναζήτηση (sequential search) η εύρεση της εγγραφής στη δομή που επιτρέπει τέτοιου είδους πρόσβαση (π.χ. πίνακα ή συνδεδεμένη λίστα) γίνεται ελέγχοντας μια-μια τις εγγραφές από την αρχή μέχρι το τέλος της δομής.
- Αν η δομή έχει Ν στοιχεία θα απαιτηθούν κατά μέσο όρο N / 2 συγκρίσεις.
- Το παρακάτω παράδειγμα αναζητά έναν ακέραιο σε μια συνδεδεμένη λίστα
ακεραίων και επιστρέφει δείκτη στη δομή που τον περιέχει ή NULL αν η
λίστα δεν περιέχει τον ακέραιο αυτό:
#include <stdlib.h> struct s_ilist { int i; struct s_ilist *next; }; /* * Search for the integer i in the linked list p. * Return a pointer to the first element containing the integer * if found; NULL if the integer is not in the list. */ struct s_ilist * isearch(struct s_ilist *p, int i) { for (; p != NULL; p = p->next) if (p->i == i) return (p); return (NULL); }
Δυαδική αναζήτηση
- Στη δυαδική αναζήτηση (binary search) η εύρεση της εγγραφής στον ταξινομημένο πίνακα γίνεται αναζητώντας το στοιχείο στη μέση του πίνακα, στη συνέχεια στη μέση της μέσης κ.ο.κ.
- Αν ο πίνακας έχει Ν στοιχεία θα απαιτηθούν κατά μέσο όρο log2 N συγκρίσεις.
- Η βιβλιοθήκη της C υλοποιεί τον αλγόριθμο αυτό στη συνάρτηση bsearch:
#include <stdlib.h> void *bsearch(const void *key, const void *base, size_t num, size_t width, int (*compare)(const void *elem1, const void *elem2));
- Η συνάρτηση αναζητά την τιμή που δείχνεται από το δείκτη key σε έναν ταξινομημένο πίνακα δεδομένων με βάση μια συνάρτηση σύγκρισης.
- Η συνάρτηση έχει τις παρακάτω παραμέτρους:
- key
- Δείκτης στην τιμή για την οποία εκτελείται η αναζήτηση.
- base
- Δείκτης στην αρχή του πίνακα των δεδομένων που θα εκτελεστεί η αναζήτηση.
- num
- Αριθμός των δεδομένων στον πίνακα.
- width
- Το μέγεθος κάθε στοιχείου του πίνακα (π.χ. sizeof(int), sizeof(struct s_elem *)).
- compare
- Δείκτης σε συνάρτηση που συγκρίνει δύο στοιχεία με βάση δείκτες σε αυτά.
Η συνάρτηση compare (όπως και αυτή της qsort)
πρέπει να επιστρέφει τις παρακάτω τιμές:
- < 0
- αν το elem1 < elem2,
- 0
- αν το elem1 == elem2 και
- > 0
- αν το elem1 > elem2.
Παράδειγμα
Το παρακάτω παράδειγμα διαβάζει μια γραμμή και την τυπώνει σύμφωνα με το διεθνές φωνητικό αλφάβητο (π.χ. για τη γραμμή HELLO WORLD θα τυπώσει:Hotel Echo Lima Lima Oscar Whiskey Oscar Romeo Lima Delta
/*
* Read a line from the standard input and print it according to the
* international phonetic alphabet.
*
* Diomidis Spinellis. March 1999.
*
* $Id$
*
*/
#include <stdlib.h>
#include <stdio.h>
/*
* The international phonetic alphabet (sorted)
*/
char *names[] = {
"Alpha",
"Bravo",
"Charlie",
"Delta",
"Echo",
"Foxtrot",
"Golf",
"Hotel",
"India",
"Juliet",
"Kilo",
"Lima",
"Mike",
"November",
"Oscar",
"Papa",
"Quebec",
"Romeo",
"Sierra",
"Tango",
"Uniform",
"Victor",
"Whiskey",
"X-Ray",
"Yankee",
"Zulu",
};
/*
* Bsearch compare function
*/
static int
namecmp(char **a, char **b)
{
return (**a - **b);
}
main()
{
char buff[80], *p, **name;
fgets(buff, sizeof(buff), stdin);
for (p = buff; *p; p++)
if (name = (char **)bsearch(&p, names, 26, sizeof(char *), namecmp))
printf("%s\n", *name, *name);
}
Βιβλιογραφία
- Χρήστος Κοίλιας
Δομές Δεδομένων και Οργανώσεις Αρχείων. σ. σ. 107-132
Εκδόσεις Νέων Τεχνολογιών, 1993.
- Donald E. Knuth.
The Art of Computer Programming, volume 3 / Searching
and Sorting.
Addison-Wesley, second edition, 1973.
- Niklaus Wirth.
Algorithms + Datastructures = Programs. p. 56-134.
Prentice-Hall, 1976.
- Sarwar, S. Mansoor, Sarwar, Syed Aqeel, and Brandeburg, Jesse.
Engineering Quicksort.
Computer Languages, 22(1), 1996.
Ασκήσεις
Άσκηση 6
- Να υλοποιηθεί σε C πρόγραμμα το οποίο διαβάζει ονόματα
και τηλέφωνα μέχρι να συναντήσει το όνομα "ΤΕΛΟΣ".
Στη συνέχεια, για κάθε επόμενο όνομα που διαβάζει,
τυπώνει το αντίστοιχο τηλέφωνο, ή τη λέξη ΑΓΝΩΣΤΟΣ
αν δεν υπάρχει.
Το πρόγραμμα να υλοποιηθεί με τη χρήση των qsort και bsearch.
Παράδειγμα:
Γιάννης 031343454 Φανή 027354566 Θανάσης 014645678 Αλέξανδρος 56789 Γεωργία 034556789 ΤΕΛΟΣ Σωτήρης ΑΓΝΩΣΤΟΣ Φανή 027354566
Σημείωση: Η σύγκριση για τη λέξη "ΤΕΛΟΣ" μπορεί να γίνει ως εξής:if (strcmp(buff, "END\n") == 0) ...
Κατακερματισμός
Εισαγωγή
- Ο κατακερματισμός (hashing) είναι μια μέθοδος για τη φύλαξη στοιχείων με βάση ένα κλειδί σε γραμμικές δομές δεδομένων (πίνακες, αρχεία) με στόχο τη γρήγορη ανεύρεσή τους.
- Βασίζεται στη χρήση μιας συνάρτησης απεικόνισης με πεδίο ορισμού το κλειδί των στοιχείων και πεδίο τιμών τους δείκτες της αντίστοιχης δομής δεδομένων (λ.χ. ακέραιοι δείκτες σε πίνακα ή δείκτες θέσης σε αρχείο).
- Σε κάθε σύστημα κατακερματισμού πρέπει να λαμβάνουμε μέριμνα για την περίπτωση όπου δύο κλειδιά θα συμπίπτουν στην ίδια θέση της δομής μας.
Ορισμοί
Σε ένα σύστημα κατακερματισμού μπορούμε να ορίσουμε τα παρακάτω:- Ονομάζουμε πυκνότητα κλειδιών (key density) το λόγο του πληθαρίθμου του συνόλου του πεδίου τιμών προς τον πληθάριθμο του συνόλου του πεδίου ορισμού της συνάρτησης κατακερματισμού.
- Η διεύθυνση στην οποία απεικονίζει η συνάρτηση κατακερματισμού το κλειδί ονομάζεται βασική διεύθυνση (hash address).
- Ονομάζουμε συντελεστή φόρτισης (loading factor) το λόγο των στοιχείων της δομής που έχουν καταληφθεί προς τα στοιχεία της δομής που παραμένουν ελεύθερα.
- Συνώνυμα (Synonyms) είναι δύο κλειδιά για τα οποία η συνάρτηση κατακερματισμού δίνει την ίδια τιμή.
- Η παραπάνω κατάσταση ονομάζεται σύγκρουση (collision).
- Υπερχείλιση (Overflow) είναι η διαδικασία που εκτελείται για να υπερβούμε το πρόβλημα που δημιουργεί μια σύγκρουση.
- Η συνάρτηση κατακερματισμού καλείται ομοιόμορφη (uniform) αν είναι ίσες οι πιθανότητες απεικόνισης κάθε πιθανής τιμής του κλειδιού.
- Τέλος, η συνάρτηση κατακερματισμού καλείται τέλεια (perfect) αν ο αριθμός των δυνατών κλειδιών ταυτίζεται με τον πληθάριθμο του πεδίου τιμών της συνάρτησης χωρίς τη δημιουργία συγκρούσεων.
Συναρτήσεις κατακερματισμού
Η συνάρτηση κατακερματισμού πρέπει να εκτελείται γρήγορα και να είναι κατά το δυνατό ομοιόμορφη. Οι παρακάτω είναι μερικές ενδεικτικές μέθοδοι υλοποίησης:- Λογικές μέθοδοι βασισμένες σε συναρτήσεις όπως η αποκλειστική διάζευξη.
- Πολλαπλασιαστικές μέθοδοι βασισμένες στον πολλαπλασιασμό.
- Χρήση του υπολοίπου.
- Χρήση του μέσου του τετραγώνου.
- Μετατροπή βάσης.
- Διάσπαση του κλειδιού και πρόσθεση των τμημάτων.
- Αναδίπλωση των άκρων.
Διαχείριση συγκρούσεων
Σε περίπτωση που σημειωθεί μια σύγκρουση υπάρχουν οι παρακάτω επιλογές:- Απευθείας σύνδεση του στοιχείου που καταλαβάνει τη θέση με το νέο στοιχείο το οποίο φυλάσσεται σε μια άλλη περιοχή (π.χ. σε συνδεδεμένη λίστα).
- Γραμμική εξέταση: το στοιχείο φυλάσσεται στην πρώτη επόμενη κενή θέση του αρχείου.
- Δευτεροβάθμια εξέταση: αν η θέση κ είναι γεμάτη το στοιχείο φυλάσσεται σε κάποια θέση (κ+i*i) mod β όπου i = 1 ...
Υλοποίηση σε C
Ο ορισμός της γλώσσας προγραμματισμού C εγγυάται ότι οι αριθμητικές και λογικές πράξεις μη προσημασμένων ακεραίων (π.χ. unsigned int) γίνονται πάντα με υπερχείλιση modulo ν όπου ν ο αριθμός των bits που χρησιμοποιείται για τη φύλλαξη των αριθμών.Ο παρακάτω πίκανας απεικονίζει τους αντίστοιχους αριθμούς ν στην αρχιτεκτονική Intel Pentium:
| Τύπος | ν (bits) |
| unsigned char | 8 |
| unsigned short | 16 |
| unsigned int | 32 |
| unsigned long | 32 |
Έτσι για παράδειγμα σε πρόσθεση δύο τιμών τύπου unsigned char 250 + 10 το αποτέλεσμα θα είναι 4 μια και 260 mod 2 8 = 4. Η ιδιότητα αυτή σε συνδυασμό με τις πράξεις πάνω σε bits που ορίζει η C μας επιτρέπει να ορίζουμε εύκολα συναρτήσεις κατακερματισμού.
Οι τελεστές για πράξεις πάνω σε bits ακεραίων αριθμών είναι οι παρακάτω:
| Τελεστής | Πράξη |
| | | σύζευξη (or) |
| & | διάζευξη (and) |
| ^ | αποκλειστική διάζευξη (exclusive or) |
| ~ | άρνηση (negation) |
unsigned int
hash(unsigned char string)
{
char *s;
unsigned char sum = 0;
for (*s = string; *s; s++)
sum ^= *s;
return (sum & 127);
}
Βιβλιογραφία
- Χρήστος Κοίλιας
Δομές Δεδομένων και Οργανώσεις Αρχείων. σ. 208-221
Εκδόσεις Νέων Τεχνολογιών, 1993.
- Donald E. Knuth.
The Art of Computer Programming, volume 3 / Searching
and Sorting.
Addison-Wesley, second edition, 1973.
- Niklaus Wirth.
Algorithms + Datastructures = Programs. p. 169-280.
Prentice-Hall, 1976.
Ασκήσεις
Άσκηση (προαιρετική)
- Να υλοποιηθεί σε C πρόγραμμα το οποίο διαβάζει 5 ακεραίους
και τους αποθηκεύει με κατακερματισμό σε πίνακα 50 θέσεων.
Στην συνέχεια ζητάει κατ' εξακολούθηση από το χρήστη να δώσει έναν ακέραιο
αριθμό και τυπώνει στην οθόνη αν ο αριθμός αυτός ήταν ανάμεσα στους 5 ή όχι.
Το ενδεχόμενο της υπερχείλισης να μην εξεταστεί.
Παράδειγμα:
454 3466 456 23 199 Give number: 123 Not known Give number: 456 Known
Τεχνικές αρχείων
Βοηθητική μνήμη
- Η βοηθητική μνήμη διαφέρει από την κύρια ως προς:
- το κόστος ανά byte (μικρότερο),
- το χρόνο πρόσβασης (μεγαλύτερος) και
- τη χωρητικότητα (μεγαλύτερη).
- Βασικές τεχνολογίες βοηθητικής μνήμης είναι:
- οι μαγνητικές ταινίες,
- οι μαγνητικοί δίσκοι,
- οι οπτικοί δίσκοι (CD-ROM, CD-R, CD-RW, DVD),
- οι μαγνητο-οπτικοί δίσκοι.
- Ανάλογα με την τεχνολογία βοηθητικής μνήμης στα δεδομένα των αρχείων μπορούμε να έχουμε σειριακή προσπέλαση (serial access) (λ.χ. μαγνητική ταινία) ή τυχαία προσπέλαση (random access) (λ.χ. μαγνητικός δίσκος).
- Τα δεδομένα σε δίσκους είναι στις περισσότερες περιπτώσεις
οργανωμένα σε
κυλίνδρους, (cylinders)
αυλάκια (tracks),
και
τομείς (sectors).
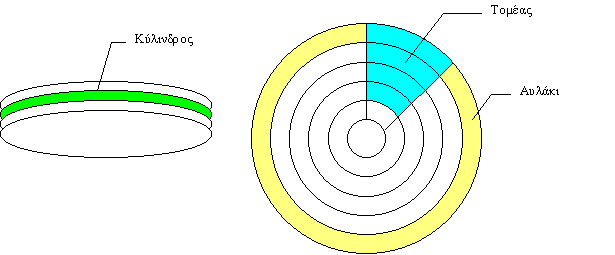
- Πρόσβαση στα στοιχεία ενός αρχείου γίνεται μέσω μιας ιεραρχίας
λογισμικού που μπορεί να περιλαμβάνει:
- το λογισμικό της εφαρμογής,
- το ενδιάμεσο λογισμικό (middleware),
- το λογισμικό της βάσης δεδομένων ή αντίστοιχες βιβλιοθήκες,
- το λειτουργικό σύστημα και συγκεκριμένα το σύστημα αρχείων,
- τον οδηγό συσκευής,
- το λογισμικό ελέγχου της συσκευής (firmware).
- Σημασία στην υλοποίηση του τρόπου χειρισμού των αρχείων έχει η ταχύτητα των μονάδων βοηθητικής μνήμης. Αυτή είναι της τάξης των ms σε αντιπαράθεση με την ταχύτητα της κύριας μνήμης η οποία είναι της τάξης των δεκάδων ns.
Αρχεία
- Τα δεδομένα στη βοηθητική μνήμη (π.χ. σκληρό δίσκο, CD-RW) φυλάσσονται ομαδοποιημένα σε αρχεία (files).
- Η οργάνωση των αρχείων εξαρτάται από την εφαρμογή που τα
δημιουργεί και τα διαβάζει.
Τα παρακάτω αποτελούν παραδείγματα περιεχομένου ενός αρχείου:
- Αδόμητο κείμενο
- Πηγαίος κώδικας (λ.χ. C, Java, συμβολική γλώσσα)
- Εκτελέσιμο πρόγραμμα
- Αρχείο βάσης δεδομένων
- Αρχείο δεδομένων εφαρμογής (λ.χ. Word, Excel)
- Αρχεία τα οποία περιέχουν ομοειδή στοιχεία οργανώνονται με βάση τις εγγραφές.
- Κάθε εγγραφή περιέχει έναν αριθμό από πεδία τα οποία χαρακτηρίζονται από το μήκος τους και τον τύπο των δεδομένων που περιέχουν. Για λόγους ευκολίας αναφερόμαστε στα πεδία με βάση κάποιο όνομα ανάλογα με τα δεδομένα που περιέχουν (π.χ. ΟΝΟΜΑ, ΥΠΟΛΟΙΠΟ).
- Η διάταξη των πεδίων στην εγγραφή καθώς και το είδος των πεδίων ενός αρχείου καλείται γραμμογράφηση (layout) του αρχείου.
Επεξεργασία σειριακών αρχείων
- Εφαρμογές που επεξεργάζονται σειριακά αρχεία (λ.χ. αρχεία που φυλάσσονται σε μαγνητικές ταινίες) είναι δομημένες με βάση διεργασίες που διαβάζουν σειριακά ένα ή περισσότερα αρχεία και παράγουν, σειριακά, νέα αρχεία.
- Ο όγκος των στοιχείων στις εφαρμογές αυτές φυλάσσεται στο κύριο αρχείο (master file) ενώ οι συναλλαγές κάθε ημέρας ή περιόδου φυλάσσονται στο αρχείο συναλλαγών (transaction file)
- Στα αρχεία αυτά διακρίνουμε τις παρακάτω διεργασίες:
- Σύζευξη αρχείων (merge): ένωση δύο σειριακών ταξινομημένων αρχείων σε τρίτο ταξινομημένο.
- Ταξινόμηση (sort): Ταξινόμηση των εγγραφών του αρχείου με βάση κάποιο κλειδί της εγγραφής. Η ταξινόμηση πραγματοποιείται συνήθως στην κύρια μνήμη. Αν τα δεδομένα δε χωράνε στην κύρια μνήμη ταξινομείται το αρχείο ανά τμήματα τα οποία στη συνέχεια ενώνονται με σύζευξη.
- Ενημέρωση (update): ενημέρωση του ταξινομημένου κυρίου αρχείου με βάση το αρχείο συναλλαγών.
- Ερώτηση (query) δημιουργία αρχείου που περιέχει τα δεδομένα που ικανοποιούν κάποιο κριτήριο.
- Αναφορά (report): δημιουργία μιας διαμορφωμένης αναφοράς από τα στοιχεία του αρχείου.
Αρχεία τυχαίας προσπέλασης
- Τα αρχεία τυχαίας προσπέλασης είναι συνήθως οργανωμένα σε πίνακες με βάση το σχεσιακό μοντέλο.
- Τα προγράμματα βάσεων δεδομένων επιτρέπουν την οργάνωση μη προκαθορισμένων στοιχείων σε αρχεία τυχαίας προσπέλασης.
- Για γρήγορη πρόσβαση στα στοιχεία κάθε πίνακα χρησιμοποιούνται βοηθητικές δομές αναζήτησης με δείκτες στους κυρίους πίνακες.
- Τέτοιες δομές μπορεί να είναι:
- ταξινομημένοι πίνακες για στοιχεία που δε μεταβάλλονται,
- πίνακες κατακερματισμού,
- δένδρα.
- Στα αρχεία αυτά υπάρχει συνήθως σύστημα το οποίο οργανώνει τη διάθεση του ελεύθερου χώρου που προέρχεται από διαγραφές.
- Οι αλλαγές στο κύριο αρχείο γίνονται συνήθως άμεσα. Παράλληλα ενημερώνεται και ένα αρχείο συναλλαγών το οποίο επιτρέπει την ακύρωση συναλλαγών ή την επανεκτέλεσή τους σε παλαιότερο κύριο αρχείο.
Επεξεργασία αρχείων στη C
Η επεξεργασία αρχείων στη C γίνεται με βάση συναρτήσεις του αφηρημένου τύπου δεδομένων FILE * που ορίζονται στην επικεφαλίδα stdio.h. Για να αποκτήσει το πρόγραμμα πρόσβαση σε ένα αρχείο πρέπει να καλέσει τη συνάρτηση:fopen(μονοπάτι αρχείου, τύπος πρόσβασης)
Η συνάρτηση επιστρέφει μια τιμή τύπου FILE * την οποία το πρόγραμμα χρησιμοποιεί για πρόσβαση στο αρχείο. Αν η πρόσβαση στο αρχείο δεν είναι δυνατή (π.χ. το αρχείο στο οποίο ζητήθηκε ανάγνωση δεν υπάρχει, ένας κατάλογος από το μονοπάτι δεν υπάρχει, το αρχείο το οποίο ζητήθηκε εγγραφή δεν το επιτρέπει) τότε η συνάρτηση fopen επιστρέφει την τιμή NULL.
Ο τύπος πρόσβασης μπορεί να είναι ένας από τους παρακάτω:
| Τύπος πρόσβασης | Πρόσβαση |
| "r" | Ανάγνωση (read) |
| "w" | Εγγραφή (write) |
| "a" | Προσθήκη (append) |
| "r+w" | Ανάγνωση και εγγραφή |
Στο τέλος της επεξεργασίας του αρχείου πρέπει να καλέσουμε τη συνάρτηση fclose(f) (όπου f η τιμή που επέστρεψε η fopen) για να δηλώσουμε στη βιβλιοθήκη και το λειτουργικό σύστημα να απελευθερώσουν τους πόρους που είχαν δεσμευτεί για την επεξεργασία του αρχείου.
Σειριακή επεξεργασία αρχείων ASCII στη C
Η σειριακή επεξεργασία αρχείων που περιέχουν χαρακτήρες ASCII στη μορφή που τους διαβάζουν και γράφουν οι άνθρωποι γίνεται με βάση τις παρακάτω συναρτήσεις:- fprintf(FILE *stream, char *format, ...)
- Τυπώνει φορμαρισμένα σε αρχείο.
- fscanf(FILE *stream, char *format, ...)
- Διαβάζει φορμαρισμένα από αρχείο.
- fgetc(FILE *stream)
- Διαβάζει έναν χαρακτήρα από αρχείο.
- fputc(char c, FILE *stream)
- Γράφει έναν χαρακτήρα σε αρχείο.
- feof(FILE *stream)
- Επιστρέφει αληθές αν έχει ανιχνευτεί το τέλος του αρχείου.
Το παρακάτω πρόγραμμα γράφει στο αρχείο codes.txt τους χαρακτήρες ASCII που διαβάζονται και τους αντίστοιχους κωδικούς τους:
#include <stdio.h>
main()
{
FILE *f;
int i;
f = fopen("codes.txt", "w");
for (i = ' '; i < '~'; i++)
fprintf(f, "Character: %c code:%d\n", i, i);
fclose(f);
}
Σημείωση: οι συναρτήσεις getc και putc είναι γρήγορες εκδόσεις των gfetc και fputc.
Σειριακή επεξεργασία κωδικοποιημένων αρχείων στη C
Για λόγους απόδοσης συχνά τα αρχεία δεν περιέχουν παράσταση των τιμών των δεδομένων με τη μορφή που τα εισάγουν και τα διαβάζουν οι άνθρωποι (αρχεία ASCII (ASCII files)), αλλά με τη μορφή που φυλάσσονται στη μνήμη του υπολογιστή (δυαδικά αρχεία (binary files)). Ο τρόπος αυτός φύλλαξης έχει τις παρακάτω επιπτώσεις:- το πρόγραμμα είναι ταχύτερο μια και δεν απαιτείται μετατροπή μεταξύ της εσωτερικής και της εξωτερικής μορφής παράστασης.
- η αποσφαλμάτωση του προγράμματος και των αρχείων του είναι πιο δύσκολη μια και τα δυαδικά αρχεία δεν μπορούν να διαβαστούν εύκολα από τυποποιημένα εργαλεία του συστήματος όπως ο διορθωτής.
- τα δυαδικά αρχεία δεν μπορούν να μεταφερθούν ανάμεσα σε υπολογιστές διαφορετικής αρχιτεκτονικής (π.χ. από Intel Pentium σε DEC Alpha) μια και η εσωτερική παράσταση των δεδομένων μεταξύ των αρχιτεκτονικών συνήθως διαφέρει.
- Τα δυαδικά αρχεία καταλαμβάνουν λιγότερο χώρο από τα αρχεία ASCII.
- fread(void *ptr, size_t size, size_t nitems, FILE *stream)
- Μεταφέρει nitems στοιχεία μεγέθους size από το αρχείο f στη θέση μνήμης ptr.
- fwrite(void *ptr, size_t size, size_t nitems, FILE *stream)
- Μεταφέρει nitems στοιχεία μεγέθους size από τη θέση μνήμης ptr στο αρχείο f.
int tbl[100]; fwrite(tbl, sizeof(int), 100, f);
Επεξεργασία αρχείων τυχαίως προσπέλασης στη C
Η βιβλιοθήκη της C μας δίνει τη δυνατότητα μετακίνησης και σε τυχαία σημεία του αρχείου με βάση τις συναρτήσεις fseek και ftell:- int fseek(FILE * f, long pos, int whence);
-
Ορίζει ως επόμενη θέση για ανάγνωση ή εγγραφή στο αρχείο f
τη θέση pos.
Η θέση ορίζεται ανάλογα με τη σταθερά που θα οριστεί στη whence:
- SEEK_CUR
- από την τρέχουσα θέση στο αρχείο,
- SEEK_END
- από το τέλος του αρχείου,
- SEEK_SET
- από την αρχή του αρχείου.
fseek(f, 10 * sizeof(int), SEEK_SET);
- long ftell(FILE *f)
- Επιστρέφει την τρέχουσα θέση ανάγνωσης/εγγραφής στο αρχείο f.
Βιβλιογραφία
- Χρήστος Κοίλιας
Δομές Δεδομένων και Οργανώσεις Αρχείων. σ. 208-221
Εκδόσεις Νέων Τεχνολογιών, 1993.
- Peter Pin-Shan Chen.
The entity-relationship model --- toward a unified view of data.
ACM Transactions on Database Systems, 1(1):9-36, March 1976.
- Henry F. Korth and Abraham Silberschatz.
Database System Concepts.
McGraw-Hill, third edition, 1996.
- Brian W. Kernighan, Dennis M. Ritchie
Η γλώσσα προγραμματισμού C. σ. 337-349
Δεύτερη έκδοση.
Κλειδάριθμος, 1988.
- Brian W. Kernighan and
Dennis M. Ritchie.
The C
Programming Language, pages 241-258.
Prentice-Hall, second edition, 1988.
- P. J. Plauger.
The Standard C Library.
Prentice Hall, 1992.
Ασκήσεις
Άσκηση 7
- Να υλοποιηθεί σε C το πρόγραμμα addphone
το οποίο ζητά από το χρήστη ένα όνομα και ένα τηλέφωνο και
τα προσθέτει σε αρχείο
καθώς και το πρόγραμμα getphone το οποίο ζητά από το
χρήστη ένα όνομα και αν αυτό βρίσκεται στο αρχείο
τυπώνει το τηλεφωνό του.
Παράδειγμα:C>addphone Name:EKAB Phone:166 C>getphone Name:EKAB Phone=166
Αντικείμενα στη C++
Εισαγωγή
- Η C++ είναι μια γλώσσα που έχει προέλθει από τη C.
- Πλεονεκτήματά της σε σχέση με τη C++ είναι:
- η δυνατότητα οργάνωσης δεδομένων σε μια κλάση (class),
- ο ορισμός κληρονομικότητας (inheritance) στη δομή των κλάσεων,
- η δυνατότητα αρχικοποίησης δεδομένων,
- ο ορισμός μεταβλητών ως αναφορά (reference) σε κάποια άλλη,
- ο πολυμορφικός (polymorphic) καθορισμός συναρτήσεων με βάση τον τύπο του ορίσματός τους,
- η υπερφόρτιση (overloading) τελεστών,
- η πλούσια βιβλιοθήκη βασικών δομών δεδομένων και
- η δυνατότητα ορισμού πολυμορφικών βασικών τύπων με βάση ένα πρότυπο (template).
- Τα παραπάνω στοιχεία επιτρέπουν στη γλώσσα να υποστηρίζει τον αντικειμενοστρεφή προγραμματισμό (object-oriented programming).
- Υπάρχουν παρόλ' αυτά εφαρμογές οι οποίες γράφονται καλύτερα σε C.
Τέτοιες είναι:
- προγράμματα που έχουν άμεση σχέση με το υλικό όπως ο πυρήνας του λειτουργικού συστήματος και οι οδηγοί συσκευών,
- ενσωματωμένες (embedded) εφαρμογές που εκτελούνται σε περιβάλλον που δεν μπορεί να ανταποκριθεί στις απαιτήσεις της C++.
- Άλλες γλώσσες στην ίδια οικογένεια με τη C++ (1983) είναι:
- η Simula67 (1967),
- η Smalltalk (1979) και
- η Java (1995).
Το πρώτο πρόγραμμα σε C++
Το πρώτο πρόγραμμα σε C++ θα τυπώσει, όπως θα περίμενε κανείς, τις λέξεις hello, world:
#include <iostream.h>
main()
{
cout << "hello, world\n";
}
Μεταγλώττιση
Στο περιβάλλον του εργαστηρίου (Windows NT, Visual C++) το πρόγραμμα πρέπει να έχει επίθεμα .cpp αντί για .c για να το αναγνωρίσει ο μεταγλωττιστής ως πρόγραμμα C++. Ο μεταγλωττιστής παραμένει ο ίδιος (cl).Σε εγκαταστάσεις Linux το πρόγραμμα πρέπει να έχει επίθεμα .C. Για να μεταγλωττιστεί χρησιμοποιούμε την εντολή g++.
C++ ως καλύτερη C
Η C++ προσφέρει πρόσθετες δυνατότητες σε προγράμματα C:- Ορισμοί μεταβλητών μπορούν να δοθούν σε οποιοδήποτε σημείο
μπορεί να δοθεί μια έκφραση.
Παράδειγμα:
#include <iostream.h> main() { int i = 3; cout << i; for (int j = 0; j < 10; j++) cout << j; }Καλό είναι οι μεταβλητές να ορίζονται ακριβώς πριν από το πρώτο σημείο όπου χρησιμοποιούνται. - Σχόλια της μιας γραμμής μπορούν να οριστούν με τους χαρακτήρες //:
Παράδειγμα:
int i; // This is a line comment; set i to 8. i = 8;
- Μεταβλητές μπορούν να οριστούν ως
αναφορά (reference) σε μια άλλη.
Παράδειγμα:
int y = 8; int &x = y; x = 3; // Set y to 3
- Συναρτήσεις μπορούν να οριστούν πολυμορφικά με βάση τον τύπο του
ορίσματός τους.
Παράδειγμα:
#include <iostream.h> double square(double x); int square(int x); double square(double x) { return (x * x); } int square(int x) { return (x * x); } main() { int i = 3; double d = 1.4142; cout << "square(" << i << ")=" << square(i) << "\n"; cout << "square(" << d << ")=" << square(d) << "\n"; } - Οι δηλώσεις δομών ορίζουν αυτόματα και έναν νέο τύπο με αντίστοιχο
όνομα. Ο τελεστής new επιστρέφει μνήμη με το σωστό μέγεθος και τύπο για
δομές και κλάσεις.
Η μνήμη που δεσμεύει ο τελεστής new ελευθερώνεται με τον τελεστή delete.
Παράδειγμα:
struct point { int x, y; }; point *p; main() { p = new point; delete p; } - Οι τελεστές new και delete[] δεσμεύουν και ελευθερώνουν και μνήμη για
πίνακες.
Παράδειγμα:
main() { int *ip = new int[10]; ip[3] = 8; delete[] ip; }
Ορισμός κλάσεων
- Η δήλωση μιας κλάσης (class)
είναι παρόμοια με αυτή μιας δομής:
class point { int x, y; }; - Οι κλάσεις χρησιμοποιούνται για την υλοποίηση αφηρημένων τύπων
δεδομένων.
Για το σκοπό αυτό μπορούμε να ορίσουμε μέλη (members)
της κλάσης:
μεταβλητές και συναρτήσεις
που είναι ορατά μόνο από συναρτήσεις που αναφέρονται στον τύπο αυτό
(private) καθώς και μεταβλητές και συναρτήσεις που είναι καθολικά
ορατά (public).
Οι μεταβλητές ορίζουν ιδιότητες (properties)
και οι συναρτήσεις ορίζουν
μεθόδους πρόσβασης (methods)
των αντικειμένων της κλάσης.
Παράδειγμα:
class point { private: int x, y; public: int getx(); int gety(); void setpos(int sx, int sy); void display(); };Στο παραπάνω παράδειγμα τα μέλη (ιδιότητες) της κλάσης x, y δεν είναι ορατά και προσβάσιμα παρά μόνο από τις συναρτήσεις (μεθόδους) της κλάσης getx, gety, setpos και display. - Ο ορισμός των συναρτήσεων της κλάσης γίνεται με τη χρήση της
σύνταξης κλάση::συνάρτηση.
Παράδειγμα:
int point::getx() { return (x); } int point::gety() { return (y); } void point::display() { cout << "(" << x << "," << y << ")\n"; } void point::setpos(int sx, int sy) { x = sx; y = sy; } - Αφού δηλωθεί μια κλάση (τυπικά σε ένα αρχείο κλάση.h) και οριστούν
οι συναρτήσεις της (τυπικά σε ένα αρχείο κλάση.cpp) μπορούν να οριστούν
μεταβλητές με τον τύπο της κλάσης.
Πρόσβαση στις συναρτήσεις της κλάσης έχουν οι μεταβλητές με τη
σύνταξη μεταβλητή.συνάρτηση.
Παράδειγμα:
#include <iostream.h> #include "point.h" main() { point a; point b, *c; c = new point; b.setpos(6, 6); cout << b.getx(); a.display(); b.display(); c->display(); } - Οι συναρτήσεις της κλάσης μπορούν να έχουν πρόσβαση στα στοιχεία της
κλάσης με τους εξής τρόπους:
- με το όνομά τους (π.χ. x),
- μέσω της ορισμένης από τη γλώσσα μεταβλητής this που δείχνει στην κλάση (π.χ. this->x),
- με πρόθεμα το όνομα της κλάσης για να αποφεύγεται η σύγχυση όταν υπάρχει τοπική μεταβλητή με το ίδιο όνομα (π.χ. point::x).
void point::setpos(int sx, int sy) { this->x = sx; point::y = sy; } - Σε κάθε κλάση μπορεί να οριστεί μια
συνάρτηση κατασκευής (constructor) με όνομα ίδιο
με αυτό της κλάσης και μια
συνάρτηση καταστροφής (destructor) με όνομα το
όνομα της κλάσης με το πρόθεμα ~.
Η συνάρτηση κατασκευής καλείται κάθε φορά που δημιουργείται
ένα νέο αντικείμενο (σε επίπεδο καθολικό, τοπικό, ή με new).
Η συνάρτηση καταστροφής καλείται κάθε φορά που παύει να υπάρχει
ένα αντικείμενο δηλαδή αντίστοιχα όταν τελειώνει το πρόγραμμα, όταν
η ροή βγαίνει από το τοπικό τμήμα, ή καλείται η delete.
Το όρισμα που δηλώνουμε στη συνάρτηση κατασκευής επιτρέπει προσδιορισμό
ιδιοτήτων του αντικειμένου που δημιουργούμε (π.χ. τον αριθμό στοιχείων
σε μια στοίβα) ή αρχικών τιμών.
Η συνάρτηση καταστροφής δε δέχεται κάποιο όρισμα.
Οι συναρτήσεις αυτές μπορούν να χρησιμοποιηθούν για να διαχειριστούν τη
μνήμη αντικειμένων που απαιτούν τη χρήση δυναμικής μνήμης με κατάλληλες
κλήσεις στις new και delete.
Παράδειγμα:
class stack { private: int *values; int size; int sp; public: stack(int size); // Constructor ~stack(); // Destructor }; stack::stack(int size) { stack::size = size; values = new int[size]; } stack::~stack() { delete[] values; } - Η κλήση της συνάρτησης κατασκευής μπορεί να γίνει κατά τον ορισμό μιας μεταβλητής με τη μορφή "κλάση μεταβλητή = κλάση(όρισμα)" ή συνοπτικότερα με τη μορφή "κλάση μεταβλητή(όρισμα)".
- Σε μια κλάση μπορούν να δηλωθούν (με τον προσδιορισμό static)
μεταβλητές οι οποίες υπάρχουν μόνο μια φορά για όλη την κλάση,
καθώς και συναρτήσεις που μπορούν
να κληθούν με τη σύνταξη κλάση::συνάρτηση.
Οι μεταβλητές αυτές χρησιμοποιούνται για την επεξεργασία στοιχείων
που αφορούν ολόκληρη την κλάση και όχι τα αντικείμενά της.
Οι συναρτήσεις που έχουν οριστεί static δεν έχουν πρόσβαση σε μη
static μεταβλητές ούτε στη μεταβλητή this.
Η αρχικοποίηση των μεταβλητών που έχουν δηλωθεί static πρέπει να γίνει
σε καθολικό επίπεδο, μια φορά για κάθε κλάση.
Το παρακάτω παράδειγμα ορίζει έναν μετρητή numpoints που μετρά πόσα
σημεία είναι ενεργά καθώς και την αντίστοιχη συνάρτηση πρόσβασης:
class point { private: int x, y; static int numpoints; public: // ... static int points_used(); }; int point::numpoints = 0; // Constructors point::point(int sx, int sy) { x = sx; y = sy; numpoints++; } point::point() { x = y = 0; numpoints++; } // Destructor point::~point() { numpoints--; } // Access function int point::points_used() { return (numpoints); } - Σε μια κλάση μπορούν να οριστούν συναρτήσεις με τον προσδιορισμό
friend.
Οι συναρτήσεις αυτές ορίζονται σε καθολικό επίπεδο και μπορούν να
έχουν πρόσβαση στα στοιχεία private της κλάσης.
Οι συναρτήσεις friend χρησιμοποιούνται όταν η χρήση των συναρτήσεων
μέλους δεν είναι βολική.
Παράδειγμα:
class point { private: int x, y; static int numpoints; public: // ... friend void display(point& p); // Display friend function }; // Friend function; used as display(a) void display(point& p) { cout << "(" << p.x << "," << p.y << ")\n"; } main() { point b = point(1, 2); display(b); // Friend function } - Συναρτήσεις που δε μεταβάλλουν μέλη της κλάσης καλό είναι να δηλώνονται
και να ορίζονται ακολουθούμενες με τον προσδιορισμό const:
class point { private: int x, y; public: int getx() const; // Access functions int gety() const; void display(); // Display member function // ... }; int point::getx() const { return (x); }Ο προσδιορισμός αυτός αναγκάζει το μεταγλωττιστή να ελέγχει αν η δέσμευση αυτή τηρείται μέσα στο σώμα της συνάρτησης. - Το παρακάτω παράδειγμα ορίζει και χρησιμοποιεί
την κλάση point που - εξεζητημένα - εκμεταλλεύεται όλα τα στοιχεία που
έχουν αναφερθεί:
#include <iostream.h> class point { private: int x, y; static int numpoints; public: point(); // Default contructor point(int sx, int sy); // Other constructor ~point(); // Destructor int getx() const; // Access functions int gety() const; void display(); // Display member function void setpos(int sx, int sy); // Set position static int points_used(); // Return number of points friend void display(point& p); // Display friend function }; int point::numpoints = 0; point::point(int sx, int sy) { x = sx; y = sy; numpoints++; } point::point() { x = y = 0; numpoints++; } point::~point() { numpoints--; } int point::getx() const { return (x); } int point::gety() const { return (y); } // Member function; used as a.display(); void point::display() { cout << "(" << x << "," << y << ")\n"; } // Friend function; used as display(a) void display(point& p) { cout << "(" << p.x << "," << p.y << ")\n"; } void point::setpos(int sx, int sy) { this->x = sx; point::y = sy; } int point::points_used() { return (numpoints); } main() { point a(1, 2); point b, *c; c = new point(5, 5); b.setpos(6, 6); a.display(); // Member function display(b); // Friend function c->display(); cout << "points used = " << point::points_used() << "\n"; delete(c); cout << "points used = " << point::points_used() << "\n"; }
Καθοριζόμενοι τελεστές
- Σε μια κλάση μπορούμε να ορίσουμε συναρτήσεις σε αντιστοιχία με τους καθορισμένους τελεστές της C++ (+, -, *, /, ==, =, κ.λπ.) με τη σύνταξη operator τελεστής(όρισμα).
- Το όρισμα πρέπει να περιέχει τόσες παραμέτρους όσες απαιτεί και ο αντίστοιχος τελεστής. Αν η συνάρτηση είναι μέλος της κλάσης (και όχι ορισμένη ως friend) τότε το πρώτο στοιχείο του ορίσματος περνάει αυτόματα μέσω της this και δεν ορίζεται.
- Οι τελεστές που επιτρέπεται να οριστούν, η προτεραιότητα των τελεστών και ο τρόπος που αυτοί συνδέονται (αριστερά προς τα δεξιά ή ανάποδα) δεν μπορούν να μεταβληθούν.
- Το παρακάτω παράδειγμα ορίζει τον τελεστή + στην κλάση point,
επιτρέποντας την πρόσθεση σημείων:
#include <iostream.h> class point { private: int x, y; public: point(int sx, int sy); // Constructor point operator+(point b); // Overload the + operator void display(); // Display member function }; point::point(int sx, int sy) { x = sx; y = sy; } void point::display() { cout << "(" << x << "," << y << ")\n"; } point point::operator+(point b) { point p(x, y); // p is a new point at x, y p.x += b.x; p.y += b.y; return (p); } main() { point p1 = point(1, 2); point p2 = point(10, 20); point p3 = point(0, 0); p3 = p1 + p2; p1.display(); p2.display(); p3.display(); }
Είσοδος και έξοδος
- Η έξοδος στοιχείων στη C++ γίνεται με τις κλάσεις που ορίζονται στην επικεφαλίδα iostream.h.
- Με τη σύνταξη cout << τιμή1 << τιμή2 ... μπορούν να τυπωθούν τιμές των τύπων που ορίζονται στη γλώσσα.
- Με τη σύνταξη cint >> μεταβλητή1 >> μεταβλητή2 ... μπορούν να εισαχθούν αντίστοιχες τιμές από το χρήστη.
- Ο έλεγχος των τύπων των τιμών γίνεται από το μεταγλωττιστή.
Βιβλιογραφία
- Ellis Horowitz
Βασικές αρχές γλωσσών προγραμματισμού.
Δεύτερη αμερικάνικη έκδοση.
σ. 235-238, 272-278, 421-447 Εκδόσεις Κλειδάριθμος, 1984.
- Brad J. Cox. Object Oriented Programming: An Evolutionary Approach. Addison-Wesley, 1986.
- O-J. Dahl, B. Myrhaug, and K. Nygaard. SIMULA common base language. Technical Report S-22, Norwegian Computing Center, Oslo, Norway, 1970.
- Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1995.
- Adele Goldberg. Smalltalk 80: The Language and its Implementation. Addison Wesley, 1980.
- Glenn Krasner. Smalltalk 80: Bits of History, Words of Advice. Addison Wesley, 1980.
- Bertrand Meyer. Object-oriented Software Construction. Prentice Hall, 1988.
- Lewis J. Pinson and Richard S. Wiener. An Introduction to Object-Oriented Programming and Smalltalk. Addison-Wesley, 1988.
- James Rumbaugh, Michael Blaha, William Premerlani, Frederick Eddy, and William Lorensen. Object-Oriented Modeling and Design. Prentice-Hall, 1991.
- Peter H. Salus, editor. Handbook of Programming Languages, volume I: Object-Oriented Programming Languages. Macmillan Technical Publishing, 1998.
- Bjarne Stroustrup. The C++ Programming Language. Addison-Wesley, third edition, 1997.
Πηγές στο Internet
- C++ FAQ LITE (http://www.cerfnet.com/~mpcline/c++-faq-lite/)
- Teach Yourself C++ in 21 Days (http://lskk-gtw.ee.itb.ac.id/~metra/books/cpp/index.htm)
- Yahoo! Computers and Internet:Programming Languages:C and C++:C++ (http://dir.yahoo.com/Computers_and_Internet/Programming_Languages/C_and_C__/C__/)
- ANSI Standard December 1996 Working Paper (http://www.cygnus.com/misc/wp/dec96pub/)
Άσκηση
Άσκηση 8
- Να υλοποιηθεί σε C++ η κλάση της ουράς ακεραίων int_queue
σύμφωνα με τις παρακάτω συναρτήσεις:
- Δημιουργεί μια άδεια ουρά size στοιχείων
-
int_queue(int size); - Το στοιχείο i εισάγεται στο τέλος της ουράς
-
void put_int_queue(int i); - Το στοιχείο από την αρχή της μη κενής ουράς αφαιρείται και επιστρέφεται
-
int get_int_queue(); - Επιστρέφεται αληθές αν η ουρά είναι κενή
-
int isempty_int_queue();
- Με βάση τον αφηρημένο αυτό τύπο και μονοτονικά αυξανόμενη μεταβλητή
να υλοποιηθεί πρόγραμμα το οποίο να υλοποιεί ουρά εξυπηρέτησης πελατών
ως εξής:
- Όταν εισάγεται ο χαρακτήρας I (In) το πρόγραμμα τυπώνει τον αριθμό προτεραιότητας του νέου πελάτη.
- Όταν εισάγεται ο χαρακτήρας O (Out) το πρόγραμμα τυπώνει τον αριθμό προτεραιότητας του επόμενου πελάτη που θα εξυπηρετηθεί.
I 1 I 2 I 3 O 1 I 4 O 2 ...
Παρατήρηση: Το πρόγραμμα μπορεί να δομηθεί γύρω από τον παρακάτω κώδικα εισόδου:#include <iostream.h> main() { char c; // Initializations here for (;;) { cin >> c; switch (c) { case 'I': // Process input here break; case 'O': // Process output here break; } } }
Κληρονομικότητα
Εισαγωγή
- Συχνά μια σειρά κλάσεων αντικειμένων μπορεί να μοντελοποιηθεί με τη μορφή μιας ιεραρχίας.
- Για παράδειγμα:
- Όλα τα μέλη της Πανεπιστημιακής Κοινότητας είναι
φυσικά πρόσωπα και έχουν ως ιδιότητα το όνομα και το επώνυμό τους.
- Οι φοιτητές έχουν ακόμα ως ιδιότητα τον αριθμό μητρώου τους και το έτος που φοιτούν.
- Όσοι έχουν σχέση εργασίας με το Πανεπιστήμιο έχουν ως ιδιότητα το
μισθό τους.
- Το διοικητικό προσωπικό έχει ως πρόσθετη ιδιότητα την ειδικότητά του.
- Οι διδάσκοντες έχουν ως πρόσθετη ιδιότητα τα μαθήματα που διδάσκουν.
- Όλα τα μέλη της Πανεπιστημιακής Κοινότητας είναι
φυσικά πρόσωπα και έχουν ως ιδιότητα το όνομα και το επώνυμό τους.
Κληρονομικότητα σε κλάσεις
- Η ιεραρχία των κλάσεων εκφράζεται στη C++ με τον ορισμό μιας κλάσης που είναι υποκλάση (subclass) μιας άλλης κλάσης (που ονομάζεται βασική κλάση (base class)).
- Η σύνταξη για τον ορισμό αυτό είναι της μορφής:
class υποκλάση : public βασική_κλάση { ... - Κάθε υποκλάση κληρονομεί (inherits) τις μεθόδους και τις ιδιότητες που έχουν οριστεί ως public στη βασική κλάση.
- Η υποκλάση δεν έχει πρόσβαση στις μεθόδους και τις ιδιότητες που έχουν οριστεί ως private στη βασική κλάση.
- Η υποκλάση μπορεί να ορίσει νέες ιδιότητες και μεθόδους και να αντικαταστήσει ιδιότητες και μεθόδους που έχει ορίσει η βασική κλάση.
- Παράδειγμα:
class shape { private: int x, y; // Position public: void setposition(int x, int y); }; void shape::setposition(int x, int y) { shape::x = x; shape::y = y; } class circle : public shape { private: int radius; public: void setradius(int r); }; class rectangle : public shape { private: int height, width; public: void setdimensions(int h, int w); }; main() { circle c; rectangle r; r.setposition(1, 2); c.setposition(3, 4); } - Μπορούμε να ορίσουμε μια άλλη κατηγορία μεθόδων και ιδιοτήτων
με όνομα protected. Αυτές είναι προσβάσιμες από τις υποκλάσεις της
κλάσης μας, αλλά όχι από άλλες συναρτήσεις.
Παράδειγμα:
class shape { private: int x, y; protected: int getx(); // Can be used by subclasses int gety(); public: void setposition(int x, int y); } - Ένας δείκτης σε μια υποκλάση μπορεί αυτόματα να μετατραπεί σε
δείκτη στη βασική της κλάση. Το αντίθετο δεν επιτρέπεται.
Παράδειγμα:
main() { circle c; rectangle r; shape *sp; r.setposition(1, 2); c.setposition(3, 4); sp = &c; // Implici conversion sp->setposition(3, 3); // Set the position of c } - Μια κλάση μπορεί να δηλωθεί με
πολλαπλή κληρονομικότητα (multiple inheritance) με
τη σύνταξη:
class υποκλάση : public βασική_κλάση1, public βασική_κλάση2, ... { ...Στην περίπτωση αυτή η κλάση κληρονομεί τα μέλη και τις μεθόδους όλων των βασικών κλάσεων που δηλώθηκαν.
Ιδεατές συναρτήσεις
- Αν σε μια κλάση δηλώσουμε μια συνάρτηση ως virtual τότε οι υποκλάσεις της κλάσης αυτής μπορούν να αντικαταστήσουν τη συνάρτηση με μια που θα ορίσουν αυτές.
- Όταν κληθεί η συνάρτηση που έχει αντικατασταθεί από μια υποκλάση μέσω ενός δείκτη της βασικής κλάσης ο οποίος έχει προέλθει από δείκτη κάποιας υποκλάσης τότε θα κληθεί η αντίστοιχη συνάρτηση της υποκλάσης από την οποία έχει προέλθει ο δείκτης.
- Η δυνατότητα αυτή επιτρέπει:
- το δυναμικό καθορισμό της συμπεριφοράς ενός αντικειμένου ανάλογα με την κλάση του κατά την εκτέλεση του προγράμματος,
- την αλλαγή της συμπεριφοράς μιας παλιάς κλάσης από μια νεώτερη (υποκλάση της) και
- την ενοποιημένη διαχείριση διαφορετικών αντικειμένων μέσω της βασικής τους κλάσης.
- Η δυνατότητα αυτή προάγει τη C++ από γλώσσα που υποστηρίζει τα αντικείμενα σε αντικειμενοστρεφή γλώσσα.
Παράδειγμα
Το παρακάτω παράδειγμα ορίζει τη βασική κλάση shape και τις υποκλάσεις της circle και rectangle. Η μέθοδος area ορίζεται ως virtual με αποτέλεσμα να μπορεί να οριστεί για τις υποκλάσεις και κατά την εκτέλεση του προγράμματος να εκτελεστεί η σωστή έκδοσή της. Η συνάρτηση printarea της shape εκμεταλλεύεται τη δυνατότητα αυτή και μπορεί να κληθεί (και να δουλέψει σωστά) με όρισμα οποιαδήποτε από τις υποκλάσεις της shape.
#include <iostream.h>
class shape {
private:
double x, y; // Position
public:
void setposition(double x, double y);
void printarea();
virtual double area();
};
double
shape::area()
{
return (0);
}
void
shape::printarea()
{
cout << area() << "\n";
}
void shape::setposition(double x, double y)
{
shape::x = x;
shape::y = y;
}
class circle : public shape {
private:
double radius;
public:
void setradius(double r);
virtual double area();
};
void
circle::setradius(double r)
{
radius = r;
}
double
circle::area()
{
return (3.1415927 * radius * radius);
}
class rectangle : public shape {
private:
double height, width;
public:
void setdimensions(double h, double w);
virtual double area();
};
void
rectangle::setdimensions(double h, double w)
{
height = h;
width = w;
}
double
rectangle::area()
{
return (height * width);
}
main()
{
circle c;
rectangle r;
shape *sp;
r.setposition(1, 2);
c.setposition(3, 4);
r.setdimensions(10, 10);
c.setradius(1);
c.printarea();
r.printarea();
sp = &r;
cout << sp->area();
}
Αφηρημένες κλάσεις
- Αν μια ιδεατή (virtual)
συνάρτηση - μέθοδος μιας κλάσης - οριστεί με τη σύνταξη
= 0
τότε η συνάρτηση αυτή είναι θεωρητική (pure) δηλαδή δεν έχει υλοποίηση στη συγκεκριμένη κλάση. Παράδειγμα:class document { public: virtual char *Identify() = 0; }; - Αν μια κλάση περιέχει (ή έχει κληρονομήσει) τουλάχιστον μια θεωρητική μέθοδο τότε ονομάζεται αφηρημένη (abstract).
- Οι αφηρημένες κλάσεις χρησιμοποιούνται μόνο για να ορίσουν γενικές έννοιες από τις οποίες εκπορεύονται συγκεκριμένες κλάσεις.
- Έτσι οι αφηρημένες κλάσεις δε μπορούν να χρησιμοποιηθούν για να οριστούν:
- μεταβλητές
- μέλη άλλων κλάσεων
- παράμετροι συναρτήσεων
- τύποι επιστροφής συναρτήσεων
- τύποι μετατροπής
- Αντίθετα, μπορούν να οριστούν δείκτες και αναφορές σε αφηρημένες κλάσεις.
Για παράδειγμα, ένας σχεδιασμός του πληροφοριακού συστήματος του Πανεπιστημίου μπορεί να ορίσει την αφηρημένη κλάση person ως βασική κλάση για τις υποκλάσεις student, employee και visitor. Αν και δε θα μπορεί να οριστεί μια μεταβλητή για την αφηρημένη κλάση person, αυτή μπορεί να περιέχει ορισμένα βασικά χαρακτηριστικά όπως birth_date και να επιβάλει την υλοποίηση συγκεκριμένων μεθόδων όπως home_page_URL() ορίζοντάς τις ως θεωρητικές.
Πρότυπα στη C++ και δείκτες σε μέλη
Παραμετροποίηση προγραμμάτων με πρότυπα
Η C++ μας επιτρέπει να δηλώσουμε και να ορίσουμε συναρτήσεις και κλάσεις παραμετροποιημένες ως προς τους τύπους ή τις σταθερές που χρησιμοποιούν. Βάση για τους ορισμούς αυτούς είναι ένα πρότυπο (template). Έχοντας ορίσει μια συνάρτηση ή μια κλάση με μορφή προτύπου μπορούμε στη συνέχεια να τη χρησιμοποιήσουμε για κάποιο συγκεκριμένο τύπο ή σταθερά. Η χρήση αυτή γίνεται αυτόματα μέσα στον πηγαίο κώδικα. Το παρακάτω παράδειγμα ορίζει και χρησιμοποιεί μια συνάρτηση max παραμετροποιημένη ως προς τον τύπο των παραμέτρων και του αποτελέσματός της:
#include <iostream.h>
/*
* Return the maximum of a, b.
* A, b and the return type of max are of type T.
*/
template <class T>
T
max(T a, T b)
{
if (a > b)
return (a);
else
return (b);
}
main()
{
cout << max("Samos", "Zambia") << "\n";
cout << max(3, 42) << "\n";
cout << max(3.1415, 1.4142) << "\n";
}
Χρησιμοποιούμε πρότυπα:
- για να ορίσουμε μια δομή δεδομένων η οποία να δουλεύει για οποιοδήποτε τύπο θέλουμε,
- για να ορίσουμε πολυμορφικές συναρτήσεις που να δουλεύουν σε οποιοδήποτε τύπο τις χρησιμοποιήσουμε,
- για να επιτύχουμε έλεγχο τύπων σε συναρτήσεις των οποίων οι παράμετροι θα ήταν τύπου void * (π.χ. qsort, bsearch).
Ο ορισμός του προτύπου περιέχει μετά τη δεσμευμένη λέξη template μια σειρά τύπων ή παραμέτρων μέσα σε < > που χρησιμοποιούμε για να ορίσουμε τη συγκεκριμένη συνάρτηση ή κλάση. Οι τύποι και οι παράμετροι χωρίζονται μεταξύ τους με κόμμα. Οι τύπου μπορούν να οριστούν ως class όνομα_κλάσης (π.χ. class T) ή ως typename όνομα_τύπου (π.χ. typename T). Οι παράμετροι ορίζονται όπως και στις συναρτήσεις (π.χ. int stacksize). Μέσα στη δήλωση της συνάρτησης ή της κλάσης καθώς και στον ορισμό του σώματός τους μπορούμε να χρησιμοποιήσουμε τα ονόματα που δηλώθηκαν με βάση το πρότυπο σαν να ήταν πραγματικοί τύποι ή σταθερές. Κατά τη χρήση μια κλάσης ή συνάρτησης οι παράμετροι πρέπει να είναι σταθερές.
Το παρακάτω παράδειγμα δηλώνει την πρότυπη κλάση tstack ως μια στοίβα της οποίας ο τύπος των στοιχείων και το μέγεθος ορίζονται με βάση το πρότυπό της και το αντικείμενο instack ως μια στοίβα 20 ακεραίων:
template <class T, int i> class tstack
{
T data[i];
int items;
public:
tstack(void);
void push(T item);
T pop(void);
};
tstack <int, 20> intstack;
Η υλοποίηση προτύπων που χρησιμοποιούμε (Microsoft Visual C++ 5.0) απαιτεί ο ορισμός του προτύπου να είναι στο ίδιο αρχείο με τη χρήση του. Για το λόγο αυτό οι κλάσεις και οι συναρτήσεις που ορίζονται με βάση τα πρότυπα ορίζονται και δηλώνονται μέσα σε αρχείο επικεφαλίδων.
Πρότυπα συναρτήσεων
- Ο ορισμός συναρτήσεων με βάση ένα πρότυπο γίνεται με τη
σύνταξη:
template <δηλώσεις τύπων> δήλωση συνάρτησης με βάση τους τύπους
Το παρακάτω παράδειγμα ορίζει τη συνάρτηση swap που εναλλάσσει μεταξύ τους τις δύο μεταβλητές - ορίσματα της συνάρτησης:// File tswap.h template <class T> void swap(T &a, T &b) { T c; c = a; a = b; b = c; } - Η υλοποίηση της συνάρτησης γίνεται αυτόματα για τον τύπο για τον
οποίο χρησιμοποιείται:
// File swaptest.cpp #include <iostream.h> #include "tswap.h" main() { int a = 1, b = 2; double da = 1.1, db = 2.2; swap(a, b); // Swap two integers swap(da, db); // Swap two floating point numbers cout << a << "," << b << "\n"; cout << da << "," << db << "\n"; } - Μπορούμε ακόμα να καθορίσουμε κατά τη χρήση της συνάρτησης τον
τύπο της συνάρτησης που θέλουμε να χρησιμοποιηθεί αρκεί οι παράμετροι
να είναι συμβατοί (ακόμα και μέσω μετατροπών) με το συγκεκριμένο τύπο.
Το παρακάτω παράδειγμα θα τυπώσει 3:
#include <iostream.h> template <typename T> T max(T a, T b) { if (a > b) return (a); else return (b); } main() { cout << max<int>(3.1415, 1.4142) << "\n"; }
Πρότυπα κλάσεων
- Ο ορισμός κλάσεων με βάση πρότυπα επιτρέπει τον ορισμό συλλογών δεδομένων (όπως στοίβες, ουρές, πίνακες, κ.λπ.) ανεξάρτητα από το τελικό περιεχόμενό τους.
- Όταν ορίζουμε μεταβλητές με βάση μια τέτοια πρότυπη κλάση πρέπει να δίνουμε και συγκεκριμένη τιμή σε όλες τις παραμέτρους του προτύπου (π.χ. τον τύπο των στοιχείων που θέλουμε να αποθηκεύσουμε).
- Το παρακάτω παράδειγμα ορίζει μια πρότυπη κλάση για στοίβα με
πεπερασμένο μέγεθος καθώς και δύο αντικείμενα της κλάσης αυτής,
μια στοίβα 20 ακεραίων και έναν από 10 double.
#include <iostream.h> #include <assert.h> template <class T, int i> class tstack { private: T data[i]; int items; public: tstack(); void push(T item); T pop(void); void print(void); }; // Constructor template <class T, int i> tstack<T, i>::tstack(void) { items = 0; } template <class T, int i> void tstack<T, i>::push(T item) { assert(items < i); data[items++] = item; } template <class T, int i> T tstack<T, i>::pop(void) { assert(items > 0); return (data[--items]); } main() { tstack <int, 20> int_stack; tstack <double, 10> double_stack; int_stack.push(7); int_stack.push(45); double_stack.push(3.14); double_stack.push(1.41); cout << int_stack.pop() << "\n"; cout << int_stack.pop() << "\n"; cout << double_stack.pop() << "\n"; cout << double_stack.pop() << "\n"; }
Δείκτες σε μέλη κλάσεων
- Η C++ επιτρέπει τον ορισμό δεικτών σε μέλη (μεταβλητές ή συναρτήσεις)
μιας κλάσης.
Στο παρακάτω παράδειγμα η μεταβλητή coordptr ορίζεται ως δείκτης
σε ακέραιες μεταβλητές - μέλη - της κλάσης point.
class point { public: int x, y; }; int point::*coordptr; // Pointer to one of the two point coordinatesΗ μεταβλητή coordptr μπορεί να δείχνει στο μέλος x ή στο μέλος y. - Η μεταβλητή μπορεί να λάβει αρχική τιμή με τη σύνταξη
var = &(class_name::member_name);
Παράδειγμα:coordptr = &(point::x); // Coordptr points to the x coordinates
- Πρόσβαση στο αντίστοιχο μέλος μπορεί να υπάρξει μόνο με βάση ένα πραγματικό αντικείμενο ή δείκτη της συγκεκριμένης κλάσης με τους τελεστές .* και ->* αντίστοιχα. Αριστερά από τον τελεστή γράφεται το αντικείμενο ή ο δείκτης της κλάσης και δεξιά ο δείκτης στο μέλος της κλάσης.
- Το παρακάτω παράδειγμα ορίζει δύο μεταβλητές τύπου point και
δίνει αρχικές τιμές στα μέλη τους μέσω της coordptr η οποία αρχικά
δείχνει στα x και μετά στα y.
Έτσι, στο τέλος τυπώνει τις τιμές των σημείων ως (1, 2) και (10, 20).
#include <iostream.h> class point { public: int x, y; void print() { cout << x << "," << y << "\n"; } }; main() { int point::*coordptr; // Pointer to a point coordinate point p, p2; coordptr = &(point::x); // Coordptr points to the x coordinates p.*coordptr = 1; p2.*coordptr = 10; coordptr = &(point::y); // Coordptr now points to the y coordinates p.*coordptr = 2; p2.*coordptr = 20; p.print(); p2.print(); return (0); }
Η βιβλιοθήκη της C++
Η βιβλιοθήκη της C++
Η βιβλιοθήκη της C++ μπορεί να χωριστεί στις παρακάτω κατηγορίες:- Γενικές λειτουργίες
- Λειτουργίες μετατροπής και αρχείων (iostreams)
- Αλγόριθμοι με τη χρήση ενός επαναλήπτη (iterator) πάνω σε έναν περιέχοντα (container). Οι λειτουργίες αυτές αποτελούν τη βιβλιοθήκη με το όνομα Standard Template Library (STL).
- Συμβατότητα με τη C
using namespace std;Στις επόμενες ενότητες περιγράφουμε συνοπτικά μόνο τις γενικές λειτουργίες της βιβλιοθήκης και με περισσότερες λεπτομέρειες τις λειτουργίες της STL.
Γενικές λειτουργίες
Η γενικές λειτουργίες της βιβλιοθήκης της C++ είναι οι παρακάτω:- bitset
- κλάση προτύπων (ως προς το μέγιστο πληθάριθμο του συνόλου) που επεξεργάζεται σύνολο από bit
- complex
- κλάση προτύπων (ως προς τον τύπου των δύο στοιχείων) μιγαδικών αριθμών. Εξειδικεύσεις της κλάσης είναι μιγαδικοί αριθμοί float, double και long double.
- exception
- συναρτήσεις χειρισμού διακοπών
- limits
- ιδιότητες αριθμητικών τιμών
- locale
- προσαρμογή του προγράμματος σε τοπικά χαρακτηριστικά.
Περιλαμβάνονται πρότυπες κλάσεις που ορίζουν:
- τον τρόπο μετατροπής μεταξύ χαρακτήρων
- τη σειρά ταξινόμησης
- το χαρακτηρισμό χαρακτήρων
- τη μετατροπή νομισματικών τιμών
- τη μετατροπή αριθμητικών τιμών
- τη μετατροπή τιμών που παριστάνουν χρόνο
- τη μετατροπή μηνυμάτων προς το χρήστη
- stdexcept
- κλάσεις για αναφορά διακοπών
- string
- πρότυπη κλάση που ορίζει σειρές αντικειμένων μεταβλητού μήκους. Εξειδίκευση της κλάσης αυτής είναι οι συμβολοσειρές.
- valarray
- πρότυπη (ως προς το περιεχόμενο του πίνακα) κλάση που επιτρέπει το μαζικό χειρισμό πινάκων
Λειτουργίες μετατροπής και αρχείων
Οι επικεφαλίδες iostreams υποστηρίζουν τη μετατροπή μεταξύ κειμένων και της εσωτερική μορφή παράστασης των τύπων καθώς και είσοδο και έξοδο από και σε εξωτερικά αρχεία. Ορίζονται οι παρακάτω επικεφαλίδες:- fstream
- πρότυπες κλάσεις iostreams για το χειρισμό εξωτερικών αρχείων
- iomanip
- δήλωση χειριστών iostreams
- ios
- βασική κλάση προτύπων iostreams
- iosfwd
- δήλωση προτύπων κλάσεων iostreams πριν από τον ορισμό τους
- iostream
- δήλωση των βασικών αντικειμένων iostreams
- istream
- πρότυπη κλάση που εξάγει στοιχεία
- ostream
- πρότυπη κλάση που εισάγει στοιχεία
- sstream
- πρότυπες κλάσεις iostreams που αναφέρονται σε συμβολοσειρές
- streambuf
- πρότυπες κλάσεις που προσφέρουν ενταμιευτές σε κλάσεις iostreams
- strstream
- κλάσεις iostreams που λειτουργούν σε στοιχεία που βρίσκονται στη μνήμη
Περιέχοντες και επαναλήπτες στην STL
Η STL ορίζει μια σειρά από περιέχοντες (containers) όπως την ουρά, τη στοίβα, την απεικόνιση και τον πίνακα. Πάνω στους περιέχοντες αυτούς επιτρέπει την εκτέλεση αλγορίθμων, όπως την εύρεση ενός στοιχείου, η ένωση δύο περιεχόντων, η ταξινόμηση, κ.λπ.Στην STL ορίζονται οι παρακάτω πρότυποι (ως προς τα στοιχεία που περιέχουν) περιέχοντες:
- list
- διπλά συνδεδεμένη λίστα
- queue
- ουρά
- deque
- ουρά με πρόσβαση και στις δύο άκρες
- map
- απεικόνιση (π.χ. από συμβολοσειρές σε ακέραιους)
- set
- απεικόνιση με μοναδικά στοιχεία στο πεδίο τιμών
- stack
- στοίβα
- vector
- πίνακας
- Τυχαία προσπέλαση
- Κίνηση προς τις δύο κατευθύνσεις
- Κίνηση προς τα εμπρός, ή ανάποδη κίνηση
- Είσοδο και έξοδο
- Μόνο είσοδο, ή μόνο έξοδο
- advance
- distance
- ==, !=, <, >, >=, <=
- +, -
- ++, --
- assign
- ανάθεση τιμής
- at
- αναφορά σε στοιχείο
- back
- το τελευταίο στοιχείο
- begin
- επαναλήπτης που δείχνει στην αρχή της δομής
- clear
- διαγραφή όλων των στοιχείων
- empty
- αληθές αν η δομή είναι άδεια
- end
- επαναλήπτης που δείχνει στο τέλος της δομής
- erase
- διαγραφή σειράς στοιχείων
- front
- το πρώτο στοιχείο
- insert
- προσθήκη στοιχείου
- operator[]
- πρόσβαση σε στοιχείο
- pop_back
- αφαίρεση στοιχείου από το τέλος
- pop_front
- αφαίρεση στοιχείου από την αρχή
- push_back
- προσθήκη στοιχείου στο τέλος
- push_front
- προσθήκη στοιχείου στην αρχή
- rbegin
- ανάστροφος επαναλήπτης που δείχνει στην αρχή της δομής
- rend
- ανάστροφος επαναλήπτης που δείχνει στο τέλος της δομής
- resize
- καθορισμός του αριθμού των στοιχείων
- size
- αριθμός των στοιχείων
- swap
- εναλλαγή δύο στοιχείων μεταξύ τους
#include <iostream>
#include <deque>
using namespace std;
typedef deque <int> INTDEQUE;
void main()
{
// Create A and fill it with elements 1,2,3,4 and 5
// using push_back function
INTDEQUE A;
A.push_back(1);
A.push_back(2);
A.push_back(3);
A.push_back(4);
A.push_back(5);
// Print the contents of A using iterator
// and functions begin() and end()
INTDEQUE::iterator pi;
for (pi = A.begin(); pi != A.end(); pi++)
cout << *pi << " ";
cout << "\n";
}
Πρόσθετες λειτουργίες στην STL
Επικεφαλίδα algorithm
Στην επικεφαλίδα algorithm ορίζονται μέθοδοι που ενεργούν πάνω σε περιέχοντες:- adjacent_find
- βρίσκει δύο ίσα στοιχεία σε διπλανές θέσεις
- binary_search
- δυαδική ανίχνευση
- copy
- αντιγραφή περιοχής
- copy_backward
- αντίστροφη αντιγραφή περιοχής
- count
- μέτρημα
- count_if
- μέτρημα υπό συνθήκη
- equal
- σύγκριση περιοχών
- equal_range
- σύγκριση περιοχών με συγκεκριμένη ακρίβεια
- fill
- πλήρωση περιοχής με τιμή
- fill_n
- πλήρωση αριθμού στοιχείων με τιμή
- find
- εύρεση στοιχείου
- find_end
- εύρεση στοιχείου από το τέλος
- find_first_of
- εύρεση στοιχείου ίσου με κάποιο μέλος από σύνολο στοιχείων
- find_if
- εύρεση στοιχείου που να ικανοποιεί συνθήκη
- for_each
- εκτέλεση συνάρτησης για όλα τα στοιχεία σε περιοχή
- generate
- πλήρωση περιοχής με αποτέλεσμα συνάρτησης
- generate_n
- πλήρωση αριθμού στοιχείων με αποτέλεσμα συνάρτησης
- includes
- έλεγχος αν μια περιοχή εμπεριέχει μια άλλη
- inplace_merge
- σύζευξη δεδομένων στον ίδιο περιέχοντα
- iter_swap
- εναλλαγή δύο τιμών
- lexicographical_compare
- σύγκριση δύο περιοχών α, β για α < β
- lower_bound
- εύρεση μιας ελάχιστης τιμής σε περιοχή σε σχέση με μιαν άλλη τιμή
- make_heap
- μετατροπή περιοχής σε σωρό (heap) (δυαδικό δένδρο στο οποίο τα παιδιά έχουν τιμή μικρότερη ή ίση από αυτή των γονέων τους).
- max
- το μέγιστο από δύο στοιχεία
- max_element
- εύρεση του μέγιστου στοιχείου σε περιοχή
- merge
- σύζευξη δύο περιοχών σε τρίτη
- min
- το ελάχιστο από δύο στοιχεία
- min_element
- εύρεση του ελαχίστου στοιχείου σε περιοχή
- mismatch
- εύρεση του πρώτου διαφορετικού στοιχείου ανάμεσα σε δύο περιοχές
- next_permutation
- υπολογισμός της επόμενης μετάθεσης σε μια περιοχή
- nth_element
- θέτει ένα στοιχείο στη θέση που θα έπρεπε να έχει αν η περιοχή ήταν ταξινομημένη
- partial_sort
- ταξινομεί τα πρώτα στοιχεία μιας περιοχής
- partial_sort_copy
- ταξινομεί τα πρώτα στοιχεία μιας περιοχής σε μιαν άλλη
- partition
- χωρίζει μια περιοχή στα δύο με βάση μια συνάρτηση και επιστρέφει το σημείο που είναι ο χωρισμός
- pop_heap
- αφαίρεση στοιχείου από σωρό
- prev_permutation
- υπολογισμός της προηγούμενης μετάθεσης σε μια περιοχή
- push_heap
- προσθήκη στοιχείου από σωρό
- random_shuffle
- ανακατεύει μια περιοχή
- remove
- αφαιρεί στοιχεία ίσα με μια τιμή
- remove_copy
- αφαιρεί στοιχεία ίσα με μια τιμή μεταφέροντας το αποτέλεσμα σε μιαν άλλη περιοχή
- remove_copy_if
- αφαιρεί στοιχεία για τα οποία μια συνάρτηση είναι αληθής μεταφέροντας το αποτέλεσμα σε μιαν άλλη περιοχή
- remove_if
- αφαιρεί στοιχεία για τα οποία μια συνάρτηση είναι αληθής
- replace
- αλλάζει τιμή σε στοιχεία ίσα με μια τιμή
- replace_copy
- αλλάζει τιμή σε στοιχεία ίσα με μια τιμή μεταφέροντας το αποτέλεσμα σε μιαν άλλη περιοχή
- replace_copy_if
- αλλάζει τιμή σε στοιχεία για τα οποία μια συνάρτηση είναι αληθής μεταφέροντας το αποτέλεσμα σε μιαν άλλη περιοχή
- replace_if
- αλλάζει τιμή σε στοιχεία για τα οποία μια συνάρτηση είναι αληθής
- reverse
- αντιστρέφει τη σειρά σε μια περιοχή
- reverse_copy
- αντιστρέφει τη σειρά σε μια περιοχή μεταφέροντάς την σε μιαν άλλη περιοχή
- rotate
- περιστρέφει τη σειρά των στοιχείων σε μια περιοχή
- rotate_copy
- περιστρέφει τη σειρά των στοιχείων σε μια περιοχή μεταφέροντάς την σε μιαν άλλη περιοχή
- search
- εύρεση σειράς στοιχείων σε μια περιοχή ίσης με στοιχεία μιας άλλης
- search_n
- εύρεση σειράς στοιχείων σε μια περιοχή ίσης με αριθμό στοιχείων μιας άλλης
- set_difference
- θέτει μια περιοχή ίση με τη διαφορά των στοιχείων δύο άλλων περιοχών (διαφορά συνόλων)
- set_intersection
- θέτει μια περιοχή ίση με την τομή των στοιχείων δύο άλλων περιοχών (τομή συνόλων)
- set_symmetric_difference
- θέτει μια περιοχή ίση με τα μη κοινά των στοιχείων δύο άλλων περιοχών
- set_union
- θέτει μια περιοχή ίση με την ένωση των στοιχείων δύο άλλων περιοχών (ένωση συνόλων)
- sort
- ταξινομεί μια περιοχή
- sort_heap
- ταξινομεί έναν σωρό
- stable_partition
- χωρίζει μια περιοχή στα δύο με βάση μια συνάρτηση και επιστρέφει το σημείο που είναι ο χωρισμός. Ο χωρισμός γίνεται χωρίς να αλλάξει η σχετική σειρά των στοιχείων.
- stable_sort
- ταξινομεί μια περιοχή. Η ταξινόμηση γίνεται χωρίς να αλλάξει η σχετική σειρά των στοιχείων που είναι μεταξύ τους ίσα.
- swap
- αντιστρέφει μεταξύ τους δύο στοιχεία
- swap_ranges
- αντιστρέφει μεταξύ τους δύο περιοχές
- transform
- εφαρμόζει έναν τελεστή σε μια περιοχή ή μεταξύ δύο περιοχών
- unique
- αφαιρεί τα όμοια στοιχεία από μια περιοχή
- unique_copy
- αφαιρεί τα όμοια στοιχεία από μια περιοχή μεταφέροντάς την σε μιαν άλλη περιοχή
- upper_bound
- εύρεση μιας μέγιστης τιμής σε περιοχή σε σχέση με μια άλλη τιμή
Επικεφαλίδα numeric
Στην επικεφαλίδα algorithm ορίζονται αριθμητικές μέθοδοι που ενεργούν πάνω σε περιέχοντες:- accumulate
- υπολογίζει ένα σύνολο πάνω σε μια περιοχή
- adjacent_difference
- υπολογίζει τις διαφορές τιμών μεταξύ στοιχείων μιας περιοχής
- inner_product
- υπολογίζει ένα εσωτερικό γινόμενο μεταξύ δύο περιοχών
- partial_sum
- υπολογίζει ένα μερικό άθροισμα τιμών μιας περιοχής σε μιαν άλλη
Άλλες επικεφαλίδες
Ακόμα στην STL ορίζονται οι παρακάτω επικεφαλίδες:- utility
- πρότυπη κλάση που ορίζει διάταξη σε ζεύγη τιμών
- functional
- κλάση που επιτρέπει συναρτησιακό προγραμματισμό
- memory
- ορίζει την κλάση allocator η οποία κατανέμει τη μνήμη σε όλους τους περιέχοντες. Ο επανακαθορισμός της επιτρέπει την υλοποίηση άλλων στρατηγικών καταμερισμού και πρόσβασης στη μνήμη.
Συμβατότητα με τη C
Ακόμα παρέχονται επικεφαλίδες που παρέχουν υπηρεσίες όμοιες με τις αντίστοιχες της γλώσσας C. Καλό είναι οι επικεφαλίδες αυτές να χρησιμοποιούνται μόνο όταν απαιτείται συμβατότητα με κληρονομημένο (legacy) (παλιό) κώδικα.- cassert
- απόδειξη ιδιοτήτων κατά την εκτέλεση συναρτήσεων
- cctype
- χαρακτηρισμός χαρακτήρων
- cerrno
- πρόσβαση στα λάθη από την εκτέλεση συναρτήσεων της βιβλιοθήκης
- cfloat
- ιδιότητες αριθμών κινητής υποδιαστολής
- ciso646
- ορισμός λέξεων που επιτρέπουν τον προγραμματισμό σε συστήματα με τις κωδικοσελίδες ISO 646 (δεν αφορά την Ελλάδα)
- climits
- ιδιότητες των ακεραίων
- clocale
- προσαρμογή του προγράμματος σε τοπικά χαρακτηριστικά
- cmath
- μαθηματικές συναρτήσεις
- csetjmp
- αδόμητη μετάβαση ελέγχου μεταξύ συναρτήσεων
- csignal
- έλεγχος διακοπών
- cstdarg
- πρόσβαση σε ορίσματα με μεταβλητό αριθμό παραμέτρων
- cstddef
- ορισμός χρησίμων τύπων
- cstdio
- είσοδος και έξοδος όμοια με τη C
- cstdlib
- πρόσβαση στις αντίστοιχες συναρτήσεις της C
- cstring
- επεξεργασία συμβολοσειρών της C
- ctime
- χρήση ώρας και ημερομηνίας
- cwchar
- επεξεργασία "πλατιών" χαρακτήρων
- cwctype
- χαρακτηρισμός "πλατιών" χαρακτήρων
Βιβλιογραφία
- P.J. Plauger, Alexander Stepanov, Meng Lee, and David R. Musser, The Standard Template Library (Englewood Cliffs NJ: Prentice Hall, 1997).
- ANSI Standard X3.159-1989 (New York NY: American National Standards Institute, 1989).
- P.J. Plauger, The Standard C Library (Englewood Cliffs NJ: Prentice Hall, 1992).
- P.J. Plauger and Jim Brodie, Standard C: A Programmer's Reference (Redmond WA: Microsoft Press, 1989).
- P.J. Plauger and Jim Brodie, Standard C (Englewood Cliffs NJ: PTR Prentice Hall, 1996).
- P.J. Plauger, The Draft Standard C++ Library (Englewood Cliffs NJ: Prentice Hall, 1995).
Ασκήσεις
Άσκηση 9
- Με βάση τον περιέχοντα της STL queue και μονοτονικά αυξανόμενη μεταβλητή
να υλοποιηθεί πρόγραμμα το οποίο να υλοποιεί ουρά εξυπηρέτησης πελατών
ως εξής:
- Όταν εισάγεται ο χαρακτήρας I (In) το πρόγραμμα τυπώνει τον αριθμό προτεραιότητας του νέου πελάτη.
- Όταν εισάγεται ο χαρακτήρας O (Out) το πρόγραμμα τυπώνει τον αριθμό προτεραιότητας του επόμενου πελάτη που θα εξυπηρετηθεί.
I 1 I 2 I 3 O 1 I 4 O 2 ...
Ολοκληρωμένα περιβάλλοντα ανάπτυξης
Εισαγωγή
- Η διαδικασία της κωδικοποίησης είναι περίπλοκη και χρονοβόρα.
- Για τη διευκόλυνσή της έχουν σχεδιαστεί και αναπτυχθεί περιβάλλοντα υποστήριξης της κωδικοποίησης (programming support environments).
- Σε ένα περιβάλλον υποστήριξης της κωδικοποίησης όλος ο κύκλος της
κωδικοποίησης από την αρχική εισαγωγή του προγράμματος μέχρι την τελική
αποσφαλμάτωση υποστηρίζεται από ένα ολοκληρωμένο σύστημα.
Έτσι ένα περιβάλλον υποστήριξης της κωδικοποίησης μπορεί να περιέχει
σε ένα ολοκληρωμένο περιβάλλον:
- έξυπνο διορθωτή,
- μεταγλωττιστή,
- συνδέτη,
- αποσφαλματωτή,
- ψηφιακή τεκμηρίωση,
- σύστημα υπολογισμού της σειράς μεταγλώττισης,
- σύστημα σχεδιασμού της διεπαφής με το χρήστη,
- φυλλομετρητή του πηγαίου κώδικα (source code browser) και φυλλομετρητή των κλάσεων (class browser),
- υπολογιστή κατανομής (profiler) του κόστους της επεξεργασίας μέσα στο πρόγραμμα.
- Υπερσύνολο του περιβάλλοντος υποστήριξης της κωδικοποίησης
αποτελεί το
περιβάλλον τεχνολογίας λογισμικού (software engineering environment)
το οποίο παρέχει υποστήριξη για όλον το κύκλο ζωής του λογισμικού
συμπεριλαμβάνοντας δηλαδή υποστήριξη για
- την ανάλυση των απαιτήσεων,
- το σχεδιασμό,
- την κωδικοποίηση,
- τη διοίκηση του έργου,
- τον έλεγχο των εκδόσεων και του σχηματισμού,
- τη διαχείριση εξαρτημάτων λογισμικού (software components),
- τη διασφάλιση ποιότητας και
- τη συντήρηση.
- Η τάση που εμφανίζεται είναι τα περιβάλλοντα υποστήριξης της κωδικοποίησης τα περιέχουν όλο και περισσότερα στοιχεία από περιβάλλοντα τεχνολογίας λογισμικού ενώ παράλληλα περιβάλλοντα τεχνολογίας λογισμικού να υποστηρίζουν όλο και περισσότερο την κωδικοποίηση με τη χρήση γεννητριών κώδικα.
Ο διορθωτής
Ο διορθωτής σε ένα ολοκληρωμένο περιβάλλον ανάπτυξης περιλαμβάνει ισχυρές δυνατότητες εισαγωγής του κώδικα καθώς και δυνατότητες που σχετίζονται με τη γλώσσα προγραμματισμού όπως:- αυτόματη στοίχιση,
- συντακτικό χρωματισμό του κειμένου,
- εμφάνιση του ορίσματος των συναρτήσεων,
- συντακτικό έλεγχο,
- αναίρεση πολλαπλών επιπέδων,
- σελιδοδείκτες,
- σύνδεση με το σύστημα τεκμηρίωσης,
- ταυτόχρονη διόρθωση πολλών αρχείων,
- εύρεση κειμένου σε αρχεία,
- αυτόματη μορφοποίηση του προγράμματος
- κουμπί εντολής (command button)
- πλαίσιο (frame)
- εισαγωγή κειμένου (edit box)
- μπάρα κύλισης (scrollbar)
- κείμενο,
- δείκτης προόδου (progress bar)
Το σύστημα βοήθειας
Το σύστημα βοήθειας περιλαμβάνει συχνά σε ψηφιακή μορφή τεκμηρίωση για:- τη γλώσσα προγραμματισμού,
- τη βιβλιοθήκη,
- το περιβάλλον ανάπτυξης και τα εργαλεία που το απαρτίζουν,
- τεκμηρίωση για τη διαδικασία ανάπτυξης εφαρμογών,
- οδηγίες συμβατότητας,
- απαντήσεις σε συχνές ερωτήσεις,
- διαπιστωμένα σφάλματα του περιβάλλοντος.
Μερικές φορές το σύστημα βοηθείας συμπληρώνεται από
οδηγούς (wizards) που επιτρέπουν με διαλογικό
τρόπο τη βήμα με βήμα ανάπτυξη μιας εφαρμογής.
Τα παρακάτω σχήμα παριστάνει ένα στάδιο από την εκτέλεση ενός
οδηγού:
Συχνά υπάρχει άμεση σύνδεση του διορθωτή με το σύστημα βοήθειας έτσι ώστε την ώρα που π.χ. πληκτρολογούμε την κλήση σε μια συνάρτηση της βιβλιοθήκης να μπορούμε να δούμε τον ορισμό της.
Η διαδικασία μεταγλώττισης
Η διαδικασία της μεταγλώττισης περιλαμβάνει αρκετές ευκολίες σε ένα ολοκληρωμένο περιβάλλον.- Υπολογίζονται αυτόματα τα αρχεία που απαιτούν μεταγλώττιση ανάλογα με τις αλλαγές που έγιναν σε αρχεία επικεφαλίδων.
- Η εμφάνιση ενός λάθους επιτρέπει την άμεση σύνδεσή του με τη γραμμή
του κώδικα που το δημιούργησε όπως φαίνεται στην παρακάτω οθόνη:
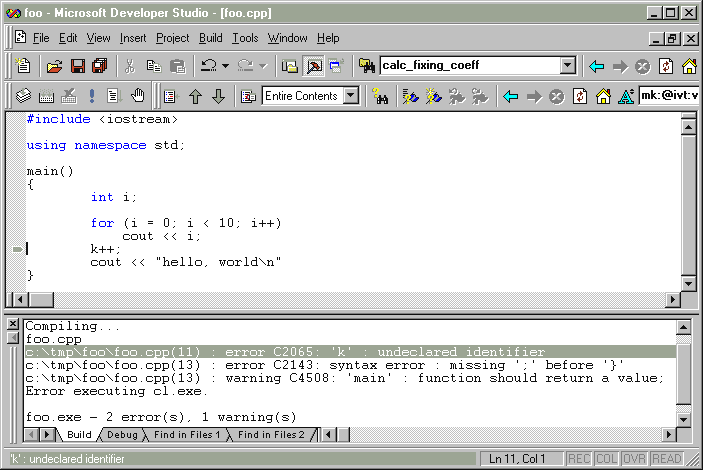
- Επιτρέπει την εμφάνιση τεκμηρίωσης σχετικά με τα λάθη που εμφανίζονται.
Αποσφαλμάτωση
Ο αποσφαλματωτής επιτρέπει τον πλήρη έλεγχο της ροής εκτέλεσης και των δεδομένων του προγράμματος που εκτελείται. Περιλαμβάνει δυνατότητες όπως:- τη γραμμή προς γραμμή εκτέλεση του προγράμματος,
- την εμφάνιση της τιμής των μεταβλητών,
- τη διακοπή της εκτέλεσης του προγράμματος σε μια συγκεκριμένη γραμμή,
- τη διακοπή της εκτέλεσης του προγράμματος όταν αλλάξει τιμή μια μεταβλητή,
- την εκτέλεση μια ολόκληρης συνάρτησης,
- την εμφάνιση της τιμής μιας έκφρασης,
- την εκτέλεση του προγράμματος μέχρι ένα ορισμένο σημείο,
- την εμφάνιση της στοίβας κλήσεων (call stack) των συναρτήσεων,
- την εμφάνιση των καταχωρητών και της μνήμης του επεξεργαστή,
- την εμφάνιση του πηγαίου κώδικα καθώς και του συμβολικού κώδικα,
- τη δυναμική αλλαγή του πηγαίου κώδικα κατά τη διάρκεια της εκτέλεσης.
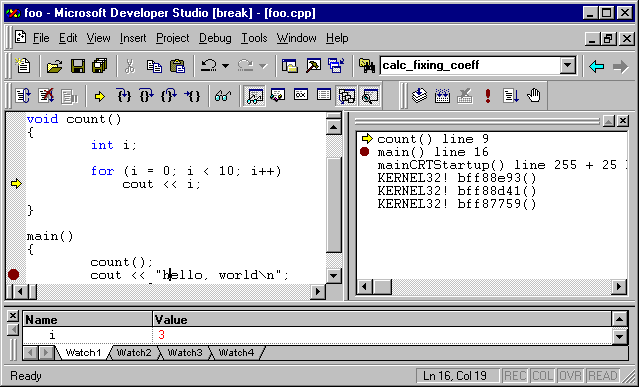
Φυλλομέτρηση πηγαίου κώδικα και κλάσεων
Συνδεδεμένο με το διορθωτή είναι συχνά ένα εργαλείο που επιτρέπει τη φυλλομέτρηση και την εμφάνιση της δομής του κώδικα και των κλάσεων που τον απαρτίζουν. Δυνατότητες του φυλλομετρητή μπορεί να είναι οι παρακάτω:- εμφάνιση ορισμών και παραπομπών (references),
- εμφάνιση της δομής ενός αρχείου,
- εμφάνιση των βασικών κλάσεων και των μελών τους,
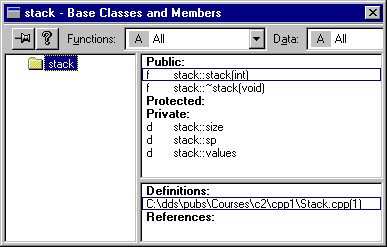
- εμφάνιση του δένδρου της δομής των κλάσεων,
- εμφάνιση του γράφου των καλούντων (call graph) συναρτήσεων,
- εμφάνιση του γράφου των καλούμενων (callers graph) συναρτήσεων,
Βιβλιογραφία
- Εμμανουήλ Σκορδαλάκης.
Εισαγωγή στην Τεχνολογία Λογισμικού σ. 241-295.
Συμμετρία, 1991.
- Charles Rich and Richard C. Waters, editors. Readings in Artifical Intelligence and Software Engineering. Morgan Kaufmann, 95 First Street, Los Altos, California 94022, 1986.
- Ian Sommerville. Software Engineering. Addison-Wesley, third edition, 1989.
Αντικειμενοστρεφής σχεδιασμός με UML
Εισαγωγή
Η ενοποιημένη γλώσσα σχεδιασμού (unified modeling language) (UML) είναι μια γραφική γλώσσα για την οπτική παράσταση, τη διαμόρφωση προδιαγραφών και την τεκμηρίωση συστημάτων που βασίζονται σε λογισμικό. Η UML στοχεύει στο σχεδιασμό αντικειμενοστρεφών συστημάτων. Το σχέδιο είναι μια απλοποιημένη παράσταση της πραγματικότητας.Σχεδιάζουμε για να μπορέσουμε να καταλάβουμε το σύστημα που αναπτύσσουμε. Έτσι δημιουργώντας ένα σχέδια επιτυγχάνουμε τέσσερις στόχους:
- παριστάνουμε οπτικά το σύστημα που έχουμε ή θέλουμε να κατασκευάσουμε,
- προσδιορίζουμε τη δομή και τη συμπεριφορά του συστήματος,
- δημιουργούμε ένα πρότυπο για να βασίσουμε την κατασκευή του συστήματος,
- τεκμηριώνουμε τις αποφάσεις που λάβαμε.
Σε όλους τους τεχνολογικούς τομείς ο σχεδιασμός βασίζεται σε τέσερις βασικές αρχές:
- η επιλογή του είδους του σχεδίου έχει επίπτωση στον τρόπο και την μορφή επίλυσης του προβλήματος,
- όλα τα σχέδια εκφράζονται σε διαφορετικές βαθμίδες ακρίβειας,
- τα καλύτερα σχέδια σχετίζονται με την πραγματικότητα,
- ένα είδος σχεδίων δεν είναι ποτέ αρκετό.
Η UML περιλαμβάνει τρία βασικά στοιχεία:
- Οντότητες
- Σχέσεις
- Διαγράμματα
Κλάσεις
- Μια κλάση σχεδιάζεται ως ένα ορθογώνιο με τρία τμήματα όπως
στο παρακάτω σχήμα:

- Τα ονόματα των ιδιοτήτων και μεθόδων της κλάσης μπορούν να
έχουν ένα πρόθεμα ανάλογα με την ορατότητά τους:
- +
- public
- #
- protected
- -
- private
- Οι μεταβλητές και οι συναρτήσεις που αναφέρονται στην κλάση και όχι σε αντικείμενά της (static στη C++) σχεδιάζονται υπογραμμισμένες.
- Οι αφηρημένες κλάσεις έχουν το όνομά τους γραμμένο με πλάγια στοιχεία.
- Το σχήμα που ακολουθεί αποτελεί σχέδιο για μια απλή κλάση στοίβας
ακεραίων:
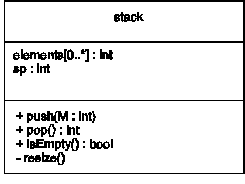
Σχέσεις
Στη UML ορίζονται τρεις βασικές σχέσεις:
Εξάρτηση
Η εξάρτηση δηλώνει πως μια αλλαγή σε μιαν οντότητα θα επηρεάσει μιαν άλλη αλλά όχι απαραίτητα και το αντίστροφο. Παριστάνεται με μια διακεκομμένη γραμμή με ανοιχτό βέλος που δείχνει προς την οντότητα που υπάρχει εξάρτηση:
Γενίκευση
Η γενίκευση δηλώνει μια σχέση ανάμεσα σε κάτι γενικό (τη βασική κλάση ή αλλιώς γονέα) και κάτι ειδικό (μιαν υποκλάση ή αλλιώς παιδί της). Παριστάνεται με μια συνεχή γραμμή με κλειστό βέλος που δείχνει προς τη βασική κλάση:
Σύνδεση
Η σύνδεση αναφέρεται σε αντικείμενα τα οποία συνδέονται με κάποιο τρόπο με άλλα. Όταν δύο κλάσεις είναι συνδεδεμένες μπορεί κανείς να μεταβεί από αντικείμενα της μιας σε αντικείμενα της άλλης. Η σύνδεση παριστάνεται με μια ευθεία γραμμή ανάμεσα στα δύο αντικείμενα.- Αν η σύνδεση δεν είναι αμφίδρομη τότε η κατεύθυνσή της μπορεί να οριστεί με ένα ανοιχτό βέλος.
- Το όνομα της σύνδεσης μπορεί να γραφεί πάνω από τη γραμμή, ενώ η κατεύθυνση του ονόματος ορίζεται από ένα βέλος πλάι στο όνομα.
- Ο ρόλος των οντοτήτων που συνδέονται προσδιορίζεται από ένα όνομα στην κάθε άκρη της γραμμής.
- Ο αριθμός που δηλώνει πόσα αντικείμενα αντιστοιχούν σε κάθε αντικείμενο στην άλλη άκρη της σχέσης (πολλαπλότητα (multiplicity)) δηλώνεται από έναν αριθμό (π.χ. 3), ή μια περιοχή αριθμών (π.χ. 1..* για ένα έως πολλά) πάνω από την αντίστοιχη άκρη της γραμμής.

Αν σε μια σχέση τα αντικείμενα απαρτίζουν τμήματα ενός όλου, τότε
αυτή απεικονίζεται ως συγκρότημα (aggregation)
με την παράσταση ενός διαμαντιού στην άκρη του "όλου".
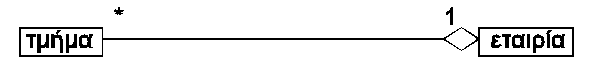
Αν σχέση τα αντικείμενα που απαρτίζουν τμήματα ενός όλου έχουν
την ίδια διάρκεια ζωής με το όλο, τότε
αυτή απεικονίζεται ως σύνθεση (composition)
με την παράσταση ενός γεμάτου διαμαντιού στην άκρη του "όλου".

Διάγραμμα κλάσεων
Το διάγραμμα των κλάσεων ενός συστήματος περιέχει τις κλάσεις μαζί με του αντίστοιχους δεσμούς εξάρτησης, γενίκευσης και σύνδεσης. Έτσι ένα διάγραμμα κλάσεων μπορεί να απεικονίσει τη χρήση της κληρονομικότητας στο σχεδιασμό με τη χρήση δεσμών γενίκευσης όπως στο παρακάτω σχήμα: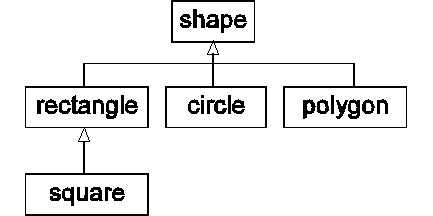
Διάγραμμα αντικειμένων
Τα διαγράμματα αντικειμένων χρησιμοποιούνται για το σχεδιασμό της στατικής κατάστασης του συστήματος κατά μια συγκεκριμένη χρονική στιγμή. Κάθε αντικείμενο σχεδιάζεται ως ένα ορθογώνιο με την παρακάτω μορφή:
Το σύνολο των αντικειμένων σχεδιάζεται με βάση τους συνδέσμους που
ορίζονται πάνω σε αυτό.
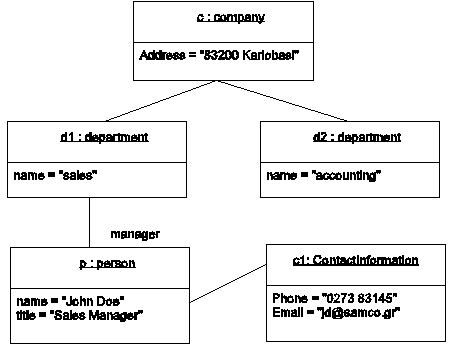
Βιβλιογραφία
- Grady Booch, James Rumbaugh, and Ivar Jacobson. The Unified Modeling Language User Guide. Addison-Wesley, 1999.
- James Rumbaugh, Ivar Jacobson, and Grady Booch. The Unified Modeling Language Reference Manual. Addison-Wesley, 1999.
- Roel Wieringa. A survey of structured and object-oriented software specification methods and techniques. ACM Computing Surveys, 30(4):459–527, December 1998.
Χειρισμός δεδομένων με SQL
Το σχεσιακό μοντέλο δεδομένων
Ένα σύστημα διαχείρισης βάσης δεδομένων (ΣΔΒΔ) (database management system (DBMS)) αποτελείται από ένα σύνολο δεδομένων και προγράμματα πρόσβασης στα δεδομένα αυτά. Το σύνολο των δεδομένων καλείται βάση δεδομένων (database). Στόχος του ΣΔΒΔ είναι η εύκολη και γρήγορη χρήση και ανάκτηση των δεδομένων. Η διαχείριση των δεδομένων περιλαμβάνει:- τον ορισμό δομών για τη αποθήκευση των δεδομένων
- τον ορισμό μεθόδων για τη διαχείριση των δεδομένων
Το σχεσιακό μοντέλο (relational model) δεδομένων παριστάνει δεδομένα και τις σχέσεις τους ως ένα σύνολο πινάκων. Κάθε πίνακας (table) αποτελείται από στήλες (columns) με μοναδικά ονόματα. Μια γραμμή (row) του πίνακα παριστάνει μια σχέση (relationship) ανάμεσα σε ένα σύνολο από τιμές. Ο πίνακας που ακολουθεί παριστάνει έναν τηλεφωνικό κατάλογο. Αποτελείται από δύο στήλες και πέντε γραμμές.
| Όνομα | Τηλέφωνο |
| Γιώργος | 32560 |
| Μαρία | 61359 |
| Θανάσης | 98756 |
| Λίνα | 78999 |
| Πέτρος | 12356 |
Η SQL (structured query language) αποτελεί σήμερα την πιο διαδεδομένη γλώσσα διαχείρισης σχεσιακών βάσεων δεδομένων. Η SQL παρέχει δυνατότητες για:
- τον ορισμό, τη διαγραφή και τη μεταβολή πινάκων και κλειδιών,
- τη σύνταξη ερωτήσεων (queries),
- την εισαγωγή, διαγραφή και μεταβολή στοιχείων,
- τον ορισμό όψεων (views) πάνω στα δεδομένα,
- τον ορισμό δικαιωμάτων πρόσβασης,
- τον έλεγχο της ακεραιότητας των στοιχείων,
- τον έλεγχο συναλλαγών (transaction)
Η SQL είναι ορισμένη ως διεθνές πρότυπο. Στις επόμενες ενότητες θα εξετάσουμε ένα υποσύνολο της SQL όπως υποστηρίζεται από την εγκατεστημένη στα εργαστήρια βάση δεδομένων Microsoft Access.
Στην περιγραφή της σύνταξης της SQL θα χρησιμοποιήσουμε τα παρακάτω σύμβολα:
- [ έκφραση ]
- η έκφραση εμφανίζεται προαιρετικά
- έκφραση1 | έκφραση2
- μπορεί να γραφεί η έκφραση1 ή η έκφραση2
- έκφραση ...
- η έκφραση μπορεί να επαναληφθεί
Τύποι δεδομένων
Τα δεδομένα κάθε στήλης ενός πίνακα πρέπει να έχουν ένα συγκεκριμένο τύπο. Οι βασικοί τύποι που υποστηρίζονται από την SQL είναι οι παρακάτω:- ΒΙΤ
- Ναι ή Όχι
- CURRENCY
- Τιμή που παριστάνει με ακρίβεια αριθμούς από 922.337.203.685.477,5808 έως 922.337.203.685.477,5807
- DATETIME
- Χρόνος
- SINGLE
- Αριθμός κινητής υποδιαστολή μονής ακρίβειας
- DOUBLE
- Αριθμός κινητής υποδιαστολή διπλής ακρίβειας
- SHORT
- Ακέραιος 2 byte (-32768 έως 32767)
- LONG
- Ακέραιος 4 byte (-2.147.483.648 έως 2.147.483.647)
- TEXT
- Κείμενο μέχρι 255 χαρακτήρες
- LONGTEXT
- Κείμενο μέχρι 1.2GB
Δημιουργία πινάκων
Νέοι πίνακες δημιουργούνται με την εντολή CREATE TABLE. Αυτή συντάσσεται ως εξής:CREATE TABLE όνομα_πίνακα (πεδίο1 τύπος [(μέγεθος)] [, πεδίο2 τύπος [(μέγεθος)] [, ...]]Για παράδειγμα η εντολή
CREATE TABLE Customer (Name TEXT (20), AccountNum SHORT)δημιουργεί τον πίνακα με όνομα Customer και με δύο στήλες: την Name και την AccountNum.
Αλλαγές σε πίνακες
Η εντολή ALTER TABLE επιτρέπει την προσθήκη νέων στηλών ή τη διαγραφή υπαρχόντων. Η προσθήκη νέων στηλών γίνεται με τη σύνταξη:ALTER TABLE όνομα_πίνακα ADD COLUMN πεδίο τύπος[(μέγεθος)]Για παράδειγμα η εντολή:
ALTER TABLE Customer ADD COLUMN Notes TEXT(25)προσθέτει μια νέα στήλη στον πίνακα Customer.
Η διαγραφή υπαρχόντων στηλών γίνεται με τη σύνταξη:
ALTER TABLE όνομα_πίνακα DROP COLUMN πεδίοΓια παράδειγμα η εντολή:
ALTER TABLE Customer DROP COLUMN Notesαφαιρεί τη στήλη Notes από τον πίνακα Customer.
Τέλος, η εντολή DROP TABLE επιτρέπει τη διαγραφή πινάκων. Για παράδειγμα η εντολή
DROP TABLE Customerθα διαγράψει τον πίνακα Customer
Δείκτες
Η πρόσβαση στα στοιχεία ενός πίνακα γίνεται ταχύτερα όταν αυτά οργανωθούν με τη βοήθεια δεικτών. Ένας δείκτης ορίζεται για μια συγκεκριμένη στήλη ή στήλες και επιτρέπει τη γρήγορη πρόσβαση σε γραμμές με βάση τιμές της συγκεκριμένης στήλης. Ουσιαστικά όταν ορίζουμε έναν δείκτη το ΣΔΒΔ υλοποιεί μια δομή δεδομένων (π.χ. ταξινομημένο ή κατακερματισμένο πίνακα ή δένδρο) για γρήγορη πρόσβαση στα αντίστοιχα δεδομένα. Δείκτες δημιουργούνται με την εντολή CREATE INDEX. Η σύνταξή της είναι η παρακάτω:CREATE [ UNIQUE ] INDEX όνομα_δείκτη ON όνομα_πίνακα (πεδίο [ASC|DESC][, πεδίο [ASC|DESC], ...])Η λέξη UNIQUE ορίζει πως δε θα επιτρέπονται διπλές εμφανίσεις μιας τιμής για το συγκεκριμένο δείκτη. Οι λέξεις ASC και DESC ορίζουν αύξουσα ή φθίνουσα ταξινόμηση του πίνακα με βάση το δείκτη. Παράδειγμα:
CREATE INDEX NameIdx ON Customer (Name)Δημιουργεί το δείκτη NameIdx για τη στήλη Name στον πίνακα Customer.
Ένας δείκτης μπορεί να διαγραφεί με τη σύνταξη:
DROP INDEX όνομα_δείκτη ON όνομα_πίνακα
Προσθήκη στοιχείων
Προσθήκη δεδομένων σε έναν πίνακα γίνεται με την εντολή INSERT INTO σύμφωνα με τη σύνταξη:INSERT INTO όνομα_πίνακα [(πεδίο1[, πεδίο2[, ...]])] VALUES (τιμή1[, τιμή2[, ...])Παράδειγμα:
INSERT INTO Customer (Name, AccountNum) VALUES ("Papadopoulos", 1234)
Επιλογή
Επιλογή δεδομένων από έναν ή περισσότερους πίνακες γίνεται με την εντολή SELECT σύμφωνα με την παρακάτω βασική σύνταξη:SELECT πεδία FROM πίνακες [ WHERE κριτήρια ]Απλό παράδειγμα:
SELECT Name, AccountNum FROM Customer WHERE Name LIKE "Pap*"
Τα πεδία μπορούν να είναι ονόματα πεδίων ή συγκεντρωτικές συναρτήσεις της SQL πάνω σε πεδία. Τέτοιες συναρτήσεις είναι οι παρακάτω:
- Avg
- Μέσος όρος
- Count
- Μέτρηση
- Min
- Ελάχιστο
- Max
- Μέγιστο
- Sum
- Σύνολο
SELECT Sum(AccountBalance) FROM CustomerΟ αστερίσκος ως ορισμός πεδίου επιλέγει όλα τα πεδία.
Τα κριτήρια αναζήτησης είναι εκφράσεις πάνω στα πεδία. Ορισμένοι βασικοί τελεστές είναι οι:
- αριθμητικοί + - * / mod
- σύγκρισης < <= > >> = <> like
- λογικοί and or not
SELECT * FROM Customer WHERE Balance > 10000 AND Name LIKE "Papad*"
Βασικό στοιχείο του σχεσιακού μοντέλου είναι η αποθήκευση δεδομένων σε πίνακες που σχετίζονται μεταξύ τους. Έτσι για παράδειγμα ένας πίνακας μπορεί να φυλάει τα στοιχεία των πελατών και ένας άλλος τους λογαριασμούς. Με τον τρόπο αυτό τα στοιχεία ενός πελάτη που έχει πολλούς λογαριασμούς σε μια τράπεζα φυλάσσονται μόνο μια φορά. Ανάκτηση από δύο τέτοιους πίνακες γίνεται με τον προσδιορισμό τους στο SELECT μαζί με τη χρήση της κατάλληλης έκφρασης που θα ενώσει τους πίνακες. Παράδειγμα:
SELECT Customer, Balance FROM Customers, Accounts WHERE Customer.AccountId = Accounts.AccountId
Αλλαγή
Αλλαγή σε στοιχεία γίνεται με την εντολή UPDATE σύμφωνα με τη σύνταξη:UPDATE όνομα_πίνακα SET πεδίο = νέα_τιμή WHERE κριτήρια;Παράδειγμα:
UPDATE Accounts SET Balance=100000 WHERE AccountId = 12233
Διαγραφή
Διαγραφή γραμμών από έναν πίνακα γίνεται με την εντολή DELETE σύμφωνα με τη σύνταξη:DELETE FROM όνομα_πίνακα WHERE κριτήριαΠαράδειγμα:
DELETE FROM Accounts WHERE AccountId = 123232
SQL στη Microsoft Access
Για να δώσουμε εντολές SQL στη Microsoft Access ακολουθούμε την παρακάτω διαδικασία:- Δημιουργούμε μια κενή βάση δεδομένων
- View - Database objects - Queries
- New - Design view
- Show table - close
- View - SQL
- Γράφουμε την εντολή SQL που θέλουμε
- Query - Run
Βιβλιογραφία
- D. D. Chamberlin, M. M. Astrahan, K. P. Eswaran, P. P. Griffiths, R. A. Lorie, J. W. Mehl, P. Reisner, and B. W. Wade. SEQUEL 2: A unified approach to data definition manipulation and control. IBM Journal of Research and Development, 20(6):560–575, November 1976.
- Peter Pin-Shan Chen. The entity-relationship model — toward a unified view of data. ACM Transactions on Database Systems, 1(1):9–36, March 1976.
- International Organization for Standardization, Geneva, Switzerland. Information technology — Database languages — SQL, 1992. ISO/IEC 9075:1992.
- Henry F. Korth and Abraham Silberschatz. Database System Concepts. McGraw-Hill, second edition, 1991.
Ασκήσεις
Άσκηση 10 (προαιρετική)
- Ορίστε με βάση SQL έναν τηλεφωνικό κατάλογο με τους φίλους σας.
- Εισάγετε μερικά ονόματα και τα τηλέφωνα
- Ανακτήστε ένα τηλέφωνο με τον τελεστή LIKE
- Μετρήστε τον αριθμό των φίλων σας με την έκφραση Count
Συναρτησιακός προγραμματισμός στη Lisp
Συναρτησιακός προγραμματισμός και η γλώσσα Lisp
Ο συναρτησιακός προγραμματισμός (functional programming) βασίζεται στην αποτίμηση συναρτήσεων αντί για την εκτέλεση εντολών. Προγράμματα βασισμένα στο συναρτησιακό προγραμματισμό είναι γραμμένα με βάση συναρτήσεις που αποτιμούν βασικές τιμές. Μια συναρτησιακή γλώσσα προγραμματισμού υποστηρίζει και ενθαρρύνει το συναρτησιακό προγραμματισμό.Βασικά χαρακτηριστικά του συναρτησιακού προγραμματισμού είναι:
- οι συναρτήσεις ως παράμετροι,
- o ράθυμος υπολογισμός (lazy evaluation),
- η αναφορική διαφάνεια (referential transparency).
Ορισμένες γνωστές συναρτησιακές γλώσσες προγραμματισμού είναι οι:
- Erlang
- Haskell
- Hope
- Lisp
- Miranda
- ML
- Scheme
Οι βασικές ιδέες της γλώσσας Lisp αναπτύχθηκαν από τον John McCarthy το 1956 σε ένα ερευνητικό πρόγραμμα για τεχνητή νοημοσύνη. Στόχος του McCarthy ήταν η ανάπτυξη μιας αλγευρικής γλώσσας επεξεργασίας λιστών για έρευνα στην τεχνητή νοημοσύνη. Ανάμεσα στα έτη 1960 και 1965 υλοποιήθηκε η διάλεκτος Lisp 1.5 η οποία τη δεκαετία του 1970 είχε οδηγήσει στις διαλέκτους MacLisp και InterLisp. Στα μέσα της δεκαετίας του 1970 οι Sussman και Steele Jr. ανέπτυξαν τη διάλεκτο Scheme με βάση ιδέες από τη σημασιολογία των γλωσσών προγραμματισμού. Στη δεκαετία του 1980 έγινε προσπάθεια για ενοποίηση των διαλέκτων της Lisp κάτω από το πρότυπο της Common Lisp.
Απλές συναρτήσεις
-
Συναρτήσεις στη Lisp ορίζονται με τη σύνταξη:
(defun όνομα_συνάρτησης (παράμετροι) τιμή)
- Υπολογισμός της τιμής μιας συνάρτησης στη Lisp γίνεται με τη σύνταξη:
(όνομα_συνάρτησης παράμετροι)
- Ορισμένες χρήσιμες συναρτήσεις είναι οι:
- (if e tv fv)
- επιστρέφει tv αν η e είναι αληθής (t) και fv αν είναι ψευδής (nil).
- (+ a b)
- επιστρέφει a + b.
- (- a b)
- επιστρέφει a - b.
- (* a b)
- επιστρέφει a * b.
- (/ a b)
- επιστρέφει a / b.
- (equal a b)
- επιστρέφει αληθές (t) αν a = b.
(defun factorial (n) (if (equal n 0) 1 (* n (factorial (- n 1)))))
Λίστες
- Στη Lisp μπορούμε να ορίσουμε μια λίστα (list) από τιμές με τη σύνταξη '(τιμή1 τιμή2 τιμή3 ...)
- Η ειδική τιμή nil παριστάνει την κενή λίστα.
- Μπορούμε να αναφερθούμε σε σύμβολα με τη σύνταξη 'όνομα.
'(1 2 3 4 42)
'word
'('Maria 'John 'Aliki)
Βασικές συναρτήσεις επεξεργασίας λιστών είναι οι παρακάτω:
- (cons val list) επιστρέφει τη λίστα list με πρώτο το στοιχείο val,
- (car list) επιστρέφει το πρώτο στοιχείο μιας λίστας,
- (cdr list) επιστρέφει τα υπόλοιπα (όλα εκτός από το πρώτο) στοιχεία μιας λίστας ή nil αν αυτά δεν υπάρχουν.
Length
Επιστρέφει το μήκος μιας λίστας.(defun mylength (a) (if (null a) 0 (+ (mylength (cdr a)) 1)))
Append
Ενώνει δύο λίστες.(defun myappend (a b) (if (null a) b (cons (car a) (myappend (cdr a) b))))
Reverse
Αντιστρέφει μια λίστα.(defun myreverse (a) (if (null a) nil (myappend (myreverse (cdr a)) (cons (car a) nil))))
Συναρτήσεις ανωτέρου βαθμού
- Μπορούμε να ορίσουμε μια συνάρτηση ανωτέρου βαθμού (higher order function) ορίζοντας ως ένα όρισμα της συνάρτησης μια άλλη συνάρτηση.
- Τη συνάρτηση-όρισμα μπορούμε να την εφαρμόσουμε πάνω σε κάποιες τιμές με τη συνάρτηση apply η οποία λαμβάνει ως όρισμα μια συνάρτηση και μια λίστα με το όρισμά της και επιστρέφει το αποτέλεσμα της συνάρτησης εφαρμοσμένο στο όρισμα αυτό.
- Μπορούμε ακόμα να ορίσουμε δυναμικά μια τιμή τύπου συνάρτησης
με τη σύνταξη:
(lambda όνομα_συνάρτησης (όρισμα) τιμή)
Map
Η συνάρτηση map μετατρέπει μια λίστα σε μια άλλη με βάση μια συνάρτηση που έχει δοθεί ως όρισμα.(defun mymap (f lst) (if (null lst) nil (cons (apply f (cons (car lst) nil)) (mymap f (cdr lst)))))Έτσι μπορούμε π.χ. να διπλασιάσουμε να στοιχεία της λίστας '(1 2 3) με την κλήση:
(mymap (lambda (x) (* 2 x)) '(1 2 3)) (2 4 6)
Reduce
Η συνάρτηση reduce συμπυκνώνει μια λίστα εφαρμόζοντας αναδρομικά τη συνάρτηση σε κάθε στοιχείο της λίστας αρχίζοντας από μια αρχική τιμή.(defun myreduce (f v lst) (if (null lst) v (apply f (cons (car lst) (cons (myreduce f v (cdr lst)) nil)))))Έτσι μπορούμε να ορίσουμε συναρτήσεις όπως τις:
- sum επιστρέφει το σύνολο των τιμών μιας λίστας
(defun mysum (lst) (myreduce '+ 0 lst))
- product επιστρέφει το γινόμενο των τιμών μιας λίστας
(defun myproduct (lst) (myreduce '* 1 lst))
- alltrue επιστρέφει αληθές αν όλες οι τιμές μιας λίστας είναι αληθείς
(defun alltrue (lst) (myreduce 'and t lst))
- anytrue επιστρέφει αληθές αν τουλάχιστον μια τιμή μιας λίστας είναι αληθής
(defun anytrue (lst) (myreduce 'or nil lst))
Μεταγλωττιστής Lisp
- Διερμηνευτή συμβατό με τα παραδείγματα των σημειώσεων μπορείτε να βρείτε εδώ.
- Τεκμηρίωση για το διερμηνευτή μπορείτε να βρείτε εδώ.
- Η πιο εύκολη διαδικασία για τη χρήση του μεταγλωττιστή είναι:
- File - Open / Load το αρχείο με τις ορισμένες συναρτήσεις
- Δοκιμή της συνάρτησης μέσα στο παράθυρο.
- Ο πηγαίος κώδικας του διερμηνευτή και υλοποιήσεις για άλλες πλατφόρμες υπάρχουν στη διεύθυνση ftp://ftp.cs.cmu.edu/user/ai/lang/lisp/impl/xlisp.
Βιβλιογραφία
- Ellis Horowitz
Βασικές αρχές γλωσσών προγραμματισμού.
Δεύτερη αμερικάνικη έκδοση.
σ. 367-398 Εκδόσεις Κλειδάριθμος, 1984.
- Harold Abelson, Gerald Jay Sussman, and Jullie Sussman. Structure and Interpretation of Computer Programs. MIT Press, 1990.
- Anthony J. Field and Peter G. Harrison. Functional Programming. Addison-Wesley, 1988.
- John Hughes. Why functional programming matters. In David A. Turner, editor, Research Topics in Functional Programming, chapter 2, pages 17–42. Addison-Wesley, 1990. Also appeared in the April 1989 issue of The Computer Journal.
- Peter H. Salus, editor. Handbook of Programming Languages, volume III: Functional and Logic Programming Languages. Macmillan Technical Publishing, 1998.
Ασκήσεις
Άσκηση 11
- Οι δύο πρώτοι αριθμοί της ακολουθίας Fibonacci είναι 0 και 1. Κάθε επόμενος αριθμός είναι το άθροισμα των δύο προηγούμενων. Γράψτε τη συνάρτηση που επιστρέφει τον νοστό αριθμό Fibonacci. (Οι αριθμοί Fibonacci απαντώνται συχνά στη φύση π.χ. στον αριθμό πετάλων των λουλουδιών και στις σπείρες από τα κουκουνάρια και τις αχιβάδες).
- Γράψτε τη συνάρτηση (member list val) που επιστρέφει αληθές αν η τιμή val περιέχεται στη λίστα list.
Κατανεμημένος προγραμματισμός
Εισαγωγή
Σημείωση
Η σημειώσεις της ενότητας αυτής έχουν γραφεί από τον υποψήφιο διδάκτορα του Τμήματος Πληροφοριακών και Επικοινωνιακών Συστημάτων του Πανεπιστημίου Αιγαίου, Κωνσταντίνο Ράπτη (mailto:krap@aegean.gr).Πριν δύο δεκαετίες, η φύση των υπολογιστικών συστημάτων εκφράζονταν με την ύπαρξη ισχυρών κεντρικών υπολογιστικών συστημάτων (mainframes) στα οποία ήταν εγκατεστημένες εφαρμογές οι οποίες μπορούσαν να προσπελαστούν από τους χρήστες μέσα από τα τερματικά του συστήματος.
Με την εμφάνιση και την ανάπτυξη των προσωπικών υπολογιστών και καθώς οι εφαρμογές άρχισαν να γίνονται ολοένα και πιο μεγάλες και σύνθετες, άρχισαν να μεταμορφώνονται από ενιαία προγράμματα σε κομμάτια ικανά να συνεργάζονται μεταξύ τους. Στην διάσπαση των εφαρμογών σε περισσότερα από ένα μέρη, συνέβαλλε η ανάπτυξη της αρχιτεκτονικής πελάτη/εξυπηρετητή (client/server) βάσει της οποίας γινόταν η υλοποίησή τους. Κατά την αρχιτεκτονική πελάτη/εξυπηρετητή, μία διεργασία καλείται πελάτης (client process) όταν αιτείται την υλοποίηση κάποιων υπηρεσιών-μεθόδων από μία διεργασία η οποία είναι ικανή να της προσφέρει τις επιθυμητές υπηρεσίες. Η τελευταία αυτή διεργασία καλείται διεργασία του εξυπηρετητή (server process).
Αργότερα με την ανάπτυξη των υπολογιστικών δικτύων τα συνθετικά μέρη των εφαρμογών, προκειμένου να υπάρξει καλύτερη και αποτελεσματικότερη εκμετάλλευση των νέων δυνατοτήτων, άρχισαν να διαμοιράζονται στους υπολογιστές του δικτύου. Με τον τρόπο αυτό αυξανόταν η απόδοση και εκμετάλλευση των πόρων του δικτύου. Αυτού του είδους οι εφαρμογές ονομάζονται κατανεμημένες εφαρμογές (distributed applications).
Η δυνατότητα διασύνδεσης, σε δίκτυα, υπολογιστικών συστημάτων διαφορετικής αρχιτεκτονικής είχε σαν αποτέλεσμα την δημιουργία ενός ανομοιογενούς υπολογιστικού περιβάλλοντος. Θα έπρεπε, λοιπόν, και οι εφαρμογές να μπορέσουν να εξελιχθούν έτσι ώστε να είναι δυνατή η λειτουργία τους σε τέτοια ετερογενή συστήματα υπολογιστών. Αυτή η εξέλιξη οδήγησε στην εμφάνιση των ετερογενών κατανεμημένων εφαρμογών (heterogeneous distributed applications).
Λογισμικό βασιμένο σε εξαρτήματα
Καθώς όμως η ανάπτυξη του υλικού (hardware) είχε ως αποτέλεσμα την δημιουργία όλο και πιο ισχυρών, ταχύτερων, μικρότερων και ταυτόχρονα φθηνότερων προϊόντων, το λογισμικό εξακολουθούσε να είναι όλο και πιο σύνθετο, πολύπλοκο και ακριβό. Για να ξεπεραστεί αυτή η αδυναμία του λογισμικού θα έπρεπε να υπάρχει η δυνατότητα κάθε νέο λογισμικό να μην είναι απαραίτητο να αναπτυχθεί από την αρχή αλλά να δίνετε η δυνατότητα να προστίθενται νέα κομμάτια λογισμικού τα οποία θα μπορούσαν άμεσα να χρησιμοποιηθούν μέσα από το λογισμικό. Αυτή η εξέλιξη οδήγησε στην ανάπτυξη της τεχνολογίας των εξαρτημάτων λογισμικού (software components technology). Η νέα αυτή τεχνολογία έχει ως σκοπό να επιτρέψει την χρησιμοποίηση κομματιών λογισμικού τα οποία θα είναι κατασκευασμένα από διαφορετικούς κατασκευαστές, θα είναι υλοποιημένα σε διαφορετικές γλώσσες προγραμματισμού και θα τρέχουν κάτω από διαφορετικά λειτουργικά συστήματα.Τεχνολογίες διαλειτουργικότητας κομματιών λογισμικού
Συνοψίζοντας τα παραπάνω, μπορούμε τα πούμε ότι τα βασικά στοιχεία που χαρακτηρίζουν ένα σύγχρονο υπολογιστικό περιβάλλον είναι τα εξής:- Η χρησιμοποίηση κατανεμημένων εφαρμογών οι οποίες βασίζονται στην τεχνολογία πελάτη/εξυπηρετητή,
- Η λειτουργία των εφαρμογών σε περιβάλλον το οποίο πιθανόν να αποτελείται από υπολογιστικά συστήματα τα οποία να βασίζονται σε διαφορετική τεχνολογία και να λειτουργούν "πάνω" σε διαφορετικά λειτουργικά συστήματα και
- Η χρησιμοποίηση εργαλείων προγραμματισμού (γλώσσες προγραμματισμού) τα οποία βασίζονται στην τεχνολογία του αντικειμένου.
Τρία είναι τα βασικά μοντέλα των οποίων σκοπός είναι η υλοποίηση των παραπάνω και αυτά είναι:
- Η "CORBA" (Common Object Request Broker Architecture) της Object Management Group (OMG).
- H "COM/DCOM" (Component Object Model / Distributed Component Object Model) της Microsoft.
- Η "Java RMI" (Remote Method Invocation) της Sun.
OMG CORBA
Η OMG (Object Management Group) αναπτύσσει πρότυπα βασιζόμενη στην τεχνολογία του αντικειμένου.Σύμφωνα με την αρχιτεκτονική που προτείνεται από την OMG, την OMA (Object Management Architecture), το κάθε κομμάτι λογισμικού παρουσιάζεται σαν αντικείμενο (Object).
Τα διάφορα αντικείμενα επικοινωνούν μεταξύ τους μέσω του ORB (Object Request Broker), ο οποίος αποτελεί το στοιχείο-κλειδί γι' αυτήν την επικοινωνία. Ο ORB παρέχει τους μηχανισμούς εκείνους μέσω των οποίων τα αντικείμενα κάνουν τις αιτήσεις και συλλέγουν τις αποκρίσεις.
Η CORBA (Common Object Request Broker Architecture) αποτελεί το πρότυπο της OMG για τον ORB.
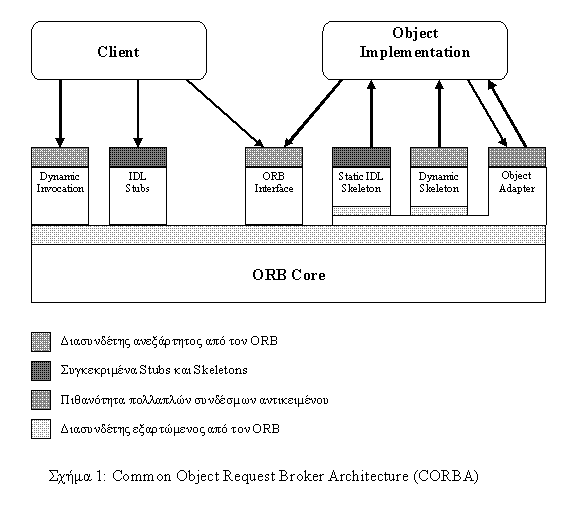
Κατά την CORBA, ένας πελάτης ο οποίος ζητάει κάποιες υπηρεσίες από κάποιο αντικείμενο, κάνει μία αίτηση (request) η οποία μεταβιβάζεται στον ORB και ο οποίος είναι στη συνέχεια υπεύθυνος για την προώθηση της αίτησης προς τον κατάλληλο εξυπηρετητή.
Η αίτηση αυτή περιέχει όλες τις απαραίτητες πληροφορίες που απαιτούνται προκειμένου να υλοποιηθεί και αυτές είναι:
- το επιθυμητό αντικείμενο,
- επιθυμητές υπηρεσίες,
- τυχόν παραμέτρους.
Για να είναι κατανοητή όμως η αίτηση θα πρέπει να έχει μία κατάλληλη μορφή και γι' αυτό το λόγο γίνεται προς τον ORB μέσω διασυνδετών (interfaces: "Dynamic Invocation" και "IDL Stubs").
Για τον ίδιο λόγο η προώθηση της αίτησης προς τον εξυπηρετητή γίνεται μέσω διασυνδετών ("Static IDL Skeleton" και "IDL Skeleton").
Ένας διασυνδέτης αποτελεί μία περιγραφή ενός συνόλου από πιθανές λειτουργίες τις οποίες ένας πελάτης μπορεί να αιτηθεί ενός αντικειμένου.
Ένα αντικείμενο ικανοποιεί έναν διασυνδέτη εάν μπορεί να προσδιοριστεί σαν το αντικείμενο-στόχος (target object) για κάθε δυνατή αίτηση η οποία περιγράφεται από τον διασυνδέτη.
Στο σημείο αυτό δεν θα πρέπει να αγνοήσουμε την ιδιότητα της κληρονομικότητας που χαρακτηρίζει τους διασυνδέτες και η οποία παρέχει τον συνθετικό εκείνο μηχανισμό που επιτρέπει σ' ένα αντικείμενο να υποστηρίζει πολλαπλούς διασυνδέτες.
Οι διασυνδέτες καθορίζονται πλήρως μέσω της OMG IDL (Interface Definition Language). Η IDL δεν αποτελεί γλώσσα προγραμματισμού, όπως οι γνωστές γλώσσες προγραμματισμού, αλλά μία καθαρά περιγραφική γλώσσα η οποία δεν περιλαμβάνει δομές αλγορίθμων ή μεταβλητές. Η γραμματική της αποτελεί υποσύνολο της ANSI C++ με πρόσθετες κατασκευές για την υποστήριξη μηχανισμών για την επίκληση απομακρυσμένων λειτουργιών.
Οι πελάτες δεν είναι "γραμμένοι" σε OMG IDL αλλά σε γλώσσα για την οποία έχει προσδιοριστεί η αντιστοιχία της με την OMG IDL.
Microsoft COM/DCOM
Το δεύτερο μοντέλο βασίζεται και αυτό στην τεχνολογία του αντικειμένου με την έννοια όμως εδώ των αυτόνομων συνθετικών εξαρτημάτων μίας εφαρμογής.
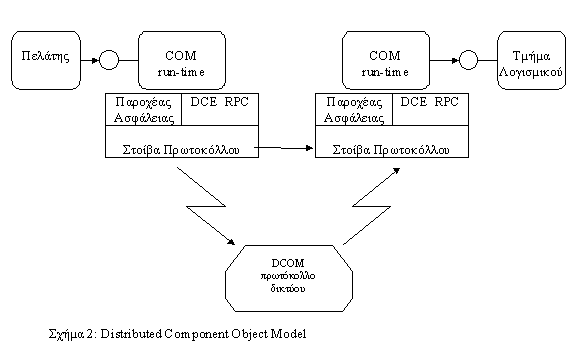
Και εδώ, ο βασικός σκοπός του μοντέλου είναι να καταστήσει δυνατή την επικοινωνία δύο ή περισσοτέρων εφαρμογών ή συνθετικών, ακόμα και στην περίπτωση που αυτά διαφέρουν ως προς την προέλευση, τη γλώσσα προγραμματισμού, τα μηχανήματα στα οποία βρίσκονται και τα λειτουργικά συστήματα κάτω από τα οποία τρέχουν.
Ο "μηχανισμός λειτουργίας του μοντέλου είναι παρόμοιος με αυτόν της CORBA. Βασικό ρόλο παίζουν οι διασυνδέτες τα οποία δεν είναι τίποτα άλλο από ένα σαφές διατυπωμένο "συμβόλαιο" μεταξύ των "κομματιών" λογισμικού, το οποίο περιέχει ένα σύνολο από σχετικές λειτουργίες. Όταν λέμε ότι ένα αντικείμενο υλοποιεί έναν διασυνδέτη αυτό σημαίνει ότι το αντικείμενο αυτό υλοποιεί κάθε λειτουργία του.
Πως γίνεται, όμως, η διαδικασία της αιτήσεως κάποιων λειτουργιών από έναν πελάτη;
Για να μπορέσει ένας πελάτης να εξυπηρετηθεί από κάποιο αντικείμενο, θα πρέπει η γλώσσα προγραμματισμού, στην οποία είναι υλοποιημένος, να έχει τη δυνατότητα δημιουργίας δεικτών και να καλεί συναρτήσεις μέσω των δεικτών. Θα πρέπει λοιπόν ο πελάτης να έχει τον κατάλληλο δείκτη προς τον επιθυμητό διασυνδέτη τον οποίο περιέχει τις επιθυμητές από τον πελάτη λειτουργίες.
Στην περίπτωση όμως που ο πελάτης δεν έχει τον κατάλληλο δείκτη προς το επιθυμητό διασυνδέτη, τότε απευθύνεται προς την COM δίνοντας σαν στοιχεία την ταυτότητα της κλάσης του εξυπηρετητή που επιθυμεί ο πελάτης και τον τύπο του, δηλαδή εάν είναι:
Η COM τότε αναλαμβάνει να βρει τον επιθυμητό εξυπηρετητή και να επιστρέψει στον πελάτη τον επιθυμητό δείκτη.Όπως έγινε σαφές, ο κάθε πελάτης μπορεί να είναι υλοποιημένος σε οποιαδήποτε γλώσσα προγραμματισμού, αρκεί αυτή να υποστηρίζει την κατασκευή και την χρήση δεικτών. Για τα "interfaces", όμως, υπάρχει και εδώ μία "IDL" (interface Definition Language) η οποία επιτρέπει και βοηθάει τους σχεδιαστές να κατασκευάζουν διασυνδέτες.
Sun Java RMI
Το μοντέλο RMI της Sun, βασίζεται και αυτό στην τεχνολογία του αντικειμένου και είναι σχεδιασμένο για να προάγει την διαλειτουργικότητα μεταξύ αντικειμένων, κατασκευασμένων σε Java, μέσα σε ένα κατανεμημένο και ετερογενές περιβάλλον.Η τεχνολογία RMI αφορά αποκλειστικά αντικείμενα τα οποία είναι κατασκευασμένα με τη γλώσσα προγραμματισμού Java. Αυτό έχει ως αποτέλεσμα να δίνει την δυνατότητα της πλήρους εκμετάλλευσης των δυνατοτήτων της Java αλλά και το πλεονέκτημα του ομοιογενούς, ως προς τη γλώσσα προγραμματισμού, περιβάλλοντος.
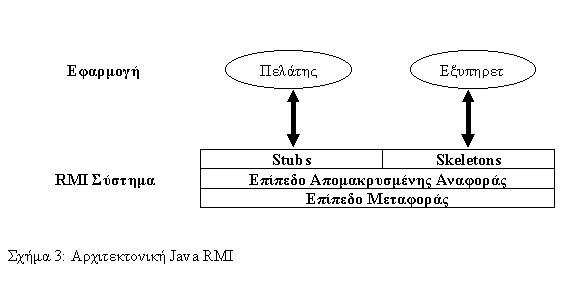
Η αρχιτεκτονική ενός RMI συστήματος ακολουθεί την δομή των στρωμάτων-επιπέδων (layers). Υπάρχουν τρία (συν ένα) επίπεδα:
- Το επίπεδο "Stub/Skeleton".
- Το επίπεδο απομακρυσμένης αναφοράς (Remote Reference).
- Το επίπεδο μεταφοράς (Transport)
Η διαδικασία επίκλησης κάποιων υπηρεσιών από έναν πελάτη, δεν διαφέρει, ιδιαίτερα, σε σχέση με τις προαναφερθείσες τεχνολογίες. Ένας πελάτης, ο οποίος επιθυμεί την υλοποίηση κάποιων υπηρεσιών, υποβάλλει μία αίτηση προς το RMI-σύστημα. Στην αίτηση αυτή θα πρέπει να αναφέρονται οι κατάλληλες εκείνες πληροφορίες οι οποίες απαιτούνται για την αποστολή της αίτησης προς τον κατάλληλο εξυπηρετητή. Αυτές οι πληροφορίες-παράμετροι είναι: μία αναφορά του επιθυμητού αντικειμένου (object reference), οι επιθυμητές μέθοδοι και οι κατάλληλες παράμετροι για την υλοποίηση των μεθόδων.
Από τη στιγμή που ο πελάτης καταθέσει την αίτησή του, το RMI-σύστημα είναι υπεύθυνο για την ανεύρεση του κατάλληλου εξυπηρετητή, την μεταβίβαση της αιτήσεων και την επιστροφή των αποτελεσμάτων στον πελάτη.
Όμοια με την CORBA και την COM/DCOM, σε ένα RMI-σύστημα, οι πελάτες δεν έρχονται ποτέ σε απευθείας επικοινωνία με τα επιθυμητά αντικείμενα παρά μόνο μέσω των διασυνδετών αυτών των αντικειμένων. Και εδώ ο διασυνδέτης είναι αυτός που περιέχει τις μεθόδους-υπηρεσίες τις οποίες μπορεί να υλοποιήσει το αντικείμενο.
Η επικοινωνία πελάτη-αντικειμένου, σΤ ένα σύστημα RMI, είναι η ίδια ανεξάρτητα με το που βρίσκεται το επιθυμητό αντικείμενο (αν δηλαδή βρίσκεται στην ίδια διεργασία με τον πελάτη, αν βρίσκεται τοπικά ή απομακρυσμένα).
Πηγές για έρευνα στο Internet
- Object Management Group, Inc., http://www.omg.org (http://www.omg.org)
- Microsoft Corporation, http://www.microsoft.com (http://www.microsoft.com)
- Sun Microsystems, Inc., http://java.sun.com (http://java.sun.com)
Βιβλιογραφία
- M. Ben-Ari. Principles of Concurrent and Distributed Programming. Prentice-Hall, 1990.
- Peter Duchessi and InduShobha Chengalur-Smith. Client/server benefits, problems, best practices. Communications of the ACM, 41(5):87–94, May 1998.
- David Flanagan. Java in a Nutshell. O'Reilly and Associates, Sebastopol, CA, USA, 1997.
- Scott M. Lewandowski. Frameworks for component-based client/server computing. ACM Computing Surveys, 30(1):3–27, March 1998.
- Sape Mullender, editor. Distributed Systems. Addison-Wesley, 1989.
- Oscar Nierstrasz, Simon Gibbs, and Dennis Tsichritzis. Component-oriented software development. Communications of the ACM, 35(9):160–165, September 1992.
- Jeffrey M. Voas. The challenges of using COTS software in component-based development. Computer, 31(6):44–45, June 1998.
Κατηγορήματα στην Prolog
Εισαγωγή
Η προστακτικές γλώσσες προγραμματισμού όπως η Fortran, η Pascal και η C έχουν κατασκευαστεί και να διευκολύνουν τον προγραμματισμό υπολογιστών αρχιτεκτονικής von Neumann (επεξεργαστής που εκτελεί κώδικα και επεξεργάζεται δεδομένα από τη μνήμη). Ιστορικά, ο στόχος για το σχεδιασμό των γλωσσών αυτών είναι να γίνει ο προγραμματισμός του υπολογιστή προσιτός στον άνθρωπο. Έτσι, η διαδικασία της λύσης ενός προβλήματος με υπολογιστή εμφανίζεται διχοτομημένη ανάμεσα στην ανάλυση του προβλήματος και, στη συνέχεια, την κωδικοποίησή του σε υπολογιστή.Η εξέλιξη της ισχύος των υπολογιστών και του αντίστοιχου θεωρητικού υπόβαθρου μας έχει επιτρέψει να εξετάζουμε διαφορετικές προσεγγίσεις επίλυσης προβλημάτων με υπολογιστή που να βασίζονται όχι στο να κάνουν την αρχιτεκτονική του υπολογιστή προσιτή στον άνθρωπο, αλλά στο να κάνουν τη διατύπωση των προβλημάτων από τον άνθρωπο προσιτή στον υπολογιστή. Έτσι, τόσο ο συναρτησιακός όσο και ο λογικός προγραμματισμός επιτρέπουν τη διατύπωση του προβλήματος που πρέπει να επιλυθεί με βάση έναν συμβολισμό και αφήνουν στον υπολογιστή να λύσει το πρόβλημα με βάση τη διατύπωσή του. Η βάση του λογικού προγραμματισμού μπορεί να διατυπωθεί ως εξής:
- πρόγραμμα = σύνολο από αξιώματα
- υπολογισμός = απόδειξη του στόχου με βάση το πρόγραμμα
- αλγόριθμος = λογική + έλεγχος
- J. Robinson (1965)
- Διατύπωση του αλγόριθμου της ταυτοποίησης (unification). Ο αλγόριθμος αυτός βρίσκει ένα σύνολο από στοιχειώδεις αντικαταστάσεις σε μεταβλητές για να καταστήσει δύο όρους ταυτόσημους.
- R. Kowalski (1974)
- Διαδικασιακή ερμηνεία προτάσεων Horn. Προτάσεις της μορφής Α αν Β1 και Β2 και ... Βν μπορούν να ερμηνευτούν διαδικασιακά ως: για να ισχύει το Α, πρέπει να ισχύει το Β1 και το Β2 και ... το Βν.
- A. Colmerauer (1973)
- Υλοποίηση διερμηνευτή της Prolog σε Fortran.
- D. Warren (1977
- Υλοποίηση μεταγλωττιστή της Prolog (σε ενδιάμεση γλώσσα την Warren Abstract Machine).
- Ιαπωνία (1981)
- Πρόγραμμα υπολογιστών πέμπτης γενιάς.
Έδωσε ώθηση στην Prolog υιοθετώντας το λογικό προγραμματισμό
ως βασική τεχνολογία του προγράμματος.
Σχέσεις
Η βάση της Prolog είναι τα γεγονότα (facts), οι κανόνες (rules) και οι ερωτήσεις (queries). Υπάρχει μόνο μια δομή δεδομένων, ο όρος (term). Τα γεγονότα ορίζουν μια αληθή σχέση ανάμεσα σε αντικείμενα.Παράδειγμα 1 (ορισμός σχέσεων ανάμεσα σε ακέραιούς):
sum(0, 0, 0). sum(0, 1, 1). sum(1, 0, 1). sum(1, 1, 2).
Παράδειγμα 2 (ορισμός σχέσεων ανάμεσα σε ανθρώπους):
father(anthi, giannis). father(petros, giannis). father(thanasis, giannis). father(iro, giannis). father(nikos, thanasis). father(giorgos, thanasis). mother(anthi, maria).
Οι λέξεις nikos, petros, anthi, στο παραπάνω παράδειγμα είναι σταθερές της γλώσσας (όπως και οι ακέραιοι στο προηγούμενο). Ονομάζονται άτομα (atoms) και γράφονται με αρχικό μικρό γράμμα.Με βάση τα παραπάνω γεγονότα μπορούμε να εκτελέσουμε ερωτήσεις για να μάθουμε αν μια σχέση είναι αληθής ή ψευδής. Όταν η Arity Prolog βρει μια αληθή λύση στην ερώτησή μας μας εμφανίζει το σύμβολο ->. Στο σημείο εκείνο μπορούμε να πατήσουμε Enter για να δηλώσουμε πως μας ικανοποιεί η λύση, ή ; για να δηλώσουμε πως θέλουμε να δούμε και άλλες λύσεις. Παράδειγμα:
?- sum(0, 0, 0). -> yes ?- sum(1, 1, 2). -> yes ?- sum(1, 1, 0). no ?- sum(5, 3, 9). no
Λογικές μεταβλητές
Ερωτήσεις με μεταβλητές
Οι λογικές μεταβλητές στην Prolog (γράφονται με αρχικό κεφαλαίο γράμμα) μπορούν να χρησιμοποιηθούν για να τεθούν ερωτήσεις για να μάθουμε κάποιο στοιχείο από τα γεγονότα που έχουμε ορίσει. Παράδειγμα:?- sum(1, 1, X). X = 2 yes ?- sum(X, 1, X). no ?- sum(X, X, 2). X = 1 yes ?- father(iro, X). X = giannis yes ?- father(X, Y). X = anthi Y = giannis ->; X = petros Y = giannis ->; X = thanasis Y = giannis ->; X = iro Y = giannis ->; X = nikos Y = thanasis -> yes
Γεγονότα με μεταβλητές
Με βάση τις μεταβλητές μπορούμε ακόμα να ορίσουμε και γενικευμένα γεγονότα (universal facts). Για παράδειγμα για να ορίσουμε πως όλοι αγαπούν τη Μαίρη γράφουμε:
loves(X, mairi).
Όροι
Με βάση τα παραπάνω μπορούμε να ορίσουμε τη δομή δεδομένων της Prolog, τον όρο. Οι όροι ορίζονται αναδρομικά. Ένας όρος μπορεί να είναι:
- σταθερά, δηλαδή άτομο ή αριθμός
- μεταβλητή
- άτομο(όρος1, ... όρος_ν)
sum(0, 0, 1) car(color(red), engine(1600), abs, speed(172), doors(2,2,1)) loves(X, Y)
Σύζευξη
Μπορούμε να ενώσουμε ερωτήσεις μεταξύ τους με το κόμμα (,) για να απαιτήσουμε να είναι και οι δύο αληθείς:?- sum(0, 1, 1), sum(1, 1, 2). yes ?- sum(0, 1, 1), sum(1, 1, 3). no
Μπορούμε να ορίσουμε ακόμα κανόνες με βάση ένα γεγονός και κάποιες σχετικές ερωτήσεις με την παρακάτω σύνταξη:a :- b1, b2, bn.
Ο κανόνας διαβάζεται ως εξής: ισχύει το a αν ισχύει το b1 και το b2 και το bn. Αν ορίσουμε παραπάνω από έναν κανόνα για το ίδιο γεγονός τότε οι κανόνες ισχύουν διαζευκτικά (αρκεί να ισχύει ένας).Παράδειγμα:
parent(X, Y) :- father(X, Y). parent(X, Y) :- mother(X, Y). ?- parent(anthi, X). X = giannis ->; X = maria yes ?- parent(X, giannis). X = anthi ->; X = petros ->; X = thanasis ->; X = iro ->; noΠαράδειγμα:
grandfather(X, Y) :- father(Z, X), father(Y, Z). ?- grandfather(X, Y). X = giannis Y = nikos ->; X = giannis Y = giorgos ->; noΑριθμητική με αναδρομή
Με βάση τον αναδρομικό ορισμό των ακεραίων μπορούμε να τους ορίσουμε αξιωματικά και στην Prolog. Ορίζουμε τον όρο s(X) να παριστάνει τον επόμενο ακέραιο από το X. Έτσι, ορίζοντας το 0 το 1 είναι s(0), το 2 είναι s(s(0)), κ.λπ. Ο κανόνας nat ορίζει τους ακέραιους αριθμούς. Μπορούμε με επαγωγή να αποδείξουμε πως όλοι οι ακέραιοι παράγονται και αναγνωρίζονται από τον nat.nat(0). nat(s(X)) :- nat(X). ?- nat(0). yes ?- nat(s(0)). yes ?- nat(s(s(s(s(0))))). yes ?- nat(X). X = 0 ->; X = s(0) ->; X = s(s(0)) ->; X = s(s(s(0))) ->; X = s(s(s(s(0)))) -> X = s(s(s(s(s(0))))) ->; X = s(s(s(s(s(s(0)))))) ->; X = s(s(s(s(s(s(s(0))))))) ->; X = s(s(s(s(s(s(s(s(0)))))))) ->; X = s(s(s(s(s(s(s(s(s(0))))))))) ->; X = s(s(s(s(s(s(s(s(s(s(0)))))))))) -> ...
Με βάση τον ορισμό αυτό μπορούμε να ορίσουμε μια σχέση διάταξης:less(0, X) :- nat(X). less(s(X), s(Y)) :- less(X, Y). ?- less(s(0), 0). no ?- less(s(0), s(s(0))). yes ?- less(X, s(s(s(s(0))))). X = 0 ->; X = s(0) ->; X = s(s(0)) ->; X = s(s(s(0))) ->; X = s(s(s(s(0)))) ->; no
Με παρόμοιο τρόπο μπορούμε να ορίσουμε και την πρόσθεση:plus(0, X, X) :- nat(X). plus(s(X), Y, s(Z)) :- plus(X, Y, Z).
Είναι αξιοσημείωτο πως το κατηγόρημα της πρόσθεσης με τη μορφή που έχει οριστεί μπορεί να υπολογίσει άθροισμα, διαφορά, όρους που δημιουργούν ένα άθροισμα, ή να ελέγξει αν ένα άθροισμα είναι αληθές:?- plus(s(0), s(0), X). X = s(s(0)) yes ?- plus(s(0), X, s(s(s(0)))). X = s(s(0)) yes ?- plus(X, Y, s(s(0))). X = 0 Y = s(s(0)) ->; X = s(0) Y = s(0) ->; X = s(s(0)) Y = 0 ->; no ?- plus(s(0), 0, 0). no
Με τη χρήση του αθροίσματος μπορούμε να ορίσουμε και το γινόμενο:times(0, X, 0) times(s(X), Y, Z) :- times(X, Y, W), plus(W, Y, Z).
Το κατηγόρημα για το γινόμενο που έχει οριστεί με τον τρόπο αυτό έχει και αυτό παρόμοια ευελιξία:?- times(s(s(0)), s(s(s(0))), X). X = s(s(s(s(s(s(0)))))) yes ?- times(X, s(s(0)), s(s(s(s(0))))). X = s(s(0)) ->. yes ?- times(X, Y, s(s(s(s(0))))). X = s(0) Y = s(s(s(s(0)))) ->; X = s(s(0)) Y = s(s(0)) ->; ?- times(s(0), s(0), s(0)). yes
Υπολογισμοί στην Prolog
Αν και ο παραπάνω ορισμός των ακεραίων είναι αξιοθαύμαστος για τη λιτότητα και την πληρότητά του, οι υλοποιήσεις της Prolog για υπολογισμούς αριθμών χρησιμοποιούν το κατηγόρημα is(X, Y) και την υλοποίηση των αριθμών από τον επεξεργαστή του υπολογιστή. Αυτό υπολογίζει το αποτέλεσμα της αριθμητικής έκφρασης στο Y και την ταυτοποιεί με το X. Το κατηγόρημα αυτό είναι μεν αποδοτικό, δε συμπεριφέρεται όμως με την ευελιξία που δείξαμε στα παραπάνω παραδείγματα. Παράδειγμα:?- is(X, 1 + 2). X = 3 ?- is(2, 1 + 1). yes ?- is(Y, 3 * 8 + 4 / 5). Y = 24.8 yes ?- is(2, X + X). no
Λίστες
Οι λίστες στην Prolog ορίζονται με τη σύνταξη [Head | Tail] όπου Head είναι το στοιχείο που αποτελεί την κεφαλή της λίστας και Tail τα υπόλοιπα στοιχεία. Η σύνταξη αυτή αποτελεί απλώς συντομογραφία για όρους των οποίων το όνομα είναι η τελεία (.). Με βάση τον ορισμό των λιστών μπορούμε πολύ εύκολα να ορίσουμε σύνθετους αλγόριθμους όπως την ταξινόμηση quick sort:quicksort([X|Xs], Ys) :- partition(Xs, X, L, B), quicksort(L, Ls), quicksort(B, Bs), append(Ls, [X | Bs], Ys). quicksort([], []). partition([X|Xs], Y, [X|Ls], Bs) :- X =< Y, partition(Xs, Y, Ls, Bs). partition([X|Xs], Y, Ls, [X|Bs]) :- X > Y, partition(Xs, Y, Ls, Bs). partition([], Y, [], []). append([], X, X). append([H | T], X, [H | Z]) :- append(T, X, Z). ?- quicksort([4,2,8,12,1,7], X). X = [1,2,4,7,8,12] ->. yesΣυμβολική επεξεργασία
Με βάση μεταβλητές και όρους μπορούμε να γράψουμε ένα πρόγραμμα που να αναγνωρίζει πολυώνυμα ορισμένα με τον παρακάτω τρόπο:- sum(A, B) (άθροισμα)
- diff(A, B) (διαφορά)
- prod(A, B) (γινόμενο)
- quot(A, B) (πηλίκο)
- pow(A, B) (ύψωση σε δύναμη)
- τη μεταβλητή X
- καθώς και ακεραίους.
polynomial(X, X). polynomial(N, X) :- number(N). polynomial(sum(A, B), X) :- polynomial(A, X), polynomial(B, X). polynomial(diff(A, B), X) :- polynomial(A, X), polynomial(B, X). polynomial(prod(A, B), X) :- polynomial(A, X), polynomial(B, X). polynomial(quot(A, B), X) :- polynomial(A, X), number(B). polynomial(pow(A, B), X) :- polynomial(A, X), integer(B).Ερωτήσεις:?- p(sum(x, 1), x). ->. yes ?- p(sum(x, 1), y). no ?- polynomial(sum(prod(5,pow(x, 2)), prod(2, x)), x). ->. yes ?- polynomial(sum(prod(5,pow(x, 2)), pow(y, 3)), x). no ?- polynomial(sum(prod(5,pow(x, 2.1)), prod(2, x)), x). no
Σύντομες οδηγίες για τη χρήση της Arity Prolog
- Αντιγράφετε τα αρχεία c:\apps\arity\bin\dos\ari σε έναν δικό σας κατάλογο (κάτω από το home σας).
- Τρέχετε την εντολή api.
- Στο ?- που εμφανίζεται μπορείτε να πληκτρολογήσετε ερωτήσεις.
- Για να πληκτρολογήσετε κανόνες πατάτε Switch (ALT-S) και γράφετε τους κανόνες που θέλετε στο διορθωτή που εμφανίζεται.
- Πριν βγείτε από το διορθωτή βεβαιωθείτε πως η εντολή Buffers - Reconsult on exit είναι ενεργοποιημένη (ALT-B ALT-C).
- Για να βγείτε από το διορθωτή επιλέγετε πάλι Switch (ALT-S).
- Το αρχείο κειμένου arity.hlp περιέχει στοιχεία για όλα τα ορισμένα από την Arity Prolog κατηγορήματα.
Βιβλιογραφία
- Μ. Κατζουράκη, Μ. Γεργατσούλης και Σ. Κόκκοτος
PROγραμματίζοντας στη LOGική.
Εκδόσεις Νέων Τεχνολογιών, 1991.
- Christopher John Hogger. Introduction to Logic Programming. Academic Press, 1984.
- Robert Kowalski. Predicate logic as programming language. In Jack L. Rosenfeld, editor, Information Processing 74, Proceedings of IFIP congress 74, pages 569–574, Stockholm, Sweden, August 1974. International Federation of Information Processing, North-Holland.
- Robert Kowalski. Logic as a computer language. In Keith L. Clark and Sten-Åke Tärnlund, editors, Logic Programming, pages 3–16. Academic Press, 1982.
- Francis G. McCabe. Logic and Objects. Prentice Hall, 1992.
- Richard A. O'Keefe. The Craft of Prolog. MIT Press, 1990.
- Uday S. Reddy. On the relationship between logic and functional languages. In Doug DeGroot and Gary Lindstrom, editors, Logic Programming, Functions, Relations and Equations, pages 3–36. Prentice Hall, Englewood Cliffs, NJ, USA, 1986.
- J. A. Robinson. A machine-oriented logic based on the resolution principle. Journal of the ACM, 12(1):23–41, January 1965.
- Peter H. Salus, editor. Handbook of Programming Languages, volume III: Functional and Logic Programming Languages. Macmillan Technical Publishing, 1998.
- Leon Sterling and Ehud Shapiro. The Art of Prolog. MIT Press, 1986.
- David H. D. Warren. An abstract Prolog instruction set. Technical Note 309, SRI International, Artificial Intelligence Center, Computer Science and Technology Division, 333 Ravenswood Ave., Menlo Park, CA, USA, October 1983.
Ασκήσεις
Άσκηση (προαιρετική)
-
Ορίστε σε Prolog το κατηγόρημα
polynomial_value(P, X, V).
όπου:- Pείναι ένα πολυώνυμο ορισμένο με βάση τους όρους:
- sum(A, B) (άθροισμα)
- diff(A, B) (διαφορά)
- prod(A, B) (γινόμενο)
- pow(A, B) (ύψωση σε δύναμη)
- τη μεταβλητή x (προσοχή, μικρό γράμμα)
- καθώς και ακεραίους.
- X η τιμή της μεταβλητής x
- V η τιμή του πολυωνύμου.
- Pείναι ένα πολυώνυμο ορισμένο με βάση τους όρους:
Παράδειγμα:
?- polynomial_value(prod(5, pow(x, 3)), 3, X). X = 135 -> yes ?- polynomial_value(sum(prod(5, pow(x, 3)), prod(x, 5)), 4, X). X = 340 ->. yesΤην ύψωση ενός αριθμού σε δύναμη μπορείτε να την ορίσετε ως εξής:
raise(X, 0, 1).
raise(X, N, Y) :-
N2 is N - 1,
raise(X, N2, K),
Y is K * X.